


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
EEG SIGNAL DECODING FOR INTELLIGENT TUTORING SYSTEMS: A REVIEW OF APPROACHES AND THE “NEUROTUTOR” CONCEPTUAL ARCHITECTURE

Введение
Интеллектуальные обучающие системы обеспечивают адаптацию учебного контента к когнитивному профилю обучающегося, персонализированную обратную связь и управление темпом освоения материала [1, 2]. Вместе с тем применение таких систем ограничено для лиц с тяжелыми двигательными нарушениями – боковым амиотрофическим склерозом, детским церебральным параличом, последствиями инсульта, синдромом запертого человека, – поскольку все существующие системы предполагают использование стандартных устройств ввода: клавиатуры, манипулятора или систем отслеживания взгляда. По данным ВОЗ, более 70 млн чел. в мире страдают заболеваниями, существенно ограничивающими моторные функции [3]; при наиболее тяжелых формах нарушений подвижность взгляда также утрачена, что полностью исключает пациента из процесса электронного обучения.
Интерфейсы мозг – компьютер транслируют электрическую активность нейронов непосредственно в управляющие команды, минуя нервно-мышечный аппарат [3]. Среди неинвазивных методов регистрации наиболее практичной с клинической точки зрения является электроэнцефалография: метод обеспечивает миллисекундное временно́е разрешение, не требует хирургического вмешательства, относительно недорог и допускает портативное применение в отличие от функциональной магнитно-резонансной томографии.
Развитие больших языковых моделей – Llama 2 [4], семейства GPT и их аналогов – открыло возможность генерации семантически связного текста из компактных векторных представлений. Сочетание декодирования электроэнцефалограммы с генеративными большими языковыми моделями представляет перспективный подход к созданию безмоторного канала коммуникации для пользователей интеллектуальных обучающих систем.
Цель исследования – систематизировать существующие подходы к декодированию сигналов электроэнцефалографии в текст на основе глубоких нейронных сетей и сформулировать архитектурные принципы системы «НейроТьютор» – пайплайна интерфейса мозг – компьютер, интегрированного с интеллектуальной обучающей системой.
В статье представлены: (1) сравнительный анализ современных архитектур декодирования электроэнцефалограммы в текст; (2) формальная спецификация четырехмодульной архитектуры предлагаемой системы; (3) аналитическое обоснование вычислительной сложности и достижимости целевых задержек; (4) трехфазная программа верификации.
Материалы и методы исследования
Настоящий обзор выполнен в соответствии с принципами систематического анализа литературы. Поиск осуществлялся в базах данных IEEE Xplore, ACL Anthology, PubMed и Google Scholar, преимущественно за период с 2018 по 2026 г. (включая фундаментальные работы более раннего периода). Поисковые запросы формировались на основе ключевых терминов: EEG-to-text decoding, brain-computer interface, intelligent tutoring system, neural signal decoding, BCI education, conformer EEG, contrastive EEG-language alignment.
Критерии включения публикаций: (1) рецензируемые научные статьи или препринты с рецензированием; (2) явная ориентация на декодирование нейросигналов в текстовую или семантическую форму; (3) использование электроэнцефалографии как основной или сопоставляемой модальности; (4) количественная оценка качества с помощью стандартных метрик (BLEU, ROUGE, WER, CER). Дополнительно включены работы по смежным областям: интеллектуальные обучающие системы с онтологическим компонентом, нейроэтика и защита данных, методологические основы инклюзивного образования.
В результате первичного отбора было идентифицировано 87 публикаций; после применения критериев включения и исключения дубликатов сформирован корпус из 27 работ, непосредственно задействованных в настоящем обзоре.
Результаты исследования и их обсуждение
1. Эволюция парадигм декодирования электроэнцефалограммы
Первые системы декодирования электроэнцефалограммы в семантические категории (начало 2010-х гг.) опирались на ручное проектирование признаков и линейные классификаторы [3]. Примером такого подхода служит BCI2000 – универсальная исследовательская платформа, предложенная Г. Шалком и соавт. в 2004 г. и до сих пор служащая эталонной инфраструктурой для широкого круга парадигм интерфейса мозг–компьютер [5]. Системы этого поколения работали с закрытым словарем (несколько десятков команд) и не позволяли генерировать произвольный текст.
В 2017–2021 гг. в исследованиях начали применяться рекуррентные и сверточные нейронные сети; задача оставалась закрытой – классификация слов или слогов из фиксированного набора. Существенным методологическим достижением этого периода стало создание корпуса ZuCo (Zurich Cognitive Language Processing Corpus): первого общедоступного корпуса, совмещающего сигналы электроэнцефалографии высокой плотности (128 каналов, 500 Гц) с данными айтрекинга, полученными при естественном чтении английских предложений [6], что создало условия для обучения декодирования с открытым словарем.
Начиная с 2022 г. доминирующим подходом является сочетание Conformer- или Transformer-энкодера с замороженными или частично дообученными большими языковыми моделями: контрастивное обучение выравнивает представления электроэнцефалограммы с текстовым пространством модели, авторегрессионный декодер генерирует связный текст. Основные архитектуры этого направления рассмотрены в разделе 2.
2. Ключевые архитектуры: сравнительный анализ
Ниже анализируются наиболее значимые системы декодирования электроэнцефалограммы в текст, выявленные в ходе обзора. На рисунке представлена предлагаемая концептуальная архитектура, разработанная в контексте данного сравнительного анализа.
DeWave (NeurIPS 2023) – первая система, реализовавшая перевод сырых волн электроэнцефалограммы без маркеров фиксации взгляда [7]. В ее основе – квантизированный вариационный энкодер (VQ-VAE), формирующий дискретный кодекс, который затем декодируется с помощью BART. Достигнутый результат на ZuCo составил BLEU-1 ≈ 40–43 %.
E2T-PTR (ACL 2024) предложила двухэтапный фреймворк: сначала обучается многоканальный авто-кодировщик CET-MAE, объединяющий контрастивное обучение между модальностями и внутримодальную самореконструкцию; затем предобученный модуль интегрируется с BART-декодером [8]. Метод превзошел базовую линию на 8,34 % по ROUGE-1 F1 и на 32,21 % по BLEU-4.
BELT-2 (ICLR 2025) – на сегодняшний день наиболее высокорезультативная система на датасете ZuCo [9]. Q-Conformer формирует многозадачное представление, которое выравнивается с подсловными единицами языка посредством контрастивного обучения. BLEU-1 достиг 52,2 % при многозадачном обучении.
BIT (Brain-to-Text) – межвидовая нейронная фундаментальная модель, переводящая нейрональную активность в связный текст через единую дифференцируемую нейросеть [10]. Transformer-энкодер предобучен на межвидовых данных инвазивных записей и интегрируется с аудио-ориентированными большими языковыми моделями, достигая WER 10,22 % в режиме сквозного обучения на Brain-to-Text Benchmark 2024.
Thought2Text использует LLaMA и Mistral, дообученные на данных электроэнцефалографии, записанных при зрительной стимуляции [11]. Подход демонстрирует принципиальную совместимость энкодера с современными инструктивно-дообученными моделями.
NeuroChat – нейроадаптивный чат-бот (система Braini), совмещающий генеративный искусственный интеллект с данными электроэнцефалографии в реальном времени для персонализации учебного диалога [12]. Система использует электроэнцефалограмму для оценки уровня вовлеченности, но не для декодирования произвольного текста – тем самым представляет смежный, а не конкурирующий подход. Z. Wang и H. Ji впервые реализовали декодирование ЭЭГ с открытым словарем и нулевой классификацией тональности (AAAI 2022) [13].
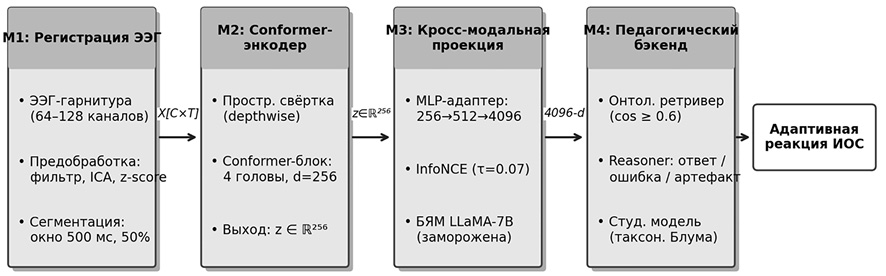
Концептуальная архитектура «НейроТьютор» Примечание: составлена авторами по результатам данного исследования
Таблица 1
Сравнение архитектур декодирования электроэнцефалограммы в текст
|
Система |
Тип энкодера |
Метод выравнивания |
Основная метрика |
BLEU-1 (ZuCo) |
Реальное время |
|
EEG-to-Text (baseline) [13] |
BERT-подобный |
MSE-регрессия |
BLEU |
~40 % |
нет |
|
DeWave [7] |
Transformer + VQ |
Дискретная квантизация |
BLEU |
~40–43 % |
нет |
|
E2T-PTR [8] |
BERT + MAE |
CEMA (контрастивный) |
BLEU, ROUGE |
~43 % |
нет |
|
BELT-2 [9] |
Q-Conformer |
BPE-контрастивный |
BLEU |
~52 % |
нет |
|
BIT [10] |
Transformer + LLM |
Cross-species pretraining |
WER |
– (ECoG) |
потенциально |
|
Thought2 Text [11] |
MLP-адаптер |
Проекция в LLM |
BLEU, BERTScore |
– |
нет |
|
НейроТьютор (предлагается) |
Conformer + MLP |
InfoNCE |
Сем. ретривал |
– |
Проектная цель |
Примечание: «–» – метрика не оценивалась по протоколу ZuCo или недоступна для прямого сравнения. Источник: составлена по данным [7–11, 13].
NeuroTutor (Elgammal et al., 2025) – система нейрокогнитивного тьюторинга, декодирующая вовлеченность студента в ходе виртуального и роботизированного обучения [14]. В отличие от предлагаемой авторами архитектуры, данная система не ставит задачу декодирования произвольного текста из сигнала электроэнцефалографии, однако подтверждает практическую применимость нейроинтерфейсов в образовательном контексте.
3. Сравнительный анализ архитектур
Базовая классификация с открытым словарем и смежные нейроадаптивные подходы представлены в работах раннего периода [12, 13]. Системы на основе квантизации, маскированного автокодирования и бутстрэпинга образуют первое поколение сквозного декодирования (табл. 1) [7–9]. Современные архитектуры с межвидовым предобучением, интерпретируемыми представлениями и инструктивно-настроенными большими языковыми моделями задают актуальный предел семантического выравнивания [10–11].
4. Общие ограничения существующих подходов
Анализ представленных систем выявляет три системных ограничения.
Когнитивный разрыв. Все системы, обученные на ZuCo (пассивное чтение), оценивались в условиях рецептивного восприятия. Генеративная задача – формулирование произвольного ответа при взаимодействии с интеллектуальной обучающей системой – требует совершенно иных нейронных паттернов, соответствующих внутренней речи. Этот разрыв до сих пор остается главным препятствием для практического применения [15].
Отсутствие реального времени. Ни одна из сравниваемых систем не продемонстрировала устойчивой работы в онлайн-режиме с задержкой, приемлемой для учебного диалога.
Изолированность от педагогического контекста. Ни одна из систем не интегрирована с интеллектуальной обучающей системой: нейроинтерфейс и педагогическая логика рассматриваются как независимые исследовательские направления.
Предлагаемая система разрабатывается как ответ на все три ограничения.
5. Концептуальная архитектура «НейроТьютор»
Предлагаемая система представляет собой концептуальный пайплайн из четырех последовательно связанных модулей, обеспечивающих путь от регистрации сигнала электроэнцефалографии до педагогически осмысленной реакции интеллектуальной обучающей системы.
5.1. Модуль 1: Непрерывная регистрация электроэнцефалограммы (M1)
Технические параметры. Регистрация выполняется с использованием 64–128 электродных систем по стандартной схеме 10–20 с полосой усиления 0,5–45 Гц и частотой дискретизации 500–1000 Гц. Нотч-фильтр 50 Гц применяется для подавления наводки промышленной сети. Целевое сопротивление электродов – менее 5 кОм.
Сегментация. Сигнал обрабатывается скользящим окном длительностью 500 мс с перекрытием 50 % (250 мс). Выбор окна обусловлен нейрофизиологическим обоснованием: большинство когнитивно значимых компонентов, связанных с языковой обработкой (N400, P600), проявляются в диапазоне 400–600 мс после стимула [6].
Предобработка. Стандартный пайплайн включает: (1) повторное выборочное преобразование к 500 Гц; (2) линейное дрейф-удаление; (3) удаление артефактов мигания методом независимого анализа компонент; (4) нормализацию z-score по каналам. Для портативных сухих электродов дополнительно применяется Common Average Reference.
Протокол M1 совместим с форматом ZuCo 2.0 (128 каналов, 500 Гц) [6] и с Inner Speech Dataset (Nieto et al., 2022, 128 каналов) [15], что обеспечивает возможность офлайн-валидации на обоих корпусах без повторной предобработки данных.
5.2. Модуль 2: Conformer-энкодер пространственно-временных признаков (M2)
Conformer сочетает сверточные слои для извлечения локальных временны́х паттернов с механизмом самовнимания для моделирования долгосрочных зависимостей. Эта архитектура была адаптирована для электроэнцефалограммы в работе BELT-2 [9], показав превосходство над чисто трансформерными и чисто сверточными подходами.
Спецификация архитектуры M2:
− Входной слой: матрица X размером [C × T], где C ∈ {64, 128} – число каналов, T – число временны́х точек в окне 500 мс.
− Пространственная свертка: depthwise separable convolution с ядром размером 25 точек вдоль временно́й оси.
− Conformer-блок: 4 головы самовнимания, d_model = 256; feed-forward подсеть с размерностью 1024, активация GELU; нормализация LayerNorm; относительное позиционное кодирование Шоу–Чиу.
− Выходное представление: вектор z ∈ R^256, получаемый усреднением по временно́й оси после последнего Conformer-блока.
Для ускорения обучения рекомендуется предобучение энкодера методом маскированного автокодирования, аналогично подходу E2T-PTR [8].
5.3. Модуль 3: Кросс-модальная проекция в пространство большой языковой модели (M3)
Задача M3 – отобразить 256-мерный вектор представления электроэнцефалограммы в пространство токенных эмбеддингов целевой большой языковой модели, сохраняя семантическую близость к соответствующему текстовому описанию.
Архитектура адаптера: трехслойный многослойный перцептрон: 256 → ReLU → 512 → ReLU → 4096. Выходная размерность 4096 соответствует пространству эмбеддингов Llama 2 (7B) [4]. При использовании других больших языковых моделей размерность последнего слоя настраивается соответственно.
Функция потерь – NT-Xent (контрастивная) [16] с температурным параметром τ = 0,07. Вектор электроэнцефалограммы одного сегмента максимизирует сходство с текстовым эмбеддингом соответствующего предложения и минимизирует – с эмбеддингами всех остальных предложений в батче.
Веса большой языковой модели заморожены в ходе обучения M3 (аналогично BELT-2 [9] и Thought2Text [11]). Только адаптер и prefix-vectors являются обучаемыми параметрами (~2M параметров суммарно).
5.4. Модуль 4: Педагогический бэкенд на основе онтологий (M4)
M4 определяет специфику предлагаемой архитектуры по сравнению с общими системами декодирования и реализует полный цикл педагогической обратной связи. Модуль опирается на трехуровневую онтологию [17, 18]: уровень концептов предметной области, таксономию Блума [19] и модель типизированных педагогических ошибок. Онтологическое моделирование в образовании также развивалось в предшествующих работах, в частности в области представления знаний по таксономии Блума [20] и верификации алгоритмических следов [21].
Механизм косинусного порога уверенности. После получения проецированного вектора из M3 онтологический ретривер вычисляет косинусное сходство между вектором и эмбеддингами всех концептов онтологии. Если косинусное сходство ≥ 0,6 → система классифицирует намерение и передает управление педагогическому движку; если ниже – активируется резервная процедура уточнения через альтернативный интерфейс.
Адаптивная педагогическая стратегия. На основании накопленной истории сессии reasoner обновляет студенческую модель – персонализированный граф концептов с атрибутами «уровень усвоения» и «история ошибок» – по принципу, аналогичному описанному в [17, 18]. Педагогический движок выбирает следующее учебное действие: объяснение на другом уровне абстракции, дополнительный пример, тест или переход к новой теме.
6. Аналитическая оценка вычислительной сложности
Ключевым практическим требованием к интерфейсу мозг–компьютер для педагогического применения является суммарная задержка – время от момента завершения сегмента электроэнцефалограммы до выдачи реакции интеллектуальной обучающей системы. Литература по психологии учебного диалога указывает, что приемлемое целевое окно составляет 500–2000 мс [12, 22]: задержка свыше 2 секунд нарушает когнитивный поток обучения. Ниже приводится поэтапный аналитический расчет задержки для развертывания на GPU уровня NVIDIA A100 (или эквивалента).
Этап 1. Предобработка сегмента электроэнцефалограммы (M1). Операции: полосовой фильтр (FIR), нормализация, упаковка тензора. При размере окна 500 мс и 128 каналах на GPU: ~5–10 мс.
Этап 2. Conformer-инференс (M2). Архитектура: 4-головое самовнимание, d = 256, 2 Conformer-блока. Число параметров: ~3M. Инференс одного окна 500 мс на GPU: ~15–20 мс (подтверждается сопоставимыми результатами для EEGNet и ShallowConvNet [23]).
Этап 3. Адаптер MLP (M3). Архитектура: 3 полносвязных слоя, суммарно ~2M параметров. На GPU: < 5 мс.
Этап 4. Авторегрессионный декодинг большой языковой моделью (M3). Llama 2 (7B) в режиме инференса генерирует ~30–50 токенов/с на GPU A100. Для педагогического ответа длиной 10–20 токенов это составляет ~200–400 мс. При использовании квантизации INT8 задержка сокращается до ~250 мс.
Этап 5. Онтологический reasoner (M4). Операции: векторный поиск в онтологии объемом ~10 000 концептов (FAISS IndexFlatIP), логический вывод (OWL reasoner). Параллельное выполнение на CPU: ~50–100 мс.
Сводная таблица задержки по компонентам (табл. 2).
Расчет демонстрирует, что суммарная задержка 270–525 мс вписывается в целевое окно 500–2000 мс при использовании квантизированной версии большой языковой модели. Доминирующим источником задержки является авторегрессионный декодинг, что мотивирует дополнительное исследование стратегий семантического ретривала и speculative decoding. В режиме семантического ретривала (без авторегрессионной генерации) суммарная задержка сокращается до ~70–130 мс.
Таблица 2
Оценка задержки компонентов «НейроТьютор»
|
Компонент |
Оценка задержки |
|
Предобработка электроэнцефалограммы (M1) |
5–10 мс |
|
Conformer-инференс (M2) |
15–20 мс |
|
Адаптер MLP (M3) |
< 5 мс |
|
Декодинг большой языковой моделью, 10–20 токенов (M3) |
200–400 мс |
|
Онтологический reasoner (M4) |
50–100 мс |
|
ИТОГО |
~270–525 мс |
Примечание: оценки для GPU NVIDIA A100; при квантизации INT8 этап декодинга сокращается до ~250 мс [9, 10, 12]. Данные об инфраструктуре воспроизводимости – по методологии MOABB-бенчмарка [23].
Составлена авторами на основе полученных данных в ходе исследования.
7. Программа верификации «НейроТьютор»
Характерной особенностью предлагаемой архитектуры является когнитивное несоответствие между имеющимися обучающими данными (рецептивные задачи чтения) и целевым применением (генеративный ответ обучающегося). Это несоответствие представляет собой обоснованную двухэтапную исследовательскую программу, в которой валидация постепенно нарастает по сложности и экологической валидности.
Фаза 1: Офлайн-валидация на корпусе ZuCo (рецептивные задачи)
Цель: оценить способность Conformer-энкодера и адаптера сформировать семантически информативные представления при рецептивном чтении. Данные: ZuCo 2.0 [6] – 18 испытуемых, 739 предложений, 128 каналов, 500 Гц. Ожидаемый результат: точность top-5 ≥ 30 % при семантическом ретривале.
Фаза 2: Офлайн-валидация на датасетах воображаемой речи
Цель: перейти от рецептивных к генеративным нейронным паттернам. Данные: Inner Speech Dataset [15] – 10 испытуемых, более 5600 проб, 128 каналов; MOABB-совместимые датасеты моторного воображения [23, 24]. Ожидаемый результат: значимое превышение случайного базиса при классификации семантических категорий (p < 0,05 по критерию Вилкоксона).
Фаза 3: Пилотное испытание в онлайн-режиме
Цель: первичная экологическая валидация в сценарии учебного взаимодействия. Участники: n = 5–10, включая здоровых добровольцев и, при наличии этического одобрения, участников с ограниченными двигательными возможностями. Оборудование: сухая электродная гарнитура (EMOTIV EPOC+, OpenBCI или аналог). Метрики: точность распознавания намерения, среднее время отклика, субъективная оценка нагрузки (NASA-TLX).
8. Этические ограничения
Применение интерфейса мозг – компьютер в образовательном контексте сопряжено с рядом этических ограничений. Записи электроэнцефалограммы квалифицируются как биометрические персональные данные (ФЗ-152, GDPR ст. 9), что требует минимизации хранимых сырых сигналов, явного отзывного согласия и, при необходимости, федеративного обучения [25]. Декодирующая система не должна принимать необратимых педагогических решений без явного подтверждения: принцип «нейронной автономии» [26] реализуется в предлагаемой системе через двухуровневую процедуру подтверждения при косинусном сходстве ниже порогового значения. Привлечение участников с тяжелыми нарушениями коммуникации требует участия законного представителя и поэтапного протокола согласия с правом выхода.
Заключение
В настоящей статье представлен концептуальный обзор и архитектурные принципы системы «НейроТьютор» – первого предложенного пайплайна, интегрирующего неинвазивное декодирование электроэнцефалограммы с интеллектуальной обучающей системой для обеспечения инклюзивного доступа к персонализированному образованию.
Выполненный сравнительный анализ существующих архитектур декодирования (DeWave, E2T-PTR, BELT-2, BIT, Thought2Text) выявил, что область достигла достаточного уровня зрелости по метрикам семантического качества (BLEU-1 до 52 % на ZuCo), однако ни одна из систем не интегрирована с педагогическим контекстом и не демонстрирует работу в реальном времени.
Предложенная архитектура из четырех модулей (регистрация электроэнцефалограммы → Conformer-энкодер → адаптер с контрастивным обучением (NT-Xent) → онтологический педагогический бэкенд) обеспечивает: (1) формальную спецификацию всех компонентов, достаточную для воспроизведения; (2) аналитически обоснованную задержку 270–525 мс, вписывающуюся в допустимое педагогическое окно; (3) дифференциацию декодирующих артефактов и педагогических ошибок через онтологический reasoner с пороговой логикой.
Когнитивное несоответствие между рецептивными обучающими данными (ZuCo) и генеративной задачей интерфейса рассматривается не как слабость, а как обоснование двухфазной программы офлайн-валидации с последующим пилотным испытанием.
Приоритетными направлениями дальнейших исследований являются: эмпирическая проверка архитектуры на данных воображаемой речи, разработка стратегий доменной адаптации для снижения межсубъектной вариативности, а также оценка готовности к регуляторной сертификации по мере прохождения фаз программы верификации, изложенной в разделе 3.7.
Conflict of interest
Financing
Библиографическая ссылка
Рак Д. В., Аникин А. В. ДЕКОДИРОВАНИЕ СИГНАЛОВ ЭЛЕКТРОЭНЦЕФАЛОГРАФИИ ДЛЯ ИНТЕЛЛЕКТУАЛЬНЫХ ОБУЧАЮЩИХ СИСТЕМ: ОБЗОР ПОДХОДОВ И КОНЦЕПТУАЛЬНАЯ АРХИТЕКТУРА «НЕЙРОТЬЮТОР» // Современные наукоемкие технологии. 2026. № 6. С. 162-169;URL: https://top-technologies.ru/en/article/view?id=40830 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.40830