


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
APPLICATION OF MACHINE LEARNING METHODS TO ASSESS THE EMOTIONAL STATE OF PATIENTS IN REMOTE PSYCHOLOGICAL COUNSELING

Введение
Автоматическое распознавание эмоций по выражению лица относится к числу наиболее заметных направлений аффективных вычислений и компьютерного зрения. Для сферы дистанционного психологического консультирования такие системы представляют практический интерес как вспомогательный аналитический инструмент, позволяющий учитывать не только вербальные, но и визуальные сигналы пациента [1, 2].
Вместе с тем накопленные результаты показывают, что высокая точность на тестовых выборках далеко не всегда переносится на реальные видеосессии. На практике качество распознавания снижается из-за различий между лабораторными и прикладными условиями, ограничений исходных датасетов и нестабильности покадровых предсказаний [1, 3]. Именно этот разрыв между формальными метриками и практической пригодностью особенно важен в задачах консультирования, где интерпретация эмоциональной динамики требует устойчивого и воспроизводимого сигнала.
В представленной статье существенно переработан и расширен материал конференционной публикации за счет включения прикладной реализации из отчета о научно-исследовательской работе. В отличие от исходного варианта, внимание сосредоточено не только на сравнении моделей, но и на том, как экспериментальные выводы трансформируются в архитектуру прототипа программной системы и в рекомендации для ее практического применения.
Цель исследования – разработка и апробация подхода к оценке эмоционального состояния пациента в сценарии дистанционного психологического консультирования, объединяющего экспериментальное сравнение конфигураций моделей распознавания эмоций с практической реализацией модульного программного прототипа.
Материал и методы исследования
Видеопоток представлен последовательностью кадров It, t = 1,…,T, где It ∊ ℝH×W×3 – RGB-кадр в момент t. Задача распознавания эмоций по изображению лица формализуется как построение отображения fθ : It → (bi, ci, si), i = 1,…, Nt, где bi ∊ ℝ4 – координаты ограничивающей рамки лица, ci ∊ C – предсказанный класс эмоции из множества C = c1,…,cK, si ∊ [0,1] – уверенность модели, Nt – число обнаруженных лиц, θ – обучаемые параметры модели.
Параметры θ оцениваются минимизацией композиционной функции потерь
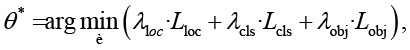
объединяющей слагаемые локализации лица, классификации эмоции и оценки уверенности. В сценарии дистанционного консультирования итоговое решение принимается не по отдельному кадру, а по агрегированной во времени последовательности предсказаний внутри скользящего окна (см. Алгоритм 1).
Экспериментальная часть работы опиралась на два набора данных. Первый набор, Emotion-2, содержит изображения лиц с аннотациями для одностадийной детекции и классификации эмоций. Второй набор представляет собой адаптированную под задачу распознавания эмоций версию FairFace. Использование двух наборов позволило сопоставить поведение моделей на относительно согласованных данных и на данных с выраженными признаками шумной разметки и межклассовой близости [4–6].
Адаптация FairFace к эмоциональным классам позволила увеличить объем обучающих данных, однако одновременно внесла систематические ограничения. Существенная часть изображений характеризуется слабовыраженной мимикой, классы распределены неравномерно, а категории neutral, sad и confused часто различаются только тонкими мимическими признаками [1, 6]. Поэтому на этапе подготовки данных использовались взвешивание классов, аугментации изображений и нормализация входа [7, 8].
Для сравнительного анализа были выбраны четыре конфигурации моделей: YOLOv12n, YOLOv12s, YOLOv12m и RF-DETR-medium. Такой набор позволил сопоставить компактную, сбалансированную и более емкую конфигурации одноэтапного детектора с трансформерным подходом к детекции объектов [9, 10].
Все четыре конфигурации обучались по общей схеме в режиме быстрой адаптации: 10 эпох, размер батча – 16, входное разрешение 640×640 пикселей. В качестве оптимизатора применялся SGD с моментом, весовым затуханием и косинусным расписанием скорости обучения. Из аугментаций использовался стандартный для YOLO набор – mosaic, аффинные преобразования, HSV-сдвиги, горизонтальный флип. Данные делились на обучающую и валидационную выборки в пропорции 80/20 со стратификацией по классам, случайное зерно фиксировалось для воспроизводимости.
В качестве метрик качества использовались mAP@0.5, mAP@0.5–0.95, Precision и Recall – этот набор отражает и качество локализации лица, и корректность классификации эмоции. Отдельно рассматривались межклассовые ошибки: для прикладного сценария важна не суммарная точность сама по себе, а характер систематических перепутываний между близкими эмоциями.
Практическая часть исследования была построена как проектирование прототипа программной системы для анализа эмоций в видеосессии. При разработке структуры прототипа учитывались требования к работе в реальном времени, необходимость стабилизации покадровых предсказаний и возможность адаптации решения к разным прикладным сценариям, включая телемедицинское консультирование и мониторинг в сервисной среде [1, 11, 12].
Результаты исследования и их обсуждение
Результаты сравнения моделей на датасете Emotion-2 приведены в табл. 1. Наилучшее сочетание точности и вычислительной эффективности продемонстрировала модель YOLOv12s. Именно она показала максимальное значение mAP@0.5 при более выгодном соотношении качества и ресурсов по сравнению как с компактной версией YOLOv12n, так и с более тяжелой конфигурацией YOLOv12m.
Полученные данные подтверждают, что простое увеличение числа параметров не гарантирует роста практического качества. Более крупная модель YOLOv12m не показала существенного выигрыша относительно YOLOv12s, что согласуется с литературными наблюдениями о высокой чувствительности задач распознавания эмоций к качеству данных и к особенностям обучающей выборки [1, 3, 13]. Для условий ограниченного вычислительного бюджета более рациональным оказывается выбор модели с лучшим балансом скорости и устойчивости, а не с максимальной емкостью.
Дополнительный анализ на адаптированном FairFace показал выраженную неоднородность качества по отдельным эмоциям. Результаты оценки модели по метрикам Precision и Recall представлены в табл. 2. Наиболее уверенно модель распознает положительное эмоциональное состояние, тогда как классы Confused и Angry характеризуются заметно большим числом ошибок. Это связано одновременно с дефицитом примеров для некоторых категорий и с мимической близостью ряда состояний [1, 6].
Таблица 1
Сравнительные результаты моделей на датасете Emotion-2
|
Модель |
mAP@0.5 |
mAP@0.5–0.95 |
Precision |
Recall |
|
YOLOv12n |
0,945 |
0,920 |
0,890 |
0,910 |
|
YOLOv12s |
0,960 |
0,955 |
0,930 |
0,940 |
|
YOLOv12m |
0,958 |
0,950 |
0,920 |
0,930 |
|
RF-DETR-medium |
0,940 |
0,920 |
0,900 |
0,900 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Таблица 2
Производительность модели YOLOv12s по классам на адаптированном FairFace
|
Класс эмоции |
Precision, % |
Recall, % |
|
Happy |
99,6 |
100,0 |
|
Neutral |
96,3 |
97,5 |
|
Angry |
87,3 |
81,8 |
|
Confused |
75,4 |
87,5 |
|
Sad |
88,1 |
85,2 |
|
Macro avg |
89,3 |
90,4 |
|
Weighted avg |
90,4 |
90,6 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Для расширения статистического анализа результатов поклассовые значения precision и recall были дополнены макро- и взвешенными средними оценками. Macro avg характеризует качество распознавания при равном вкладе каждого эмоционального класса, тогда как weighted avg учитывает их относительную представленность в выборке. Для модели YOLOv12s macro precision и macro recall составили 89,3 и 90,4 %, а weighted precision и weighted recall – 90,4 и 90,6 % соответственно. Близость макро- и взвешенных оценок показывает, что интегральные результаты модели не определяются исключительно преобладающими классами. Вместе с тем поклассовые значения указывают на неравномерность распознавания отдельных эмоций: минимальное значение precision наблюдается для класса Confused, а минимальное значение recall – для класса Angry.
Наиболее принципиальный вывод экспериментальной части состоит в том, что высокая точность на валидационной выборке не обеспечивает автоматически надежную работу на реальном видеопотоке. При переносе модели в прикладной сценарий становятся критичными освещение, ракурс, частичные перекрытия лица и кратковременные покадровые колебания меток. Подобный разрыв между лабораторной оценкой и практикой неоднократно подчеркивался в работах по распознаванию эмоций и по оценке применимости моделей машинного обучения [1, 3].
Именно поэтому второй частью исследования стала практическая реализация прототипа программной системы. Архитектура прототипа показана на рис. 1. В ее составе выделены модуль захвата видеопотока, модуль предобработки изображений, ядро детекции и классификации на основе YOLOv12s, модуль временной агрегации, событийная логика и визуализация результатов. Такая структура позволяет отделить вычислительное ядро от прикладной логики и при необходимости адаптировать систему под другой контекст использования.
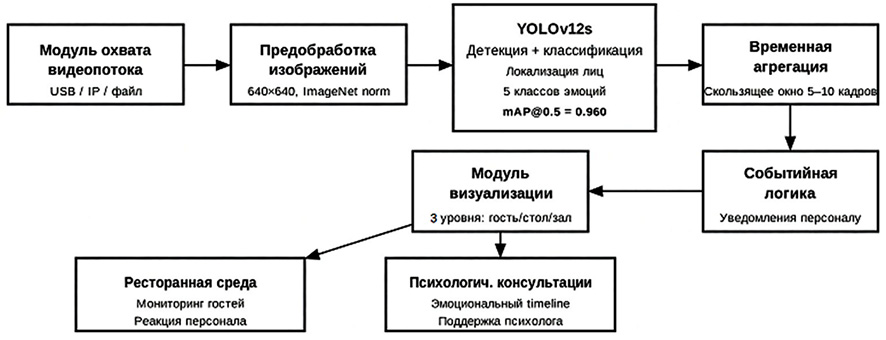
Рис. 1. Архитектура прототипа программной системы распознавания эмоций Примечание: составлен авторами по результатам данного исследования
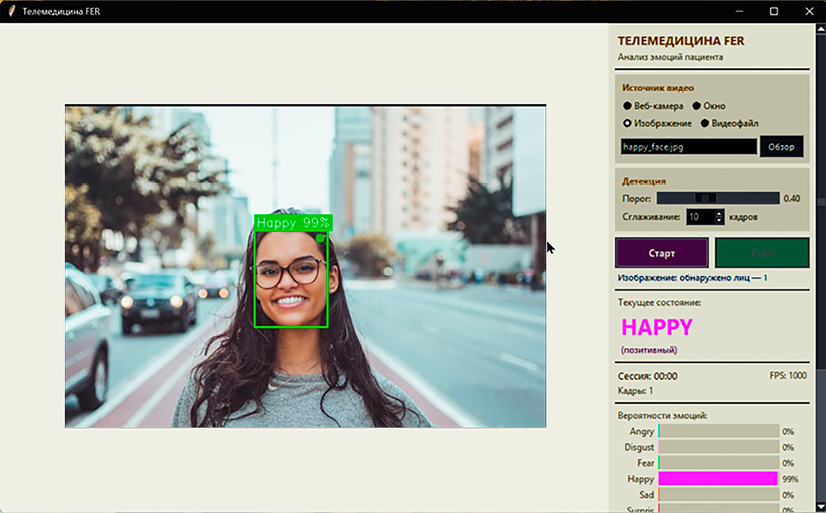
Рис. 2. Интерфейс прототипа для сценария дистанционного психологического консультирования Примечание: составлен авторами по результатам данного исследования
Для сценария дистанционного психологического консультирования решающим оказался модуль временной агрегации предсказаний. Его назначение состоит в усреднении результатов по скользящему окну из нескольких соседних кадров, что снижает влияние случайных колебаний и делает визуализируемую динамику эмоционального состояния более интерпретируемой для специалиста [11, 12]. Без этого слоя даже достаточно точная модель может генерировать шумный сигнал, непригодный для прикладного анализа.
Алгоритм 1. Временная агрегация предсказаний эмоций.
Вход: поток кадровых предсказаний (ct, st); размер окна W; порог уверенности τ; число подтверждающих кадров R.
Выход: стабилизированная эмоция ĉt и агрегированная уверенность ŝt.
1. Инициализировать кольцевой буфер B размера W.
2. Для каждого нового кадра t:
2.1. если st ≥ τ – добавить (ct, st) в B;
2.2. если B пуст, сохранить предыдущее стабилизированное значение;
2.3. для каждого класса c ∊ C вычислить:
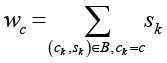 ;
;
2.3. определить:
 ;
; 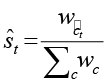 ;
;
2.4. если значение ĉt удерживается R кадров подряд – зафиксировать событие смены эмоционального состояния.
Интерфейс прототипа для телемедицинского применения приведен на рис. 2. Пользователь получает не только текущую распознанную эмоцию, но и значение уверенности, параметры сглаживания, число обнаруженных лиц и наглядное представление распределения вероятностей по классам. Такая организация интерфейса соответствует задаче поддержки принятия решения, а не автоматической подмены специалиста.
Дополнительно прототип апробирован в ресторанном сценарии – для мониторинга эмоционального фона посетителей. Этот контекст не относится к основному предмету статьи, но позволил оценить универсальность выбранной архитектуры: одна и та же программная основа применяется в разных прикладных задачах за счет смены правил агрегации и визуализации. Прогоны на видеозаписях и в условиях, близких к реальным, показали работоспособность основных модулей и возможность обработки видеопотока в реальном времени на потребительском GPU. Вместе с тем выявились ограничения, заметные именно при внедрении: снижение качества при неравномерном освещении, ухудшение распознавания при отклонении головы от фронтального положения, ошибки на частично перекрытых лицах и нестабильность результата без сглаживания. Прикладная ценность системы, таким образом, складывается не только из метрик детектора – заметную роль играют качество постобработки и интерфейс интерпретации результата.
Из сопоставления экспериментальной и прикладной частей работы вытекает несколько практических выводов. При ограниченном бюджете на обучение и инференс модель YOLOv12s дает разумный компромисс между точностью и расходом ресурсов. При разработке системы предпочтительнее опираться на специализированные эмоциональные датасеты – или комбинировать несколько профильных наборов, чем ограничиваться адаптацией неспециализированных данных [5, 6]. В сценариях видеоконсультирования имеет смысл подключать временную фильтрацию предсказаний, пороги уверенности и механизмы подавления частых переключений между близкими эмоциями [1, 11, 14].
Среди направлений дальнейшего развития – переход от анализа отдельных кадров к более полному учету временной динамики и к мультимодальной обработке. Существенный потенциал в этой области показывают трансформерные архитектуры [15, 16] и методы совместного использования визуальных и иных сигналов [12, 14], хотя их практическая эффективность по-прежнему зависит от качества и репрезентативности обучающих данных.
Заключение
По результатам сравнения среди рассмотренных конфигураций YOLOv12s обеспечивает лучший баланс между точностью распознавания и вычислительной эффективностью и в этом смысле предпочтительнее остальных для задачи оценки эмоционального состояния пациента при дистанционном психологическом консультировании. При этом эксперименты на двух наборах данных подтвердили, что высокие валидационные метрики не гарантируют устойчивой работы на реальном видеопотоке: практическое качество заметно снижают шумная разметка, близость эмоциональных классов, вариации освещения, ракурс и частичные окклюзии лица.
Практическая реализация модульного прототипа подтвердила техническую реализуемость предложенного подхода для сценария дистанционного психологического консультирования. Ключевым элементом, обеспечивающим надежность системы в условиях реального видеопотока, оказался модуль временной агрегации предсказаний, позволяющий сгладить покадровые колебания и сформировать интерпретируемый сигнал для специалиста. Полученные результаты свидетельствуют о том, что практическая ценность подобных систем определяется не только архитектурными решениями и метриками детектора, но и качеством обучающих данных, продуманностью механизмов постобработки и соответствием прикладной логики конкретному сценарию использования.
Перспективы дальнейшего развития системы связаны с применением специализированных датасетов эмоций, тонкой адаптацией модели под прикладной домен, расширением мультимодального анализа и совершенствованием механизмов постобработки результатов, в том числе переходом от анализа одиночных кадров к учету временной динамики эмоционального состояния.
Conflict of interest
Financing
Библиографическая ссылка
Путинцева А. А., Андреева В. Д., Эбрахим А., Хасанов И. И. ПРИМЕНЕНИЕ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ОЦЕНКИ ЭМОЦИОНАЛЬНОГО СОСТОЯНИЯ ПАЦИЕНТОВ ПРИ ДИСТАНЦИОННОМ ПСИХОЛОГИЧЕСКОМ КОНСУЛЬТИРОВАНИИ // Современные наукоемкие технологии. 2026. № 6. С. 156-161;URL: https://top-technologies.ru/en/article/view?id=40829 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.40829