


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
A FUZZY MODEL OF THE SEMANTIC SPACE IN THE COMPUTATIONAL THEORY OF SEMANTIC INTERPRETATION

Введение
Сегодня социальное взаимодействие формируют большие языковые модели (LLM) [1–3]. Они сопряжены с искусственным интеллектом (ИИ) [4–6], поддерживаются вычислительными и финансовыми ресурсами, посильными крупным корпорациям. Пользователь общается с ИИ на естественном языке (ЕЯ) через интеллектуальные чат-боты типа ChatGPT [7], DeepSeek [8], LLaMA, Gemini и др., но дружественность общения не гарантирует конфиденциальность. Информация накапливается в дата-центрах, формируя цифровой портрет пользователя, и такой процесс является неотъемлемой частью глубокого машинного обучения (Deep Learning) [9]. Он явно проявляется в маркетплейсах и чат-ботах [9; 11]. LLM имеют корни в модели BERT [12], и на сегодня создано много инструментов и технологий по естественно-языковой обработке (NLP), называемых совместно Бертологией.
И тем не менее в ряде задач использование LLM избыточно и затратно, что формирует предпосылки к поиску иных подходов. Так, в работах Ю. М. Вишнякова и Р. Ю. Вишнякова [13] развивается вычислительная теория семантической интерпретации, где семантика текстовых фрагментов моделируется вычислительными процедурами. В их же работах [14; 15] представлены формальная модель семантического объекта и алгоритмы поиска текстов заданной семантической направленности, а в [16] описан программный комплекс поиска семантических следов объектов. Решения восходят к формально-грамматическому подходу работы авторов А. Ахо, Дж. Ульман [17, с. 103–241], допускают математическую оценку результатов и не требуют значительных вычислительных ресурсов.
Цель исследования – дополнить вычислительную теорию семантической интерпретации нечеткой моделью индивидуального семантического пространства, отражающей субъективный смысл слова.
Материал и методы исследования
Обсудим ключевые элементы вычислительной теории семантической интерпретации. Пусть задана цепочка q слов ai, представляющая целостный по смыслу текстовый фрагмент (предложение или его часть):
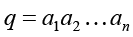 . (1)
. (1)
Целостность означает, что все слова входят в словосочетания и образуют отношение непосредственного подчинения на множестве слов фрагмента.
Обозначим через S(ai) множество смысловых значений слова ai, тогда множество S(q) смысловых значений q (1) в общем виде представляется функционалом Ф вида
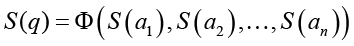 , (2)
, (2)
который назовем функционалом смысла.
Выделим в q какое-либо словосочетание ab (a – главное, b – зависимое слова) и представим смысловую зависимость (стрелка показывает направление) записью вида
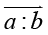 , (3)
, (3)
Смысловое значение словосочетания есть подмножество смысловых значений его главного слова, формируемое смыслом зависимого слова (контекстом). Оно по форме напоминает условную вероятность и может быть представлено в подобной нотации:
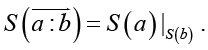 (4)
(4)
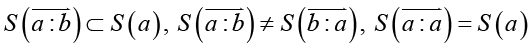 . (5)
. (5)
Введем для словосочетания операцию контекстного уточнения смысла вида
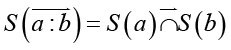 , (6)
, (6)
где 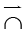 – операция контекстного уточнения смысла (стрелка задает направление выполнения операции) и второе тождество (5) указывает на ее несимметричность.
– операция контекстного уточнения смысла (стрелка задает направление выполнения операции) и второе тождество (5) указывает на ее несимметричность.
Если слово а – главное слово в нескольких словосочетаниях и b1, b2 ,..., bp – зависимые слова, то контекстной связкой слова а называется запись:
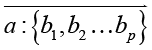 , (7)
, (7)
Распространив (6) на контекстную связку (7), получим пересечение множеств вида
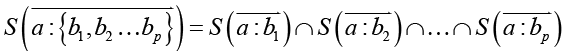 , (8)
, (8)
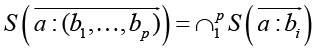 , (9)
, (9)
Если слово ai главное слово в q (1), то из (6) и (9) следует
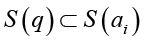 , (10)
, (10)
Раскрывая выражение S(q) (6) с учетом (6), (8) и (9), получим формульное представление функционала смысла фрагмента q в виде
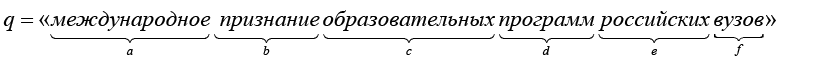 (11)
(11)
Закодируем слова латинскими буквами, тогда смысловое значение S(q) принимает вид
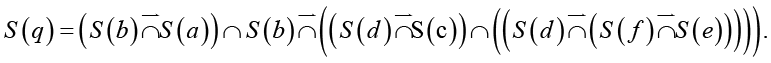 (12)
(12)
В построенных по правилам [17, c. 55–67] синтаксических деревьях (pис. 1) для (6), (9) и (12) из-за несимметричности операций контекстного уточнения смысла в их узлах стрелка поменяла направление на обратное, а ветвь главного слова в кусте стала последней.
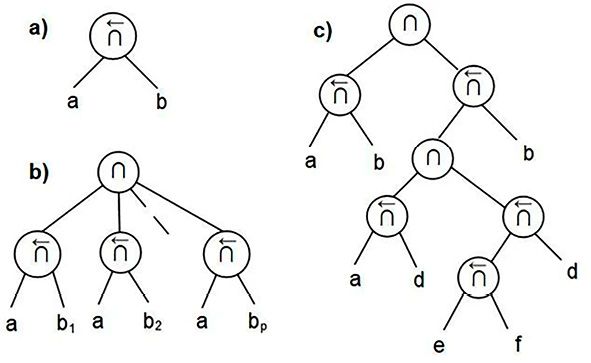
Рис. 1. Синтаксические деревья: а)операции контекстного уточнения смысла, b) контекстной связки и c) функционала смысла Примечание: составлен авторами по результатам данного исследования
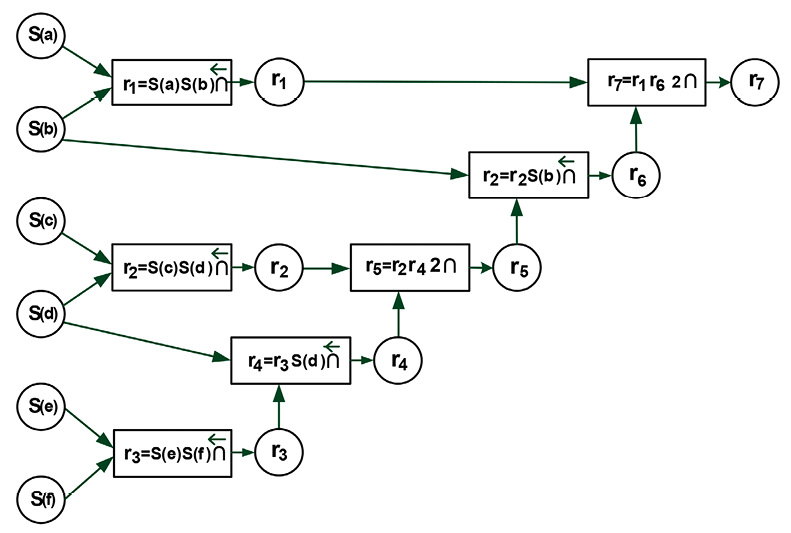
Рис. 2. Семантическая схема функционала смысла q Примечание: составлен авторами по результатам данного исследования
Результаты обходов деревьев (рис. 1) представляют ОПЗ-подобные нотации вида
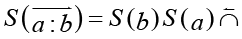 (13)
(13)
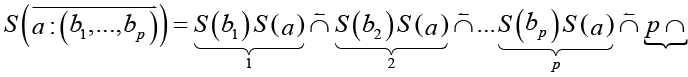 . (14)
. (14)
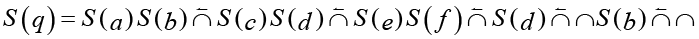 . (15)
. (15)
При вычислении (15) выполняется самая левая операция, результат сохраняется в переменной r, замещая в строке операцию с операндами, далее процесс повторяется. Графическое представление вычислительной процедуры (рис. 2) называется семантической схемой.
В семантической схеме прямоугольные элементы (элементы смысла) представляют операции, круглые – их входы и выходы. Если текстовый фрагмент q представлен n элементами смысла, m из которых содержатся в схеме фрагмента t, то критерий семантической близости (q, t) равен m/n. Таким образом сравнение фрагментов сводится к сравнению вычислительных процедур, в которых слова представляют переменные.
В естественном языке слово и смысл образуют неразрывную пару (x,S(x)), слово как знак объективно (написано, произнесено), смыслом владеет субъект. В речевых актах (чтение, письмо, разговор) субъект интерпретирует слова и придает им определенные смысловые значения, возможно и новые. Например, во фрагменте (11) слово x = ʺпризнаниеʺ относится к образовательным программам вуза, отвечающим международным требованиям, это смысловое значение раскрывается функционалом смысла (12), (15) или семантической схемой (рис. 2). В иных случаях слову «признание» можно придать другие смыслы (признание заслуг, признание в любви и пр.), актуализируемые другими контекстными окружениями.
Например, для слова «яблоко» множество S(яблоко) можно представить в виде
S(яблоко) = {S(яблоко,y)y∊Y},
где Y = {кислое, кисло-сладкое, сладкое, терпкое,…} – вкусовая гамма.
При дополнении вкусовых качеств размерами элементы S(яблоко,Y) могут быть сами множествами, например,
{S(яблоко сладкое маленькое), S(яблоко сладкое среднее), …}.
Подобным образом вводятся цвет, форма и пр., включая стилизованный логотип Apple. Но и тогда многообразие смыслов слова «яблоко» не исчерпывается. В пределе множество смыслов «человека собирательного», включающее существовавшие, существующие и будущие смыслы слова x, определим как потенциально бесконечный универсум Suniv(х). Ограниченное множество смыслов (смысловое пространство) Spind(х) конкретного человека p формируется жизненным опытом, поэтому оно ограничено. Также смысловые пространства людей одной культурной-профессиональной группы схожи, что подметил профессор В. В. Налимов в работе [18, с. 65–109]. В дальнейшем бесконечность универсума Suniv(х) и конечность Spind(х) считаем модельным допущением.
Поставим в соответствие множеству Suniv(х) круг с центром в слове x. Элементы Suniv(х) упорядочим по концентрическим окружностям: на меньшем радиусе – наиболее привычные смысловые значения с равными значимостями, далее – менее привычные и т. д. Данный круг назовем кругом значимости смысловых значений слова.
Определим для радиусов окружностей круга значимости меру длины, для чего представим множество радиусов R (х) упорядоченным множеством в виде
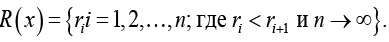 (16)
(16)
Введем функцию значимости смыслового значения, ставящую в соответствие каждому i-му частному смыслу слова x некоторую величину μi, вида
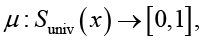 (17)
(17)
0 ≤ μi ≤ 1. (18)
При μi → 1 значимость смысла повышается (окружность сдвигается к центру круга), при μi → 0 – понижается (окружность удаляется от центра). График μ(R) представлен на рис. 3.
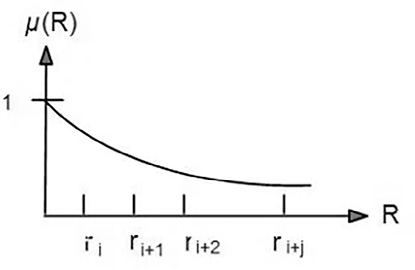
Рис. 3. Функция значимости смыслового значения Примечание: составлен авторами по результатам данного исследования
Для μi = f(Suniv(х)) можно выбрать разные формульные представления, например:
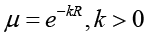 . (19)
. (19)
Но более привычна и понятна функция, обратная радиусу окружности круга значимости:
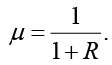 (20)
(20)
Если для слова «яблоко» привычен смысл «сладкое яблоко», менее привычен – «кислое яблоко» и совсем не привычен «яблоко – логотип Apple» и если расположить их на концентрических окружностях r1 = 0,5, r2 = 1,0, r3 = 2,0, то из формулы (20) получим их смысловые значения μ1 = 0,67, μ2 = 0,5, μ3 = 0,33, убывающие с удалением от центра. Круг значимости и монотонность убывания функции значимости считаются модельными допущениями.
Пусть в паре (si(х), μi) si(х) – смысловое значение слова x и μi – мера его значимости. Интерпретируем μi смысл как степень принадлежности нечеткой логики Лютфи Заде [19]. Тогда совокупность пар образует нечеткое множество 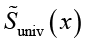 универсума Suniv(х):
универсума Suniv(х):
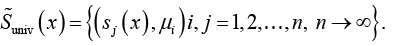 (21)
(21)
По аналогии с (21) индивидуальный круг значимости смысловых значений слова x конкретного человека p представим также нечетким множеством 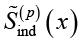 вида
вида
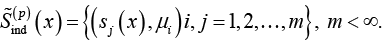 (22)
(22)
Пространства и различаются, поскольку субъект p не может вместить всего многообразия смыслов универсума, но, обучаясь, модифицирует добавлением новых смыслов или изменением значимости существующих. При этом источником обучения является контекстное окружение слова в речевом акте. Обсудим теперь модели обучения.
Если слово x употребляется в ранее неизвестном субъекту значении Snew, то оно включается в :
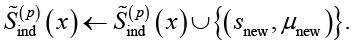 (23)
(23)
Так, речевой акт (11) вводит в смысловое пространство 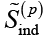 (признание) новое значение
(признание) новое значение
Snew = ʺмеждународное признание образовательных программ российских вузовʺ.
На значимость смыслов слова влияют многие факторы: частота употребления, авторитетность источника, эмоциональная окраска и пр. Если μnew(s) значимость нового понимания, то простая модель обучения с обновлением имеет вид
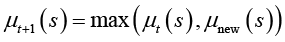 . (24)
. (24)
Такая усложненная модель, учитывающая частоту, представляется в виде
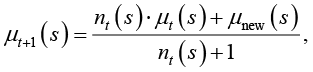 (25)
(25)
где nt(s) – количество предшествующих актов, в которых данный смысл актуализировался.
В моделях с накоплением отсутствует забывание неактуализируемых смыслов, но его можно ввести коэффициентом забывания λ ∈ (0,1), после чего получим модель с забыванием:
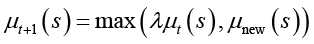 . (26)
. (26)
При λ = 1 забывания нет. Если λ < 1, отсутствие актуализации смысла μnew(s) = 0 снижает значимость μt+1(s) = λμt(s), а актуализация μnew(s) > λμt(s) ее восстанавливает.
Пусть текущая значимость смысла «международное признание программ» μt = 0,5 и в новом контексте она актуализируется μnew = 0,9. Тогда в модели с накоплением (24) 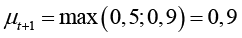 , а в модели с забыванием (26) при λ = 0,8
, а в модели с забыванием (26) при λ = 0,8
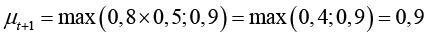 и перекрывает забывание. Когда смысл не актуализируется (μnew = 0), в модели с накоплением μt+1 = 0,5, а с забыванием
и перекрывает забывание. Когда смысл не актуализируется (μnew = 0), в модели с накоплением μt+1 = 0,5, а с забыванием 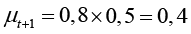 (снижается).
(снижается).
Таким образом, в динамическом обучении индивидуальное смысловое пространство обновляясь, стремится к универсуму , но никогда его не достигает.
Для оценивания взаимопонимания слова х субъектами p и q введем меру сходства 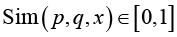 (sim – сокращение от англ. similarity – сходство). Если Sim = 1, то смысловые пространства субъектов
(sim – сокращение от англ. similarity – сходство). Если Sim = 1, то смысловые пространства субъектов 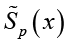 и
и 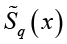 полностью совпадают (идеальное взаимопонимание), при Sim = 0 общих смыслов нет (полное непонимание). Другие значения Sim соответствуют частичному взаимопониманию. Поскольку индивидуальные смысловые пространства заданы нечеткими множествами, то степень их сходства Sim(p,q,x) можно выразить мерой близости нечетких множеств коэффициентом Жаккара:
полностью совпадают (идеальное взаимопонимание), при Sim = 0 общих смыслов нет (полное непонимание). Другие значения Sim соответствуют частичному взаимопониманию. Поскольку индивидуальные смысловые пространства заданы нечеткими множествами, то степень их сходства Sim(p,q,x) можно выразить мерой близости нечетких множеств коэффициентом Жаккара:
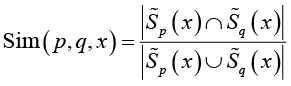 . (27)
. (27)
В (27) нечеткие операции пересечения и объединения определяются выражениями
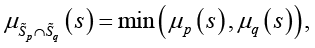 (28)
(28)
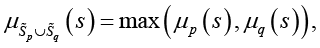 (29)
(29)
а мощность нечеткого множества представляется сумма значимостей:
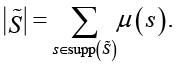 (30)
(30)
Пусть слово «признание» для субъектов A и B представлено нечеткими множествами:
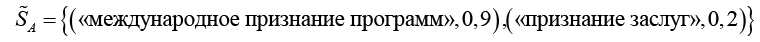 ;
;
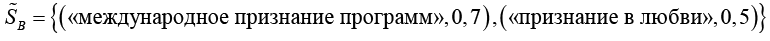 ,
,
Нечеткое пересечение
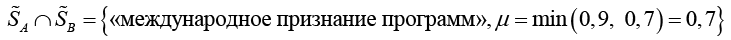
имеет мощность 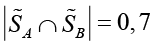 .
.
Объединение включает три смысла со значимостями 0,9, 0,2, 0,5; и его мощность
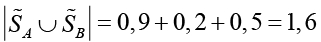 .
.
Степень взаимопонимания
Sim(A, B, «признание») = 0,7 / 1,6 = 0,4375.
Сконструируем и проиллюстрируем на моделях динамического обучения общий алгоритм отбора претендентов в команду, который применим к большому классу задач.
Пусть некий вуз планирует выход на международный уровень через процедуру международной профессиональной аккредитации [20]. Вуз стремится пройти аккредитацию с минимальными издержками, поскольку его ресурсы ограничены. Сотрудники вуза имеют поверхностное представление о процедурах аккредитации, и в этой связи один из них (далее – «Учитель») направляется на обучения в признанный аккредитационный центр. По возвращению Учитель должен сформировать компетентную команду для решения поставленной задачи. Учитель разрабатывает общий план – обучение, оценка компетентности, отбор и реализует следующий алгоритм.
Алгоритм
Шаг 1. Выделение ключевых понятий для обучения. Выделены ключевые понятия для понимания аккредитации: «признание образовательных программ», «компетентностный подход», «внутренняя система качества» (использован функционал смысла (2), контент-анализ в сфере профессиональной аккредитации). Для каждого понятия х сконструировано универсальное смысловое пространство Suniv(х). Например, круг значимости понятия «признание»: на ближайшей окружности (r = 0,5) размещены наиболее привычные для аккредитологов смыслы: «оценка соответствия стандартам», «международная валидация». На средней окружности (r = 1,0) – «подготовка самоотчета», «выездная экспертиза». На дальней окружности (r = 2,0) – «логотип агентства» (менее значимый). По формуле (20) μ = 1 / (1 + R) вычислены значимости: μпривычный = 0,67, μсредний = 0,5, μпериферийный = 0,33.
Результат шага: множество смыслов Suniv(признание), Suniv(компетентностный подход), Suniv(внутренняя система качества) и их функции значимости μ.
Шаг 2. Начальное тестирование кандидатов. Проводится путем опроса и интервью с кандидатом p по каждому ключевому понятию х
Результат шага: начальные индивидуальные смысловые пространства в виде нечетких множеств кандидатов.
Анна:
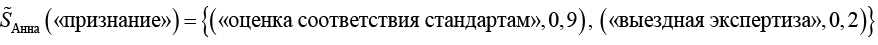 .
.
Борис:

Максим:
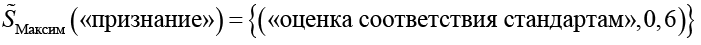 .
.
Шаг 3. Динамическое обучение. В течение четырех циклов обучения Учитель актуализирует ключевые смыслы, используя контексты, сформированные по функционалу смысла. Экспертные оценки забывания: для Анны и Бориса λ = 0,8; для Максима – λ = 0,6 (ускоренное забывание).
Шаг 4. Итоговое тестирование и оценка взаимопонимания. По завершению обучения для каждой пары вычисляется индекс сходства 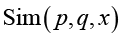 (27)–(30). Порог включения в команду устанавливается равным 0,7.
(27)–(30). Порог включения в команду устанавливается равным 0,7.
Шаг 5. Принятие решения. Кандидаты, достигшие порога с хотя бы одним коллегой, рекомендуются в команду.
Результат работы алгоритма представлен табл. 1–3.
Итак, Анна и Борис прошли отбор, а Максим, несмотря на начальное присутствие ключевого смысла, был отсеян из-за быстрого забывания (λ = 0,6).
Таблица 1
Итоговые смысловые пространства кандидатов
|
Кандидат |
«Оценка соответствия» |
«Подготовка отчета» |
«Выездная экспертиза» |
«Международная валидация» |
Примечание |
|
Анна |
0,90 |
0,80 |
0,90 |
0,80 |
λ = 0,8 |
|
Борис |
0,90 |
– |
0,80 |
0,70 |
λ = 0,8 |
|
Максим |
0,14 |
0,25 |
0,54 |
0,42 |
λ = 0,6 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Таблица 2
Попарные индексы сходства Sim
|
Пара |
Сумма пересечения |
Сумма объединения |
Sim |
Достижение порога 0,7 |
|
Анна – Борис |
2,40 |
3,40 |
0,706 |
Да |
|
Анна – Максим |
1,35 |
3,40 |
0,397 |
Нет |
|
Борис – Максим |
1,10 |
2,65 |
0,415 |
Нет |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Таблица 3
Решение о включении в команду
|
Кандидат |
Лучший Sim (с кем) |
Решение |
Обоснование |
|
Анна |
0,706 (с Борисом) |
Включена |
Достигает порога с Борисом |
|
Борис |
0,706 (с Анной) |
Включен |
Достигает порога с Анной |
|
Максим |
0,415 (с Борисом) |
Не включен |
Ниже порога со всеми |
Примечание: составлена авторами на основе полученных данных в ходе исследования
Таким образом модель динамического обучения с забыванием способна выявлять пробелы в знаниях и способность субъекта к долгосрочному удержанию понятийного аппарата предметной области и позволяет:
1. Формализовать начальные индивидуальные смысловые пространства кандидатов.
2. Смоделировать динамику обучения с учетом забывания.
3. Количественно оценить взаимопонимание с помощью индекса сходства Sim.
4. Принять объективное решение о формировании команды на основе заданного порога.
Результаты исследования и их обсуждение
Полученные результаты дополняют вычислительную теорию семантической интерпретации субъективной природой смысла слова x и позволяют конструировать модели субъективного понимания и взаимопонимания введением универсального Suniv(х) и индивидуального 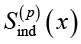 смысловых пространств. Первое представляет потенциально бесконечный универсум всевозможных смыслов слова, второе – смысловое пространство субъекта, конечное и динамически изменяемое жизненным опытом.
смысловых пространств. Первое представляет потенциально бесконечный универсум всевозможных смыслов слова, второе – смысловое пространство субъекта, конечное и динамически изменяемое жизненным опытом.
Геометрическая интерпретация кругом значимости с монотонно убывающей функцией μ позволяет представить смысловые пространства нечеткими множествами и воспользоваться аппаратом нечеткой логики.
Для моделирования динамики индивидуального смыслового пространства предложены модели обучения с накоплением и забыванием. Обновление происходит включением ранее неизвестных смыслов или изменением значимостей известных. В моделях с забыванием значимости неактуализируемых смыслов понижаются вплоть до полного исключения. Модель можно уточнять, учитывая частоту актуализаций, время между ними, конкуренцию между смыслами и пр.
Предложена мера взаимопонимания между субъектами p и q в виде степени сходства 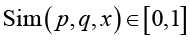 и способ ее вычисления. Здесь 1 соответствует идеальному взаимопониманию (пространства совпадают), 0 – полному непониманию (совпадения нет).
и способ ее вычисления. Здесь 1 соответствует идеальному взаимопониманию (пространства совпадают), 0 – полному непониманию (совпадения нет).
Сконструирован алгоритм создания компетентной команды, формализующий построение начальных смысловых пространств субъектов, моделирующий динамику обучения с забыванием и оценивающий взаимопонимание кандидатов. Применимость продемонстрирована примером профессиональной аккредитации образовательных программ.
Эмпирическая верификация модели путем проведения психолингвистических экспериментов, анализа корпусов текстов с экспертной разметкой, сравнения с векторным представлением слов (word embeddings) и LLM-моделями предполагает отдельное исследование ближайшей перспективы.
Заключение
В работе предложена нечеткая модель смыслового пространства, дополняющая вычислительную теорию семантической интерпретации субъективной природой смысла слова. Она включает геометрическую интерпретацию пространства (круг значимости с функцией значимости), представление пространств нечеткими множествами, динамику обучения с накоплением и забыванием, а также количественную меру взаимопонимания. На основе модели построен общий алгоритм формирования компетентных команд для широкого круга задач.
Подход допускает точную математическую оценку, не требует сравнимых с LLM-моделями вычислительных ресурсов и создает основу для построения эффективных алгоритмов и программных систем для обработки естественно-языковой информации.
Conflict of interest
Financing
Библиографическая ссылка
Вишняков Ю. М., Вишняков Р. Ю. НЕЧЕТКАЯ МОДЕЛЬ СМЫСЛОВОГО ПРОСТРАНСТВА В ВЫЧИСЛИТЕЛЬНОЙ ТЕОРИИ СЕМАНТИЧЕСКОЙ ИНТЕРПРЕТАЦИИ // Современные наукоемкие технологии. 2026. № 6. С. 45-53;URL: https://top-technologies.ru/en/article/view?id=40815 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.40815