


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
ADVANCED APPROACH TO DISTRIBUTED SYSTEMS: DYNAMIC ALGORITHMS AND EFFICIENT PROCESSING OF BIG DATA

Введение
Устойчивый рост объемов генерируемых данных продолжает сохранять внимание научного и инженерного сообществ к разработке более эффективных методов их обработки и глубокого анализа. Существующие алгоритмы и методы, такие как MapReduce (программная модель, разработанная для обработки больших объемов данных), Sharding (подход к разделению и распределению данных по множеству серверов или баз данных) и консистентное хеширование (алгоритм, предназначенный для распределенных систем, который обеспечивает равномерное распределение данных через кластер узлов с минимальными перераспределениями при добавлении или удалении узлов), хотя и демонстрируют достаточный уровень эффективности и возможностей применения, имеют ряд ограничений, связанных с масштабируемостью, производительностью и устойчивостью к отказам. В распределительных системах, где особенно важно обеспечить распределение нагрузки и данных между узлами, такие ограничения создают острую необходимость в создании более эффективного метода. Стандартные подходы могут приводить к неравномерному распределению, что увеличивает риск перегрузок и снижает общую производительность системы. В эпоху больших данных эффективное распределение и обработка информации становятся важными вехами для функционирования распределенных систем. Традиционные алгоритмы демонстрируют ограничения по масштабируемости, производительности и балансировке нагрузки. Проблема заключается в необходимости разработки усовершенствованных алгоритмов, способных обеспечить более эффективное распределение данных, с учетом динамических условий эксплуатации систем.
Цель исследования – усовершенствование существующих алгоритмов обработки и распределения данных, учитывая текущую нагрузку на систему и общую загруженность для обеспечения более равномерного распределения ресурсов, повышения производительности и масштабируемости распределенных систем, снижения задержки и увеличения их общей устойчивости к отказам.
Материалы и методы исследования
В данном разделе внимание направлено на детальное рассмотрение технологий, стоящих в авангарде обработки больших данных, таких как MapReduce, сегментирование (англ. sharding), и консистентное хеширование. Осмысление их роли и ограничений в современных распределенных системах позволит выявить зоны потенциальных улучшений.
MapReduce – это программная модель, предназначенная для эффективной обработки больших объемов данных [1]. Основные фазы алгоритма – Map (отображение) и Reduce (сведение) – позволяют параллельно обрабатывать данные, значительно ускоряя процесс [1].
Функция Map – принимает на вход пары ключ-значение `(k, v)` и обрабатывает их, возвращая список промежуточных пар ключ-значение `(k’, v’)` [2]. Формулу функции Map можно представить так:
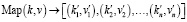 .(1)
.(1)
Функция Reduce – принимает на вход ключ `k’` и список значений `[v’]`, связанных с этим ключом, и агрегирует эти значения, возвращая результат в виде списка значений `v’’` [2]. Формулу функции Reduce можно изобразить так:
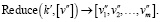 (2)
(2)
Основные ограничения связаны с высокой задержкой обработки задач, ограниченной интерактивностью и неэффективностью при вычислениях [3]. Усовершенствование MapReduce включает оптимизацию фазы Map для сокращения времени обработки и улучшение фазы Reduce для более эффективной агрегации данных. Использование машинного обучения для предварительного анализа паттернов данных может дополнительно ускорить обработку.
Сегментирование (сегментирование базы данных) – методика горизонтального разделения данных на несколько сегментов («шардов»), каждый из которых хранится в отдельной таблице или базе данных. Этот процесс позволяет распределить данные и нагрузку по множеству серверов, улучшая таким образом производительность и масштабируемость системы. Основная цель сегментирования – обеспечить равномерное распределение данных и оптимизировать скорость доступа к ним [4]. Формула для определения целевого шарда конкретной записи выглядит следующим образом:
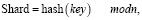 (3)
(3)
где 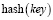 – хеш-функция, применяемая к ключу записи, (n) – общее количество доступных шардов.
– хеш-функция, применяемая к ключу записи, (n) – общее количество доступных шардов.
Основные ограничения связаны с проблемами перераспределения данных при изменении количества шардов, с балансировкой нагрузки и сложностью масштабирования. Возможное усовершенствование сегментирования может быть связано с внедрением искусственного интеллекта и методов машинного обучения для балансировки нагрузки (прогнозирование нагрузки и адаптация в режиме реального времени), оптимизации хеширования (определение «горячих точек» нагрузки шардов) и динамического масштабирования (изменение количества шардов) [5].
Консистентное хеширование является фундаментальным механизмом в проектировании распределенных систем, способствующим улучшению балансировки нагрузки и уменьшению колебаний при динамических изменениях в кластере [6]. Основная идея этого подхода заключается в создании равномерно распределенного хеш-пространства, где каждый узел и каждый элемент данных имеют свой хеш, определяющий их позицию в кольце хеширования [7]. Виртуальные узлы позволяют одному физическому узлу представлять собой несколько узлов в хеш-пространстве, что облегчает балансировку нагрузки между узлами. Благодаря этому, добавление или удаление узлов в системе приводит к минимальному количеству перемещений данных, что существенно уменьшает накладные расходы и повышает стабильность системы в условиях динамических изменений.
Формула, включающая коэффициент C, зависящий от текущей нагрузки системы, и общую нагрузку (total_load), позволяет оптимально распределить данные между узлами. Такой подход не только повышает эффективность обработки запросов, но и обеспечивает более равномерное распределение нагрузки, минимизируя риск перегрузки отдельных узлов.
Формула для расчета коэффициента C может варьироваться в зависимости от конкретных требований системы и выбранных метрик нагрузки. Однако базовая идея заключается в использовании текущей нагрузки системы для динамической адаптации распределения данных.
Формула для расчета коэффициента C:
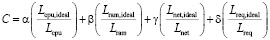 , (4)
, (4)
где (Lcpu), (Lram), (Lnet), (Lreq) – текущая нагрузка на систему по CPU, RAM, сетевой активности и количеству запросов соответственно, (Lcpu,ideal), (Lram,ideal), (Lnet,ideal), (Lreq,ideal) – идеальные уровни нагрузки для каждого из этих параметров, (α), (β), (γ), (δ) – коэффициенты важности каждой метрики, отражающие их вклад в общую производительность системы. Сумма этих коэффициентов должна быть равна 1((α + β + γ + δ = 1)), чтобы обеспечить балансировку вклада каждой метрики.
Расчет общей нагрузки (total_load) в контексте консистентного хеширования и распределенных систем может быть выполнен разными способами, в зависимости от определения «нагрузки» в вашей системе и от того, какие метрики вы считаете важными. В общем случае, total_load представляет собой совокупную нагрузку на систему, которая может включать CPU, память, сеть, количество активных запросов и другие параметры. Вот несколько подходов к расчету total_load:
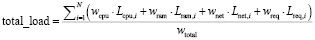 , (5)
, (5)
где (N) – количество узлов в системе, (Lcpu,i), (Lram,i), (Lnet,i), (Lreq,i) – значения нагрузки по CPU, RAM, сетевой активности и запросам на i-м узле соответственно, (wcpu), (wram), (wnet), (wreq) – весовые коэффициенты для каждого типа нагрузки, отражающие их вклад в общую нагрузку системы, (wtotal) – сумма всех весовых коэффициентов, используемая для нормализации результата.
Данный подход позволяет учесть вклад различных типов ресурсов в общую нагрузку системы, давая возможность более точно адаптировать распределение данных и нагрузку. Веса (wcpu, wram, wnet, wreq) позволяют модифицировать важность каждого параметра в зависимости от специфики работы системы и требований к производительности. Для реализации такого расчета важно регулярно осуществлять сбор актуальных данных о загруженности системы по всем учтенным параметрам и адаптировать весовые коэффициенты на основе изменений в требованиях к системе или наблюдаемой производительности. Такой подход обеспечит гибкость системы в реагировании на изменения в нагрузке и оптимизировать распределение ресурсов для поддержания высокой производительности и стабильности. Консистентное хеширование находит широкое применение в различных областях, включая системы кеширования, распределенные базы данных и сети доставки контента (CDN) [8]. Этот подход обеспечивает надежность и доступность данных, минимизируя влияние изменений в топологии системы на производительность и устойчивость к отказам. Особенно значима данная модель для облачных вычислений и микросервисной архитектуры, где требуется высокая степень масштабируемости и гибкости в управлении ресурсами.
Результаты исследования и их обсуждение
Ниже представлена улучшенная формула консистентного хеширования с виртуальными узлами и адаптивным распределением, учитывающая текущую нагрузку системы. Предложенный подход включает использование виртуальных узлов и адаптивного перераспределения данных с учетом текущей нагрузки системы, что позволяет минимизировать пиковые нагрузки и улучшить общую производительность системы.
1. Традиционная формула консистентного хеширования [9]:
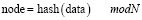 , (6)
, (6)
где hash(data) – это хеш-функция для данных, N – количество физических узлов в системе.
2. Улучшенная формула с виртуальными узлами:
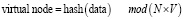 ,(7)
,(7)
где V – количество виртуальных узлов, ассоциированных с каждым физическим узлом, что позволяет более равномерно распределить данные по физическим узлам и упрощает балансировку нагрузки.
3. Адаптивное распределение с учетом нагрузки.
Основываясь на анализе существующих алгоритмов и выявленных недостатках, предлагается ряд улучшений, направленных на оптимизацию процессов распределения и обработки данных в распределенных системах. Одним из ключевых предложений является введение динамического коэффициента в формулы распределения данных, который корректируется на основе текущей нагрузки и объема данных на каждом из узлов. Такой подход позволяет системе более гибко реагировать на изменения и поддерживать оптимальное распределение данных, минимизируя риски перегрузки отдельных узлов. Предлагается соотношение, обеспечивающее адаптацию системы к изменяющимся условиям, гарантируя равномерное распределение нагрузки и оптимальное использование ресурсов:
Узел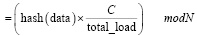 , (8)
, (8)
где hash(data) – хэш-функция данных; (С) – динамический коэффициент, зависящий от текущей нагрузки системы, (total_load) – суммарная нагрузка на систему; (N) – количество узлов в системе.
Эффективность предложенного подхода целесообразно оценить посредством анализа, представленного на рис. 1, где осуществляется сравнительное исследование традиционной и усовершенствованной формулы распределения нагрузки. Визуализированные результаты демонстрируют преимущества предложенного подхода, выраженные в более равномерном распределении ресурсов и улучшении ее адаптивности к динамическим изменениям эксплуатационных условий.
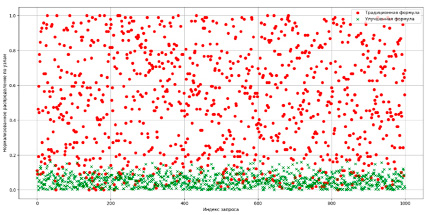
Рис. 1. Сравнение традиционного подхода и предлагаемого Источник: разработано авторами
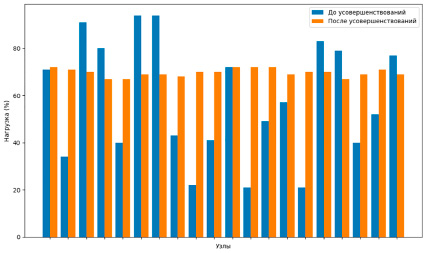
Рис. 2. Сравнение нагрузки на узлы при традиционном подходе и с учетом улучшений, предложенных в данной работе Источник: разработано авторами
Применение традиционного подхода консистентного хеширования может привести к возникновению неравномерного распределения нагрузки между узлами, что иллюстрируется следующими показателями: 80, 60, 90 и 70 % соответственно. Такая диспропорция приводит к перегрузке одних узлов при недогрузке других, что негативно сказывается на эффективности использования ресурсов. Предложенный метод распределения данных, учитывающий как текущую загрузку системы, так и общую нагрузку, обеспечивает более равномерное распределение ресурсов между узлами. Это позволяет избежать дисбаланса, повышая справедливость и эффективность распределения, и обеспечивает стабильную работу системы без перегрузки или недогрузки отдельных узлов. Таким образом, предложенный метод позволяет достичь более справедливого и эффективного распределения ресурсов по сравнению со старым, гарантируя, что ни один узел не будет перегружен или недогружен. Такой подход улучшает устойчивость системы к внезапным изменениям в нагрузке и способствует более равномерному использованию ресурсов, что особенно важно для облачных вычислений и микросервисных архитектур, что подтверждается результатами моделирования, представленными на рис. 2.
Заключение
Анализ существующих методов и предложенные усовершенствования подчеркивают важность развития адаптивных систем для обработки больших данных. Преодоление ограничений традиционных алгоритмов через инновационные подходы к распределению нагрузки позволяет достичь оптимальной работы распределенных систем. Внедрение усовершенствованных алгоритмов и современных технологий обработки данных создает перспективы для дальнейших исследований и разработок. Интеграция искусственного интеллекта, методов машинного обучения и новейших научных достижений в существующие подходы позволяет существенно повысить эффективность и качество обработки данных. Это, в свою очередь, может создать условия для разработки высокоэффективных интеллектуальных систем, способных с максимальной точностью и скоростью решать сложнейшие задачи, что откроет перед человечеством новые перспективы для развития науки и технологий.
Библиографическая ссылка
Батанов А.О., Литвинова А.С. ПЕРЕДОВОЙ ПОДХОД К РАСПРЕДЕЛЕННЫМ СИСТЕМАМ: ДИНАМИЧЕСКИЕ АЛГОРИТМЫ И ЭФФЕКТИВНАЯ ОБРАБОТКА БОЛЬШИХ ДАННЫХ // Современные наукоемкие технологии. 2025. № 3. С. 8-13;URL: https://top-technologies.ru/en/article/view?id=40317 (дата обращения: 15.06.2026).
DOI: https://doi.org/10.17513/snt.40317