


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
AN INVESTIGATION OF THE EFFECTIVENESS OF LONG-RANGE AND SHORT-TERM MEMORY MODELS LRCN+LSTM IN VIDEO VIOLENCE DETECTION TASKS

Введение
Распознавание человеческих действий (HAR) – процесс определения типа человеческой активности в видеопотоке – в последние годы получил значительное развитие, в основном благодаря достижениям в области технологий глубокого обучения и методов анализа данных. На эту эволюцию также повлияло развитие моделей обнаружения объектов. Некоторые из хорошо известных передовых технологий, которые способствовали этому прогрессу, включают рекуррентные сверточные сети (RNN), которые предназначены для обнаружения объектов. Долгосрочные рекуррентные сверточные сети (LRCN) объединяют сверточные нейронные сети (СNN) с рекуррентными нейронными сетями для анализа последовательных данных, в том числе и видео. В данном исследовании используется архитектура нейронной сети с длительной кратковременной памятью (LSTM), которая представляет собой тип RNN, специально предназначенный для решения проблемы исчезающего градиента, с которой обычно сталкиваются традиционные сети такого типа. Архитектура LRCN + LSTM эффективно сочетает в себе возможности извлечения признаков CNN и возможность LSTM изучать последовательности, что делает ее высокоэффективной для задач визуального распознавания и анализа временных данных.
Распознавание действий человека – определение типа действия человека на видеопотоке значительно эволюционировало за последние годы, благодаря улучшенным технологиям глубокого обучения и методов анализа данных [1]. Эволюция моделей обнаружения объектов оказала влияние и на развитие HAR [2]. В список таких передовых технологий включают рекуррентную нейронную сеть [3], быстрые регионы с использованием сверточных нейронных сетей (R-CNN) [4], а также популярное в настоящее время семейство технологий YOLO. Современные методы анализа видео в основном основаны на глубокой нейронной сети, в данной работе предлагается одна из моделей долговременной рекуррентной сверточной сети (RNN), сочетающая в себе средство извлечения визуальных признаков с глубокой иерархией с моделью, которая может научиться распознавать и синтезировать временную динамику для задач, связанных с последовательными данными (входными или выходными данными), визуальный, лингвистический или какой-либо другой [5]. В RNN градиент ошибки рассчитывается как произведение градиентов ошибки по каждому параметру, однако при этом он может становиться слишком большим, что приводит к нестабильности обучения [6]. Это связано с тем, что RNN имеет сложную структуру, которая включает в себя рекуррентные связи между ячейками. Сети LRCN, использующие LSTM, предназначены для решения этой проблемы путем эффективного отслеживания долгосрочных зависимостей во входных последовательностях и решения проблемы исчезающего градиента, характерной для традиционных сетей RNN. Этому способствует уникальная архитектура LSTM, которая включает в себя ячейки памяти и стробирующий механизм, позволяющий выборочно запоминать и забывать информацию в течение длительного периода времени. При этом необходимо учитывать, что ячейка памяти (рис. 1) здесь действует как промежуточный блок памяти, состоящий из более простых узлов, соединенных по определенной схеме [7].
Целью исследования является оценка двух моделей LSTM при распознавании сцен насилия в видеороликах, сравнение их эффективности и изучение влияния гиперпараметрического обучения на их эффективность, учитывая, что набор данных, используемый для обучения нейронной сети, имеет решающее значение для анализа, поскольку он предоставляет необходимые размеченные данные для оценки возможностей модели в распознавании сложных паттернов в видеопоследовательностях.
Материалы и методы исследования
Набор данных
Доступность маркированных наборов данных для обучения моделей распознавания насильственных действий существенно ограничена по сравнению с наборами данных для общих задач компьютерного зрения. Этот недостаток может быть обусловлен рядом факторов, включая опасения по поводу конфиденциальности пациентов и отсутствие общепринятых процедур обмена медицинскими данными. Чтобы решить эту проблему, исследователи предлагают несколько подходов, включая использование простых методов увеличения на базе масштабирования наборов данных и генерацию синтетических данных с помощью генеративно-противостоящих сеток GAN.
В данном проекте для обучения был создан пользовательский набор данных из содержащего 150 помеченных видео открытого набора данных Violence Detection in Videos [8] и 50 собственных видеофрагментов двух классов (насилие и ненасилие), разделенных на фрагменты по 10 с каждый. В процессе работы кода алгоритм распределяет видеофайлы на тренировочную и тестовую части (80/20) в две размеченные папки.
Долговременная кратковременная память LSTM
LSTM решает проблемы взрыва градиента и исчезновения градиента в длинных последовательностях. Он также использует гейтинг для управления каждым блоком LSTM. Важно то, что LSTM имеет на одно состояние C (ячейку памяти) больше, чем обычная RNN. Текущее состояние ячейки Сt может быть обновлено по следующей формуле:
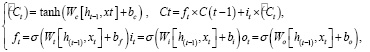 (1)
(1)
где Сt–1 – предыдущее состояние ячейки, σ – функция активации, W – весовая матрица, b – смещение.
Таблица 1
Модель с UniLSTM
|
Слой |
Тип |
Параметры |
Форма выхода слоя |
|
Conv2D |
TimeDistributed |
128 |
(None, 28, 28, 32) |
|
MaxPooling2D |
TimeDistributed |
– |
(None, 14, 14, 32) |
|
Flatten |
TimeDistributed |
– |
(None, 6272) |
|
LSTM |
– |
256 |
(None, 64) |
|
Dense |
– |
2 |
(None, 2) |
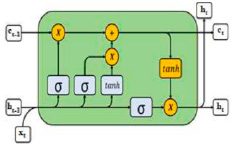
Рис. 1. Компоненты ячейки LSTM
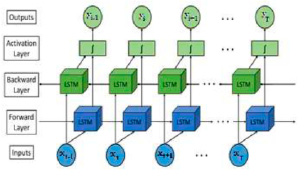
Рис. 2. Архитектура двунаправленной сети LSTM
Модель LRCN с однонаправленным LSTM (UniLSTM)
LRCN+LSTM – это модифицированная версия LRCN, которая включает в себя LSTM ячейки для улучшения способности модели к запоминанию длинных последовательностей. Модель однонаправленной рекуррентной нейронной сети представляет собой архитектуру, которая использует одну рекуррентную нейронную сеть, работающую в одном направлении. Для реализации модели однонаправленной рекуррентной нейронной сети используется API Keras. Каждый слой LSTM имеет 256 единиц, что соответствует размеру скрытого слоя и обрабатывает последовательные данные и генерирует 64-мерный результат. Этот результат затем классифицируется по одной из двух категорий с помощью плотного слоя (табл. 1).
Для обработки последовательных данных используется слой LSTM, а для сверточного и объединяющего слоев к каждому кадру видеопоследовательности используется оболочка TimeDistributed (рис. 1).
Таким образом, слой (вокруг которого он обернут) может принимать входные данные формы (no_of_frames, width, height, num_of_channels), если изначально входные данные слоя имели форму (width, height, num_of_channels).
Модель LRCN c двунаправленным Bidirectional LSTM (BLSTM)
BLSTM – это модифицированная версия LSTM, которая состоит из двух рекуррентных нейронных сетей, работающих в противоположных направлениях. Модель двунаправленной рекуррентной нейронной сети представляет собой архитектуру, которая сочетает в себе две рекуррентные сети, работающие в противоположных направлениях. Каждый двунаправленный слой LSTM имеет по 512 единиц, что соответствует размеру скрытого слоя. Каждый двунаправленный слой LSTM обрабатывает последовательные данные и генерирует 64-мерный результат, которые объединяются, чтобы получить 128-мерный вектор. Сам вектор затем классифицируется по одной из двух категорий с помощью плотного слоя (табл. 2). Используемый термин «глазок» основан на идее о том, что состояние ячейки «подсматривает» за выходными данными ячейки, чтобы принимать решения о том, что делать с информацией. Это позволяет LSTM лучше фиксировать долгосрочные зависимости в данных. Для вычисления выходных данных блока LRCN используется следующая формула:
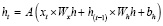 , (2)
, (2)
где A – функция активации, W – весовая матрица, b – смещение.
Скрытое состояние в момент времени t задается комбинацией Нt, выходной сигнал в любом заданном скрытом состоянии Yt. Для обучения использовались два типа сетей долгой краткосрочной памяти. При реализации двунаправленной сети долгой краткосрочной памяти BLSTM поверх стандартного UniLSTM, был использован следующий подход: сначала идет прямой переход, где обработка входной последовательности идет стандартным способом, используя однонаправленный LSTM (формула (1)). Это дает представление о скрытом состоянии на каждом временном шаге. Далее обратный переход, обработка последовательности ввода пройдет в обратном порядке, начиная с последнего временного шага и возвращаясь к первому временному шагу, используя ту же архитектуру LSTM, что и при прямой технологии, но с обратной последовательностью ввода. Объединение скрытых состояний, полученных при прямом и обратном проходах, дает новое скрытое состояние, которое отражает как прошлый, так и будущий контекст.
На рис. 2 показана архитектура двунаправленной сети LSTM с (T) этапами [9]. Например, для момента (t) прямой слой использует данные момента (t–1) для генерации данных момента (t+1). Из уравнений (2) и (3) можно видеть, что в обратном слое данные момента (t+1) используются для генерации данных момента (t–1). Необходимо добавить, что оба процесса используют один и тот же слой активации независимо от направления потока информации. Далее можно описать работу двунаправленной рекуррентной нейронной сети.
Таблица 2
Модель с двунаправленной сетью LSTM
|
Слой |
Тип |
Параметры |
Форма выхода слоя |
|
Conv2D |
TimeDistributed |
128 |
(None, 28, 28, 32) |
|
MaxPooling2D |
TimeDistributed |
– |
(None, 14, 14, 32) |
|
Flatten |
TimeDistributed |
– |
(None, 6272) |
|
Bidirectional LSTM |
– |
512 |
(None, 64) |
|
Bidirectional LSTM |
– |
512 |
(None, 64) |
|
Dense |
– |
2 |
(None, 2) |
В сеть сначала вводится последовательность точек данных, каждая из которых представлена в виде вектора с одинаковой размерностью (рис. 1). При этом используется оболочка Bidirectional для создания двунаправленного LSTM-слоя с общими весами [10]. Аргумент merge_mode определяет способ объединения прямых и обратных выходных данных в режиме конкатенации (рис. 2). Модель Bidirectional LSTM способна учитывать как предшествующий, так и последующий контекст в последовательных данных, данная задача оформлена в формуле (3). Это особенно полезно для таких задач, как языковое моделирование и видеоанализ. В процессе работы состояние ячейки «подсматривает» за выходными данными, что позволяет принимать более обоснованные решения о том, как обрабатывать поступающую информацию. Это позволяет сети лучше фиксировать долгосрочные зависимости в данных [11].
Для вычисления выходных данных блока LRCN используется следующая формула:
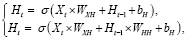 (3)
(3)
где Ht – выходной сигнал на шаге t, Xt – входной на шаге t, WXH – весовая матрица для входных сигналов, WHH – весовая матрица для выходных, bH – смещение, σ – активационная функция.
Результаты исследования и их обсуждение
В данном исследовании был проведен анализ производительности двух типов моделей долговременной кратковременной памяти: UniLSTM и BLSTM. Обе модели были обучены на наборе данных с видеороликами, содержащими насильственные и ненасильственные действия, с целью определения того, какая модель более эффективна при распознавании моделей и особенностей, связанных с насилием [12]. В процессе реализации проекта возникли проблемы при создании пользовательского набора данных, включая сложность переобучения и ограниченные вычислительные ресурсы, однако, несмотря на эти препятствия, в результате экспериментов с различными архитектурами, скоростью обучения, размерами пакетов и другими параметрами была определена оптимальная комбинация слоев и настроек. Обучение и тестирование проводились в течение 50 и 100 эпох соответственно. Производительность моделей оценивалась на основе нескольких показателей, включая потери, точность, потери при валидации и достоверность валидации. Результаты показали, что BLSTM превосходит стандартную LSTM по точности и скорости обработки. Обучение как BLSTM, так и UniLSTM показало, что обе модели достигли высокой точности и низкого уровня потерь после 50 и 100 периодов. Однако BLSTM неизменно демонстрировала более высокую точность и меньшие потери по сравнению с однонаправленной моделью. После 50 эпох ее точность составила 0,85, а потери 0,3376, в то время как UniLSTM зафиксировала точность 0,845 и потерю 0,3207. Хотя разница в точности была минимальной, двунаправленная модель продемонстрировала более низкий уровень потерь. По прошествии 100 эпох точность обеих моделей улучшилась: Двунаправленная модель достигла 0,905, а однонаправленная – 0,889. BLSTM также продемонстрировал значительное снижение потерь, составив 0,3007 по сравнению с 0,3218 для однонаправленной модели. В итоге BLSTM превзошел UniLSTM как по точности, так и по потерям в обеих схемах.
Для оценки эффективности моделей были использованы показатели точности, позволяющие получить представление об их способности распознавать данные и прогнозировать результаты. Сравнительный анализ эффективности различных моделей обучения для выявления насилия и ненасилия в видеоклипах показал, что двунаправленная модель, обученная более 50 эпохам, продемонстрировала более высокую точность и полноту распознавания для обеих категорий по сравнению с однонаправленной.
Когда продолжительность обучения была увеличена до 100 периодов, двунаправленная модель продолжала демонстрировать улучшенную производительность. Для ненасильственных событий точность и полнота BLSTM сохранялись на уровне 0,89 и 0,77 соответственно, в то время как для UniLSTM точность снизилась до 0,67, а полнота – до 0,45. Напротив, для случаев насилия точность двунаправленной модели составила 0,90, а полнота – 0,91, что представляет собой значительное повышение по сравнению с точностью однонаправленной модели, равной 0,80 для случаев насильственного поведения (табл. 3). Графики, полученные в результате исследования, дают ценную информацию о производительности моделей LRCN+LSTM при распознавании насильственных и ненасильственных действий в видеоклипах (рис. 3). Далее, анализ матрицы ошибок показывает, что обе модели LSTM демонстрируют неплохие результаты в классификации насилия и ненасилия при увеличении количества эпох.
Таблица 3
Отчет о классификации для сетей LRCN+LSTM
|
Однонаправленное LSTM |
Двунаправленное LSTM |
||||||
|
точность (precision) |
отзыв |
f1-score |
точность (precision) |
отзыв |
f1-score |
Поддержка |
|
|
epochs = 50 |
|||||||
|
Ненасилие |
0,75 |
0,92 |
0,85 |
0,84 |
0,90 |
0,84 |
198 |
|
Насилие |
0,94 |
0,71 |
0,81 |
089 |
0,81 |
0,83 |
202 |
|
Точность (accuracy) |
0,83 |
0,84 |
400 |
||||
|
mavg* |
0,76 |
0,95 |
0,85 |
0,86 |
0,86 |
0,85 |
400 |
|
wevg** |
0,94 |
0,71 |
0,81 |
0,86 |
0,85 |
0,85 |
400 |
|
epochs = 100 |
|||||||
|
Ненасилие |
0,96 |
0,67 |
0,79 |
0,90 |
0,89 |
0,89 |
198 |
|
Насилие |
0,75 |
0,97 |
0,84 |
0,89 |
0,90 |
0,90 |
202 |
|
Точность (accuracy) |
0,82 |
0,90 |
400 |
||||
|
mavg* |
0,85 |
0,82 |
0,82 |
0,90 |
0,89 |
0,89 |
400 |
|
wevg** |
0,85 |
0,82 |
0,82 |
0,90 |
0,90 |
0,89 |
400 |
Примечание. * mavg – среднее значение метрики для каждого класса; ** wevg – метрика, которая учитывает веса классов при расчете среднего значения метрики.
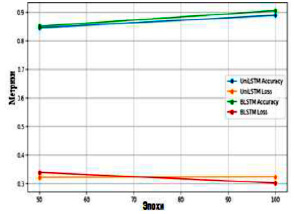
Рис. 3. Производительность моделей для разных параметров эпох
Таблица 4
Матрица ошибок для 50 эпох
|
Ненасилие |
Насилие |
|
|
UniLSTM |
||
|
Ненасилие |
172 |
26 |
|
Насилие |
51 |
149 |
|
ВLSTM |
||
|
Ненасилие |
178 |
22 |
|
Насилие |
36 |
164 |
|
Ненасилие |
Насилие |
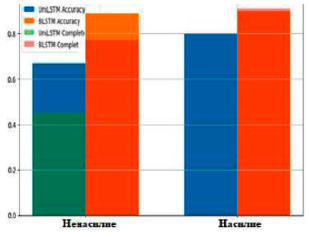
Рис. 4. Точность и полнота информации о насильственных и ненасильственных событиях
Таблица 5
Матрица ошибок для 100 эпох
|
Ненасилие |
Насилие |
|
|
UniLSTM |
||
|
Ненасилие |
188 |
10 |
|
Насилие |
58 |
144 |
|
ВLSTM |
||
|
Ненасилие |
186 |
12 |
|
Насилие |
40 |
162 |
|
Ненасилие |
Насилие |
Однако BLSTM демонстрирует лучшие результаты в определенных сценариях (рис. 4). На 50 эпохах она показывает (табл. 4) лучшие результаты в распознавании насилия (82,0 % против 74,3 % для UniLSTM) и ненасилия (90,8 % против 87,4 % для UniLSTM). Кроме того, на 100 эпохах BLSTM также демонстрирует лучшие результаты в распознавании насилия (88,3 %) и ненасилия (96,4 %). В целом двунаправленная модель демонстрирует преимущества в распознавании насилия и ненасилия, особенно на 100 эпохах (табл. 5).
Это может быть связано с тем преимуществом, что может использовать информацию из обоих направлений последовательности, что позволяет ему лучше понимать контекст и распознавать насилие. В исследовании сравниваются две модели для LRCN + LSTM: UniLSTM и BLSTM, которые используются для распознавания насилия и ненасилия в видеороликах. BLSTM демонстрирует лучшие результаты по точности и скорости обработки по сравнению с UniLSTM. После 50 эпох двунаправленная модель показывает точность 0,85 и потери 0,3376, в то время как однонаправленная модель показывает точность 0,845 и потери 0,3207. После 100 эпох сеть BLSTM увеличила точность до 0,905 и, соответственно, уменьшила потери до 0,3007. На 50 эпохах двунаправленная модель показывает лучшие результаты в распознавании насилия (82,0 % против 74,3 % для UniLSTM) и ненасилия (90,8 % против 87,4 % для UniLSTM). На 100 эпохах BLSTM также демонстрирует лучшие результаты в распознавании насилия (88,3 %) и ненасилия (96,4 %).
Обе модели демонстрируют достаточную способность распознавать ненасильственные действия, но у ВLSTM немного выше точность и меньше ошибок классификации. Итоги работы подтверждают, что двунаправленная модель является более эффективной моделью для распознавания насилия и ненасилия в видеофрагментах, чем однонаправленная, это важно для разработки систем распознавания признаков насилия, которые могут быть использованы в различных приложениях, таких как мониторинг видео и анализ поведения.
Заключение
Несмотря на растущую доступность крупномасштабных наборов данных для общих задач компьютерного зрения, аннотированные наборы данных для моделей распознавания насилия по-прежнему мало представлены. Согласно отчету International Journal of Computer Vision, только 10 % общедоступных наборов данных для задач компьютерного зрения специально ориентированы на распознавание насилия и многие из этих наборов данных невелики и необъективны.
Проведенное исследование показало, что двунаправленная модель долговременной кратковременной памяти (BLSTM) является более эффективной моделью для распознавания насилия и ненасилия в видеофрагментах, чем однонаправленная модель (UniLSTM). Результаты экспериментов показали, что BLSTM демонстрирует лучшие результаты в распознавании насилия (88 %) и ненасилия (96 %). Эти результаты имеют значения для разработки систем распознавания признаков насилия, которые могут быть использованы в различных приложениях, таких как мониторинг видео и анализ поведения. Кроме того, результаты исследования могут быть использованы для улучшения существующих систем распознавания насилия и ненасилия. Несмотря на это, результаты данного исследования демонстрируют потенциал моделей LSTM для распознавания насилия в видеороликах, надо учесть, что оценка модели на основе небольшого набора данных может привести к переобучению, подбору и неадекватной оценке модели, что, в свою очередь, может вызвать неадекватную оценку точности модели и ее способности справиться с новыми данными.
Библиографическая ссылка
Горяев В.М., Мацаков Б.В. ИССЛЕДОВАНИЕ ЭФФЕКТИВНОСТИ МОДЕЛЕЙ НЕЙРОСЕТИ LRCN+LSTM В ЗАДАЧАХ РАСПОЗНАВАНИЯ НАСИЛИЯ НА ВИДЕО // Современные наукоемкие технологии. 2024. № 12. С. 17-24;URL: https://top-technologies.ru/en/article/view?id=40239 (дата обращения: 24.07.2026).
DOI: https://doi.org/10.17513/snt.40239