


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
ABOUT THE DEFECT DETECTION AT A MANUFACTURING ENTERPRISEUSING NEURAL NETWORKS (ON EXAMPLE OF ALATOYS LLC)

Введение
Отрасль создания игрушек является уникальной, в том числе потому, что в ней практически не существует стандартизированных решений в области автоматизации ручного труда. Каждый производитель зачастую занимается собственным конструированием и производством оборудования под конкретную производственную задачу.
Компания «Алатойс» является одним из лидеров страны в области производства детских развивающих игрушек из дерева [1]. В деятельности компании присутствует ручной труд, который при высоких показателях выпуска идентичной продукции в единицу времени непременно приводит к браку в виде недокомплектов изделий, что подтверждается отзывами на маркетплейсах.
С учетом событий начала 2022 г., а также самых низких показателей рождаемости с 1999 г. [2] данные тенденции в целом продолжат негативным образом сказываться на рынке труда и на емкости отрасли. В этой связи вопросы автоматизации труда, повышения его интенсификации и эффективности являются сверхактуальными абсолютно для всех участников рынка исследуемой отрасли промышленности. Особенно с учетом того фактора, что научные труды по использонию компьютерного зрения в области производства деревянных развивающих игрушек отсутствуют.
Автором работы в целях решения поставленной задачи были изучены основные нейронные сети, применяемые в компьютерном зрении (в основном сверточные). Они представлены как одноуровневыми, так и двухуровневыми моделями. Широкую распространенность в компьютерном зрении приобрели следующие нейросети: R-CNN (Region-based Convolutional Neural Networks), EfficientNets, VGG (Visual Geometry Group), ResNets, YOLO (You Only Look Once) [3, с. 478–491]. Выбор последней в качестве одного из инструментов для решения поставленной задачи обусловлен в первую очередь скоростью и точностью ее работы при потреблении незначительных вычислительных ресурсов.
Цель исследования – разработка и апробация нейросетевой модели для детекции брака на производственном предприятии, осуществляющем выпуск продукции для детей дошкольного возраста, на базе предобученной модели YOLOv8.
Материалы и методы исследования
Написание кода осуществлялось на языке Python в интерпретаторе VSCode. Гиперпараметры обучения модели:
− epochs = 500,
− imgsz = 640,
− batch = 32,
− patience = 200.
В рамках исследования был использован собственный датасет, представленный 240 снимками и разделенный в следующих пропорциях:
192 единицы – обучающая выборка,
48 единиц – валидационная.
Разметка снимков проводилась вручную с помощью сервиса CVAT.ai [4]. Для разметки были выделены три уникальных идентификатора в каждом из артикулов, взятых для разметки: «карточки», «фишки», «подставки». Указанные артикулы выбраны ввиду их наибольшей распространенности по недокомплектам в отзывах от покупателей. Разметка проводилась методом «Polygon Shape».
Для преобразования полученных файлов использовался репозиторий c GitHub, расположенный по ссылке: https://github.com/Koldim2001/COCO_to_YOLOv8 [5]. По итогам отработки кода была получена следующая структура рабочей папки:
− файл data.yaml;
− папка train;
− папка validation.
Папки train и validation, в свою очередь, состояли из папок images и labels, а также файла labels.cache. Папка images представлена файлами с расширением *.jpg, папка labels – с расширением *.txt.
Для обучения были выбраны два размера модели YOLOv8 от Ultralitics [6]: yolov8s-seg и yolov8m-seg. Параметры моделей представлены на рис. 1.
Обучение производилось на локальной машине с операционной системой MacOS на чипе m1 и встроенной видеокартой. Как показала практика, выбор аппаратного средства не являлся оптимальным ввиду низкой адаптации ноутбуков на базе указанного чипа под решение аналогичных задач. Обучение меньшей по размеру модели (yolov8s-seg) заняло более 3 суток, большей по размеру (yolov8m-seg) – более 7 суток.
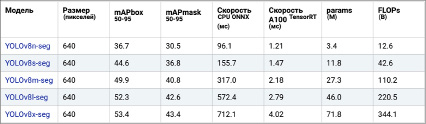
Рис. 1. Параметры предобученной модели YOLOv8
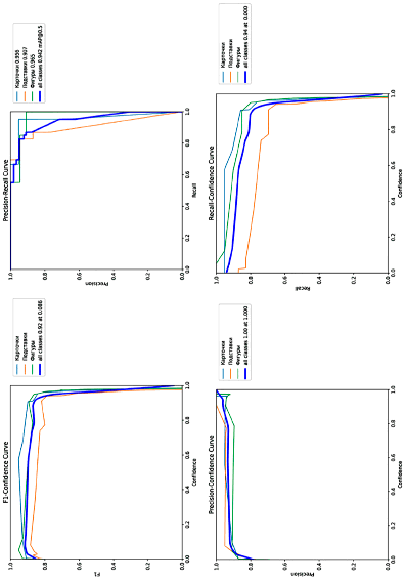
Рис. 2. Графики метрик качества при детекции box’ов
Результаты исследования и их обсуждение
В результате обучения модели были получены следующие данные, представленные на рис. 2. Первый блок полученных параметров представлен графиками «box»’ов, то есть границ детектируемых объектов и корректности определения их классов (меток).
График в левом верхнем углу отражает f1-меру, то есть гармоническое среднее точности (precision) и полноты (recall). Максимум для всех классов (0,92) метрика принимает при значении парметра confidence (уверенность) в 0,086. В то же время скорость «снижения» графика при росте показателя уверенности предсказания является незначительной. Однозначно можно сделать вывод, что при уверенности более 0,9 модель выдает метрику f1 более 0,8, что говорит о высоком качестве ее работы.
Остальные три графика характеризуют уверенность (confidence) работы модели на метриках точности (precision) и полноты (recall). Можно сделать вывод, что модель уверенно ведет себя при определении точности (значение метрика = 1,0 при confidence = 1,0), то есть 100 % точность работы модели. При этом график Precision – Recall curve (правый верхний график) демонстрирует значение точности более 0,9 при полноте более 0,8 с условием treshhold = 0,5 по метрике mAP. Метрику полноты (recall) для всех классов снижает возможность определения метки «подставка», что говорит о необходимости расширения датасета в целях обучения модели для детекции именно их.
Отметим, что графики метрик качества для определения масок предметов показывают идентичные результаты, поэтому в настоящей статье данный блок графиков будет упущен.
Следующий блок изображений представлен матрицами ошибок (нормализованной и обычной), корреляционной матрицей меток и описанием представленных меток. Группировка изображена на рис. 3.
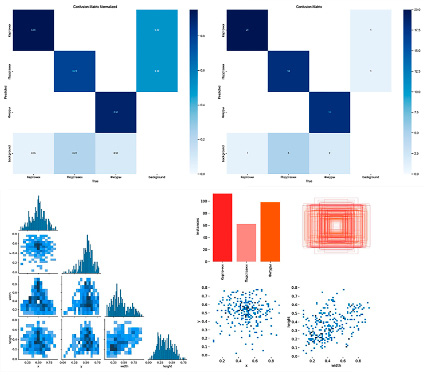
Рис. 3. Графики матриц, полученных в ходе обучения ошибок и меток
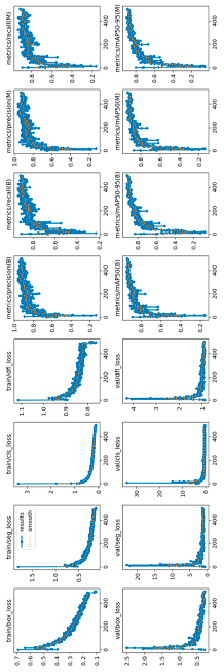
Рис. 4. Графики ошибок, а также средних значений средней точности при различных пороговых значениях IoU, варьирующихся от 0,5 до 0,95
Представленные графики подтверждают гипотезу худшей отработки модели (по сравнению с остальными метками) для определения метки «подставки». Можно увидеть, что при обучении модель «путает» подставку с фоном изображения, либо, наоборот, определяет подставку там, где на фоне ее нет. В свою очередь, по верхнему правому графику можно сделать предположение, что модель отрабатывает подобным образом ввиду наименьшего количества меток «подставка» в изображениях, вошедших в обучающую выборку, и для последующего получения лучших резльтатов следует дополнить ее именно изображениями с метками «подставка». Но даже с учетом вышенаписанного показатели детекции находятся на высоком уровне (метрика обнуружения объекта с меткой «подставка» равна 0,78).
Одним из основополагающих файлов с точки зрения отслеживания процесса обучения модели является файл с изображениями графиков снижения ошибки при обучении, а также графиков средних значений средней точности при различных пороговых значениях IoU, варьирующихся от 0,5 до 0,95. Все метрики, заложенные разработчиками в модель (определение точности построения прямоугольника координат объекта (box), сегментация объекта (seg), определение вероятности отнесения объекта к той или иной метке (cls), определение объекта при его деформации (dfl), а также метрики средней точности при перекрытии объекта от 50 до 95 % (mAP)), показывают уверенное снижение (в зону нуля) показателей ошибки, а также увеличение значений точности (в зону единицы) с ростом количества эпох обучения. Результаты представлены на рис. 4.
На рис. 5 представлены примеры детекции объектов в рамках обучения описанной выше модели.

Рис. 5. Пример изображений, получаемых в ходе обучения модели на базе YOLOv8
Рис. 6. Пользовательский интерфейс, в который обернута разработанная модель
После обучения модели на языке Python был написан модуль подключения видеокамеры, в том числе беспроводной, для осуществления детекции и блока упрощенного фронтенда для взаимодействия с пользователем с помощью библиотек cv2 [7] и tkinter [8]. На рис. 6 представлен скриншот фронтенда, в рамках которого пользователь выбирает артикул выпускаемого изделия. В рамках работы конвейера при обнаружении детектируемого объекта код считывает количество обнаруженных меток, на которые обучена модель, и сравнивает их количество с количеством единиц выпущенного продукта (они должны совпадать). Оператор станка запайки сравнивает их и при выявлении расхождений проводит повторную проверку партии.
Заключение
По результатам проведенных экспериментов можно сделать однозначный вывод о том, что разработанный прототип показывает достаточно высокую эффективность при использовании на производстве. Подтверждается гипотеза о возможности использования компьютерного зрения на промышленных предприятиях, оуществляющих разработку продукции для детей. И если в целом компьютерное зрение находит свое применение в крупных отраслях промышленности, то разработанное решение вполне может изменить ситуацию с ручным трудом и отслеживанием брака и в малых формах хозяйствования без потребления значительных ресурсов, что особенно актуально в условиях более жестких мер правительства по борьбе с инфляцией, когда и без того недостаточный доступ к оборотным ресрусам предпринимателей грозит значительным сокращением их общего количества.
Кроме того, обучение предлагаемой модели доказало высокую зависимость от набора данных, из которых происходит формирование исходного датасета. При дальнейшей адаптации продукта к выпуску в промышленное применение требуется дообучить модель для детекции метки «подставка», а также продумать, какие аппаратные средства целесообразно использовать для работы модели непосредственно в рамках конвейерных линий. Таким образом, формируются дальнейшие этапы для научного изыскания.
Библиографическая ссылка
Талалаев М.В. О ДЕТЕКЦИИ БРАКА НА ПРОИЗВОДСТВЕННОМ ПРЕДПРИЯТИИ С ИСПОЛЬЗОВАНИЕМ НЕЙРОСЕТЕЙ (НА ПРИМЕРЕ ООО «АЛАТОЙС») // Современные наукоемкие технологии. 2024. № 11. С. 119-125;URL: https://top-technologies.ru/en/article/view?id=40217 (дата обращения: 02.08.2026).
DOI: https://doi.org/10.17513/snt.40217