


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
METHODS OF COMPUTER HANDWRITING ANALYSIS FOR BIOMETRIC IDENTIFICATION OF USERS IN PROCTORING PROCEDURE

В эпоху цифровизации образовательного процесса дистанционное обучение и проведение аттестации в режиме онлайн приобретают все большую популярность и значимость. Важным аспектом обеспечения качества и надежности этих процессов является применение эффективных методов контроля, в том числе прокторинга. Прокторинг – это комплекс мероприятий по контролю за дистанционными экзаменами с целью предотвращения академических нарушений. В рамках прокторинга используются различные технологии и методы, включая видеонаблюдение, мониторинг активности на экране, а также анализ поведения пользователя. К последнему направлению может быть отнесены и методы биометрической идентификации, которые включают в себя процессы распознавания индивидуумов на основе одного или нескольких уникальных физиологических или поведенческих признаков. К традиционным методам относятся отпечатки пальцев, распознавание лица, голоса, сетчатки и радужки глаза. Определенного внимания заслуживает и анализ так называемого компьютерного почерка, который может предложить дополнительные возможности для проведения процедуры прокторинга в тех задачах, которые могут быть реализованы посредством выполнения заданий (предполагающий ответ в виде «печатного» текста) и тестирования (при наличии «открытых» вопросов, также предполагающих набор текста в виде ответа).
Компьютерный почерк представляет собой уникальный набор динамических и статических характеристик ввода информации посредством какого-либо устройства ввода/вывода. Например, к динамическим характеристикам ввода текста пользователем через клавиатуру (клавиатурный почерк) можно отнести скорость набора, ритм и временные интервалы между последовательными нажатиями клавиш, в то время как статические характеристики включают в себя общую точность и стабильность набора. Эти параметры формируют индивидуальный «цифровой след», который может быть использован для идентификации личности. Эффективность клавиатурного почерка как инструмента аутентификации обусловлена его способностью к выявлению и верификации уникальных поведенческих паттернов пользователя, что делает его значимым инструментом в обеспечении безопасности, особенно в условиях дистанционного обучения и проведения онлайн-тестирования.
Целями данного исследования являются сравнение моделей и методов классификации, которые могут быть использованы для анализа компьютерного почерка (на примере датасета клавиатурного почерка) с целью биометрической идентификации пользователей в контексте процедуры прокторинга, а также оценка их эффективности и точности при идентификации индивидуальных поведенческих характеристик, проявляемых в процессе ввода текста на клавиатуре.
Материалы и методы исследования
В рамках исследования были рассмотрены и сравнены три различных алгоритма классификации для анализа компьютерного почерка: метод k-ближайших соседей (k Nearest Neighbors – kNN), длинная цепь элементов краткосрочной памяти (Long short-term memory – LSTM) и сверточная нейронная сеть (Convolutional neural network – CNN).
Метод kNN – один из самых известных метрических алгоритмов классификации [1, 2] (метрический алгоритм – это алгоритм классификации, основанный на вычислении оценок сходства между объектами с помощью функции расстояния между объектами). В процессе работы алгоритма k-ближайших соседей выполняются следующие ключевые шаги [3]:
1) определение расстояния от объекта, который нужно классифицировать, до каждого элемента в обучающем наборе данных, уже помеченного определенным классом;
2) выбор k элементов из обучающего набора, для которых расстояние до целевого объекта является минимальным (выбор значения k на начальном этапе производится случайным образом, после чего оптимальное значение k подбирается итеративно на основе анализа точности предсказаний для каждого из рассмотренных значений k);
3) классификация объекта на основе наиболее часто встречаемого класса среди k ближайших соседей, где итоговая принадлежность к классу может быть выражена как в виде числового значения, так и в форме названия класса, исходя из первоначальной маркировки классов в обучающем наборе данных.
Алгоритм может использовать разные функции расстояний: евклидово расстояние, манхэттенское расстояние, расстояние Махаланобиса и т.п. В данной работе представлена реализация алгоритма на основе евклидова расстояния. Сущность данной метрики заключается в определении кратчайшего расстояния между указанными точками, выраженного в виде длины прямой, соединяющей их, вычисляемого по теореме Пифагора [4]. В общем случае для n-мерного пространства:
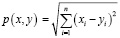
Подробнее с архитектурой алгоритма kNN и особенностями параметров можно ознакомиться в работе [5].
LSTM представляет особую разновидность архитектуры рекуррентных нейронных сетей (Recurrent neural network – RNN) для улучшения процесса обучения сети на основе длительных временных зависимостей. Эта модель была впервые представлена в 1997 году исследователями Сеппом Хохрайтером и Юргеном Шмидхубером [6]. Основная цель разработки LSTM заключалась в преодолении сложностей, связанных с изучением долгосрочных зависимостей, за счет способности сохранять информацию на различные промежутки времени – от краткосрочных до долгосрочных. Отличительной особенностью LSTM является отсутствие применения функции активации внутри рекуррентных блоков, что позволяет избежать размывания значений и исчезновения градиента в процессе обучения с использованием обратного распространения ошибок через время. Благодаря этому LSTM эффективно учится распознавать и сохранять информацию на длительные периоды, что является естественной характеристикой этой модели, а не результатом специализированного обучения [6, 7].
Первым шагом работы LSTM является определение той информации, которая должна быть исключена из состояния ячейки. Эту функцию выполняет сигмоидальный слой forget gate layer. Этот слой генерирует числа между 0 и 1 для каждого атрибута в состоянии клетки, где 1 означает полное сохранение информации, а 0 – ее полное удаление. Следующий шаг включает в себя решение о том, какая новая информация будет сохранена в клетке. На этом этапе задействованы два процесса: первый, где сигмоидальный слой input layer gate определяет, какие данные необходимо обновить, и второй, где слой tanh-слой формирует вектор кандидатов на добавление в ячейку. Заключительная часть процесса заключается в определении, какая информация будет передана на выход [7].
CNN представляет особый вид нейронных сетей прямого распространения. Под прямым распространением понимается то, что распространение сигналов по нейронам идет по порядку, от первого слоя до последнего. Скрытых слоев в сети может быть достаточно много, все зависит от количества данных и сложности задачи [8]. Функционирование сверточных нейронных сетей часто описывается как процесс перехода от специфических атрибутов данных к более обобщенным характеристикам, а затем к еще более генерализованным понятиям, достигая уровня высокоуровневых концепций. В ходе этого процесса сеть автоматически формирует необходимую иерархию абстрактных признаков, отсеивая менее значимые детали и акцентируя внимание на ключевых аспектах. Однако подобная интерпретация носит скорее метафорический или иллюстративный характер. В действительности характеристики, генерируемые этими сетями, часто оказываются настолько сложными для понимания и трактовки, что при их практическом применении часто не стремятся разобраться в их сущности или корректировать их. Вместо этого, стремясь улучшить результаты распознавания, предпочтение отдают изменению структуры и архитектуры сети. Подробное описание механизма работы сверточных нейронных сетей представлено в работе [9].
Анализ проводился на основе датасета, предоставленного Кевином Киллоури и Ройем Максионом, который содержит данные о динамике нажатия клавиш [10]. Датасет представляет собой таблицу с полями, содержащими информацию о временных метках нажатия клавиш при вводе текста [11], имена столбцов кодируют тип информации о времени: например, столбец «DD.period.t» – описывается время, от нажатия клавиши «.» до нажатия «t» (рис. 1):
− H – время от нажатия до отпускания одной клавиши;
− DD – время от нажатия одной клавиши до нажатия следующей клавиши;
− UD – время от отпускания клавиши до нажатия следующей клавиши.
Для оценки эффективности моделей использовались метрики точности (Accuracy), F1-меры и площади под ROC-кривой (ROC AUC).
Результаты исследования и их обсуждение
Для проведения исследования было использовано следующее программное обеспечение:
1) язык программирования Python, для которого существует множество библиотек работы с данными и нейронными сетями;
2) среда разработки Pycharm IDE и Google Colab.
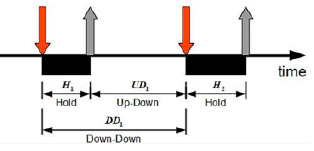
Рис. 1. Схема времени нажатия и опускания клавиши

Рис. 2. Фрагмент обучения CNN модели
Для расчетов в статье алгоритм kNN реализован посредством языка программирования Python с использованием библиотеки Scikit-learn, LSTM реализована на Python с использованием библиотеки Keras, CNN реализована на языке Python с использованием библиотек Keras и TensorFlow. Нейронные сети LSTM и CNN имели близкие настройки с целью лучшей сравнимости результатов, в частности были выбраны следующие параметры:
− количество эпох обучения = 30 (для реального использования это значение, конечно, мало, но для исследования сравнения моделей этого вполне достаточно, поскольку, чем больше эпох, тем дольше будет идти обучение);
− количество слоев модели = 5;
− функция активации = сигмоидная;
− алгоритм оптимизации = Adam;
− batch – количество сэмплов, которые необходимо взять для обновления параметров модели, было установлено в 32.
Фрагмент обучения CNN модели представлен на рисунке 2.
При исследовании весь датасет был разделен на тренировочные и тестовые данные в пропорциях 70:30 соответственно. Оценку качества моделей проводили с использованием следующих метрик [12]:
1. Accuracy – метрика, которая описывает общую точность предсказания модели по всем классам. Она рассчитывается как отношение количества правильных прогнозов к их общему количеству,
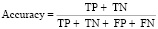 ,
,
где TP (true positive) – классификатор верно отнес объект к рассматриваемому классу, TN (true negative) – классификатор показывает, что объект не принадлежит к рассматриваемому классу, FP (false positive) – классификатор неверно отнес объект к рассматриваемому классу, FN (false negative) – классификатор неверно показывает, что объект не принадлежит к рассматриваемому классу.
2. F1-мера – среднее гармоническое между precision и recall [13]:
 =
=
=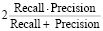 =
=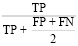 ,
,
где Recall (полнота) – показывает отношение верно классифицированных объектов класса к общему числу элементов этого класса,
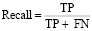 ,
,
Precision (точность) – показывает долю верно классифицированных объектов среди всех объектов, которые к этому классу отнес классификатор,
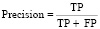
3. Кривая ROC – это график, который иллюстрирует качество работы классификационной модели. Ось X данного графика представляет собой FPR (False positive rate, частота ложноположительных результатов), а ось Y – TPR (True positive rate, частота истинно-положительных результатов). Идеальная модель классификации будет стремиться к точке в верхнем левом углу графика, где TPR равно 1, а FPR равно 0. На основе кривой ROC строится AUC – Area Under the ROC Curve. Данная мера позволяет суммировать производительность модели одним числом – площадью область под кривой ROC. Оценка AUC варьируется от 0 до 1, где 1 – идеальный показатель, а 0,5 означает, что модель выдает ответ случайно [14].
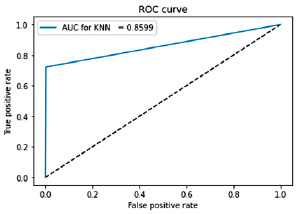
Рис. 3. График характеристики качества бинарного классификатора (ROC-AUC) для архитектуры алгоритма kNN
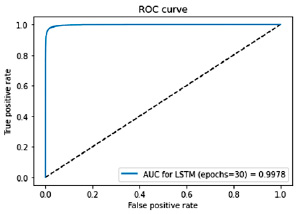
Рис. 4. График характеристики качества бинарного классификатора (ROC-AUC) для архитектуры LSTM
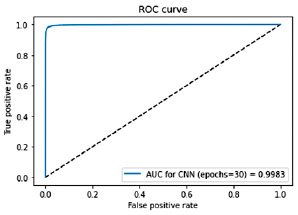
Рис. 5. График характеристики качества бинарного классификатора (ROC-AUC) для архитектуры CNN
Таблица 1
Результаты эксперимента замера метрик Accuracy, F₁-мера, ROC AUC
|
Accuracy |
F₁-мера (macro) |
ROC AUC |
|
|
kNN |
0,7221 |
0,7749 |
0,8599 |
|
LSTM |
0,8993 |
0,9301 |
0,9978 |
|
CNN |
0,9351 |
0,9779 |
0,9983 |
Результаты расчетов (табл. 1) показали, что CNN превосходит остальные алгоритмы по всем трем метрикам: Accuracy составила 0,9351, F1-мера (macro) – 0,9779, ROC-AUC – 0,9983. Метод kNN и LSTM также показали хорошие результаты, но их показатели были ниже, чем у CNN.
Графики характеристик качества бинарного классификатора (ROC-AUC) для рассматриваемых алгоритмов представлены на рисунках 3, 4, 5.
Таким образом, CNN демонстрирует наибольшую эффективность среди рассмотренных методов классификации для идентификации пользователей по компьютерному почерку, опережая метод k-NN и LSTM, обеспечивая высокую точность классификации сложных паттернов поведения в рассматриваемом сценарии. А полученные значения метрик оценки качества классификации подтверждают потенциал использования динамических и статических характеристик компьютерного почерка пользователя как надежного средства идентификации, в том числе при проведении процедуры прокторинга.
Заключение
Технология идентификации по компьютерному почерку может значительно повысить эффективность и надежность процедуры прокторинга при проведении аттестации и проверки авторства работ за счет постоянного, но в то же время «ненавязчивого» процесса идентификации аттестуемого. Сильной стороной данного метода идентификации при использовании CNN является способность достаточно точно идентифицировать пользователей на основе уникальных характеристик ввода информации. Распознавание клавиатурного почерка не требует использования дорогостоящего специализированного оборудования (конечно, для обучения нейронных сетей высокопроизводительный сервер обработки данных желателен, но для обеспечения, например, видеопотока в режиме онлайн по множеству аттестуемых вложений в инфраструктуру потребуется гораздо больше), вследствие чего цена внедрения такой системы относительно невысока. Кроме того, мониторинг клавиатурного почерка можно производить непрерывно и незаметно для пользователя, не отвлекая его внимание от проведения обучения или аттестации.
Тем не менее, внедрение такой модели в существующие системы прокторинга и онлайн-обучения сопряжено с рядом технических и организационных трудностей: необходимо организовать сбор данных, создать надежное хранилище данных с целью защиты персональных данных и конфиденциальности, собрать согласия пользователей на обработку их персональных данных и пр. Для успешного применения анализа компьютерного почерка потребуется адаптация существующих процедур обучения и аттестации (в том числе и фондов оценочных средств), чтобы обеспечить достаточность объема информации для обучения нейронных сетей.
Библиографическая ссылка
Родионов А.В., Шафаревич А.Д. МЕТОДЫ АНАЛИЗА КОМПЬЮТЕРНОГО ПОЧЕРКА ДЛЯ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЕЙ В ПРОЦЕДУРЕ ПРОКТОРИНГА // Современные наукоемкие технологии. 2024. № 5-2. С. 306-312;URL: https://top-technologies.ru/en/article/view?id=40044 (дата обращения: 02.08.2026).
DOI: https://doi.org/10.17513/snt.40044