


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
ADAPTIVE RECOMMENDATION SYSTEM FOR MEDIA SERVICES: ANALYSIS OF USER INTERACTIONS AND THEIR IMPACT ON CONTENT PERSONALIZATION

С развитием цифровых технологий и появлением новых вызовов перед организационными системами быстрое и эффективное принятие решений становится конкурентным преимуществом. В частности, рекомендательные системы играют ключевую роль в повышении эффективности и оперативности принятия решений в организациях, предлагающих подписку на медиауслуги. Эти системы, адаптируясь к предпочтениям пользователей, не только улучшают пользовательский опыт, но и способствуют более глубокому пониманию аудитории, что позволяет управляющим структурам принимать обоснованные решения о контенте, маркетинге и стратегическом планировании. В условиях жесткой конкуренции на рынке медиасервисов многие организации формируют свою стратегию развития на основе рекомендательных систем. Это позволяет не только предоставлять контент, который соответствует предпочтениям пользователей, но и существенно улучшает стратегию развития и эффективность принятия решений в организационных системах, используя управление на основе данных [1]. Более того, такие системы способствуют удержанию пользователей на платформе дольше, что ведет к увеличению доходов за счет более длительного взаимодействия аудитории с сервисом.
Современные рекомендательные системы традиционно классифицируют по типу фильтрации: коллаборативной, контентной и гибридной [2; 3]. При любом виде фильтрации строятся профили пользователей и профили информационных объектов. При коллаборативной фильтрации для построения профиля пользователя используется информация о его поведении в прошлом, например о его действиях в рамках текущей сессии [4]. Определяется схожесть поведения пользователей на основании близости их профилей, и на этом основании строится рекомендация для информационных объектов. Основными проблемами при этом виде фильтрации являются: «холодный старт», когда в системе недостаточно данных о пользователях, «новый» пользователь, на которого нет данных, и резкая смена предпочтений пользователя [3].
При контентной фильтрации пользователю рекомендуются объекты, похожие на те, которые этот пользователь уже искал. В данном случае учитывается близость профилей информационных объектов. Главными проблемами таких систем являются сильная зависимость от предметной области и ограниченность рекомендаций. Гибридные подходы сочетают коллаборативную и контентную фильтрацию, повышая точность рекомендаций [5].
Эффективность рекомендательных систем напрямую связана с их способностью адаптироваться к интересам пользователей. Поддержка концепции «релевантность и разнообразие», пертинентность, высокая точность рекомендаций и способность к быстрой адаптации к интересам пользователя являются ключевыми факторами успеха рекомендательной системы.
Одним из ключевых недостатков многих современных рекомендательных систем является тенденция к персонализации, где пользователи постоянно сталкиваются с контентом, который подтверждает их существующие взгляды и предпочтения, сужая «перспективу» разнообразия мнений и жанров. Это явление было подробно исследовано в работе [5], где автор обсуждает, как алгоритмы крупных интернет-компаний, таких как Facebook и Google, создают «фильтр-пузырь», показывая пользователем только ту информацию, которая по мнению системы, будет им интересна, основываясь на предыдущих поисковых запросах и взаимодействиях с контентом. Высказывается предположение, что такая персонализация может привести к изоляции и «замыканию» пользователей в своих интересах, негативно влияя на социальные процессы [6]. В этой связи особо актуальной является разработка рекомендательной системы, способной преодолевать ограничения традиционных алгоритмов, не только учитывая предпочтения пользователей, но и предлагая им разнообразный контент [7].
Кроме того, многие рекомендательные системы сталкиваются с проблемой недооценки учета негативных реакций пользователя, часто сосредотачиваясь на успешных взаимодействиях, в то время как негативные действия пользователя, например пропуск контента, негативная оценка, бывают недооценены или вовсе проигнорированы [8].
Целью данной работы является разработка метода и алгоритмов для работы адаптивной рекомендательной системы, которая учитывает позитивные и негативные взаимодействия пользователя с медиаконтентом и дает возможность совершенствования механизмов принятия решений в организационных системах, предоставляющих подписку на медиаконтент. Главное достоинство разрабатываемой рекомендательной системы заключается в комплексном подходе к анализу пользовательских предпочтений через извлечение и комбинирование эмбеддингов из различных типов данных, при котором формируется мультимодальное представление контекста контента, а также применение метода, который позволяет эффективно балансировать между релевантностью контента и вносить разнообразие, что позволит избежать эффекта «пузыря». Такая система предназначена не только для улучшения контентных предложений, но и включает в себя механизмы принятия управленческих решений на основе аналитики пользовательского взаимодействия. Таким образом, рекомендательная система становится инструментом для оптимизации управленческой деятельности, повышения конкурентоспособности и устойчивого развития медиасервисов.
Материал и методы исследования
Методы анализа данных, применяемые в предложенной рекомендательной системе, фокусируются на комплексной оценке пользовательских взаимодействий с контентом. Система не только отслеживает взаимодействие с контентом, но и придает каждому из событий определённый вес, разделяя их на позитивные и негативные. В статье подробно рассматривается подход к адаптации контента в рекомендательных системах, с использованием передовых методов машинного обучения. Описывается методика расчета агрегированной функции событий пользователя, которая позволяет ранжировать их по значимости. Важной частью процесса является вычисление эмбеддингов для различных типов контента: видео, аудио и текста, с использованием моделей ViFi-Clip, Whisper и BERT. Рассматриваются различные подходы к использованию этих эмбеддингов, включая композитные эмбеддинги для более точной адаптации контента. Для обеспечения релевантности и разнообразия рекомендаций применяется алгоритм DPP, а ближайший по схожести контент вычисляется на основе косинусного сходства, что способствует формированию уникальных и персонализированных рекомендаций.
Результаты исследования и их обсуждение
Процесс построения рекомендаций состоит из последовательности шагов.
Шаг 1. Описание позитивных и негативных событий в рекомендательной системе
Позитивные события:
1. Лайк контента. Когда пользователь активно выражает свое удовольствие или одобрение через механизм лайка.
2. Досмотр/прослушивание до конца. Просмотр или прослушивание контента до конца указывает на высокий интерес пользователя.
3. Глубина просмотра/прослушивания контента более N секунд. Продолжительное взаимодействие пользователя с контентом свыше установленного порога времени является для рекомендательной системы позитивным сигналом.
4. Распространение контента среди других пользователей указывает на высокую степень заинтересованности или одобрения.
5. Комментирование контента. Активное участие в обсуждении контента через комментарии может указывать на популярность или релевантность.
6. Добавление контента в избранное или закладки. Сохранение контента для будущего просмотра или использования свидетельствует о значимости его для пользователя.
Негативные события:
1. Дизлайк контента. Явное выражение неодобрения контента через механизм дизлайка.
2. Просмотр/прослушивание менее N секунд. Отказ от дальнейшего просмотра или прослушивания контента за короткий промежуток времени может указывать на низкий интерес.
3. Пропуск контента. Если пользователь пролистывает контент без остановки, это может свидетельствовать о его нерелевантности или непривлекательности.
4. Удаление контента из избранного или закладок может указывать на изменение интересов или разочарование в ранее сохраненном контенте.
Шаг 2. Определение исходных весов для событий в рекомендательной системе
В такой рекомендательной системе важно установить веса для различных типов событий при взаимодействии пользователя с контентом. Установка этих весов осуществляется на основе анализа предпочтений и поведения пользователей, а также зависит от конкретной платформы или контекста использования. В целом исходные события могут быть заданы с помощью:
1) привлечения экспертов в области рекомендательных систем или предметной области для оценки значимости различных типов взаимодействий и предложения начальных весов;
2) использования методов анализа данных для изучения распределения различных типов взаимодействий в истории пользовательских действий;
3) проведения эмпирических исследований с привлечением пользователей для оценки эффективности различных весов и определения наиболее подходящих значений на основе предпочтений пользователей;
4) использования итеративного подхода к установлению весов, который позволяет рекомендательной системе адаптироваться к изменяющимся предпочтениям пользователей в процессе их взаимодействия с платформой.
Важным этапом в такой рекомендательной системе является оптимизация и настройка установленных весов на основе регулярного мониторинга и анализа метрик рекомендательной системы.
Шаг 3. Сбор данных о взаимодействиях пользователя с контентом
Сбор данных о взаимодействиях пользователя с контентом является критически важным этапом для работы рекомендательной системы и включает несколько ключевых этапов.
1. Система идентифицирует пользователей по их роли на платформе, различая, например, авторизованных и неавторизованных пользователей, используя уникальные идентификаторы устройств, что позволяет рекомендательной системе адаптировать персональные предложения в зависимости от уровня доступа и персонализированных настроек каждого пользователя. Идентификация по уникальным идентификаторам также способствует отслеживанию поведенческих паттернов пользователей на разных устройствах.
2. Система отслеживает и записывает все типы взаимодействий пользователя с контентом в разрезе последних N взаимодействий. С каждым взаимодействием система записывает дополнительные метаданные, такие как отметка времени события, источник взаимодействия (например, определенный раздел или категория на медиаплатформе), и уникальный идентификатор контента. Эти данные помогают анализировать контекст взаимодействия и учитывать его при формировании рекомендаций.
3. Система сопоставляет уникальные идентификаторы пользователей, обеспечивая непрерывность истории взаимодействий, например при изменении устройств или выходе из учетной записи.
Шаг 4. Расчет агрегированной функции событий пользователя
Расчет агрегированной функции событий является ключевым компонентом рекомендательной системы, поскольку позволяет количественно оценить взаимодействия пользователя с контентом и в дальнейшем ранжировать их, этот процесс также включает несколько этапов.
1. Система анализирует последние N взаимодействий пользователя с контентом для вычисления агрегированной функции, это позволяет учесть как краткосрочные интересы пользователя, так и долгосрочные.
2. Система учитывает временные тренды во взаимодействии пользователя с контентом. Таким образом, недавние взаимодействия пользователя получат больший вес в общем расчете.
3. Система рассчитывает «итоговый счет» как сумму взвешенных событий, умноженную на коэффициент экспоненциального затухания по времени по формуле:
Итоговый счет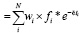
где wi – вес события, fi – частота события во всем наборе данных, e–λti – коэффициент экспоненциального затухания (e – основание натурального логарифма, λ – параметр затухания, t – время, прошедшее с момента события).
Эта функция позволяет уменьшить влияние старых взаимодействий на рекомендации и поддерживать актуальность предложений. Агрегированная функция является универсальной, в том числе и для негативных событий, поскольку предполагается, что негативные события будут иметь отрицательный вес, и итоговый счет для таких событий будет отрицательным.
Шаг 5. Извлечение эмбеддингов из контента
Извлечение эмбеддингов – это процесс представления объектов (текста, изображений, видео, аудио) в числовую форму таким образом, чтобы сохранить информацию о характеристиках и взаимосвязях исходных данных в компактной форме. Таким образом, рекомендательная система использует эмбеддинги, чтобы эффективно обрабатывать и сравнивать большие объёмы контента, улавливая сходства и различия на основе семантики, визуальных и аудиохарактеристик, что в дальнейшем позволит системе предлагать пользователю контент, который наиболее релевантен его интересам. Для каждого типа контента используются специализированные методы.
Процесс извлечения эмбеддингов для видеоконтента реализуется с помощью модели ViFi-CLIP, адаптированной к особенностям видеоданных [9]. Аудиоданные обрабатываются начиная с препроцессинга аудиодорожки и транскрибации при помощи модели Whisper, после чего следует процесс постобработки, аналогичный созданию текстовых эмбеддингов [10-12]. Для наглядного представления детальное описание алгоритма извлечения эмбеддингов для видео, аудио и текстового контента представлено на прилагаемом рисунке. Совокупность этих методов позволяет создавать мультимодальные эмбеддинги, которые в дальнейшем обогащают рекомендательную систему более глубоким пониманием содержания и контекста контента.
Шаг 6. Использование эмбеддингов в рекомендательной системе
Полученные эмбеддинги из различных типов контента могут быть использованы в рекомендательной системе разными способами, что позволяет улучшить точность и релевантность предложений пользователю.
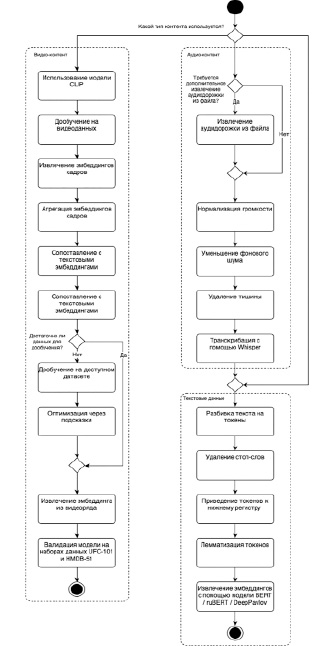
Алгоритм извлечения эмбеддингов из различного типа контента
В рамках этой статьи предлагается использование нескольких подходов – использование отдельных эмбеддингов и использование композитного эмбеддинга.
При использовании подхода с отдельными эмбеддингами система применяет эмбеддинги, полученные независимо для видео, аудио и текстовых описаний.
• Видео: система использует эмбеддинг видео для поиска других видео, которые близки к тем (визуальным содержанием или стилем), с которыми пользователь ранее положительно взаимодействовал.
• Аудио: аналогично видео, эмбеддинги аудио используются для поиска видео или аудио с близкими аудиопараметрами, например схожие музыкальные треки, диалоги или звуковые эффекты.
• Текстовое описание: для контента, который имеет сопровождающие текстовое описание, эмбеддинги этих описаний используются для нахождения контента с похожими темами или ключевыми словами.
После отдельного поиска по каждому типу эмбеддингов контента рекомендательная система формирует несколько списков кандидатов, которые далее могут быть дополнительно обработаны для формирования конечных рекомендаций.
Для более глубокой интеграции различных типов контента система может использовать композитный эмбеддинг, который объединяет информацию из видео, аудио и текстового описания:
• перед объединением система применяет L2-нормализацю к эмбеддингам видео, аудио и текста, чтобы привести их к сопоставимому масштабу;
• далее рекомендательная система рассчитывает итоговую меру близости как взвешенную сумму отдельных мер близости, где каждая из компонент – видео, аудио и текст – умножается на предварительный коэффициент важности:
Итоговая мера близости = близость видео × к1+
+ близость аудио × к2 + близость текста × к3.
Такой подход позволяет рекомендательной системе предлагать контент, который более комплексно близок к интересам и предпочтениям пользователя.
Шаг 7. Отбор контента с использованием алгоритма DPP
Процесс отбора контента в рекомендательной системе включает несколько этапов, используется алгоритм Determinantal Point Process (DPP) для обеспечения релевантности и разнообразия рекомендаций [13].
Система сначала ранжирует события по убывающему итоговому счету. Затем из этого списка выбираются наиболее «перспективные» события для передачи на вход алгоритму DPP. Используя матрицу сходства, алгоритм оценивает разнообразие контента и определяет вероятности выбора подмножеств, приоритизируя те, что обеспечивают максимальное разнообразие и релевантность. Итоговые значения модифицируются для улучшения точности финальных рекомендаций.
Шаг 8. Поиск наиболее подходящего контента
После отбора разнообразного контента с использованием алгоритма DPP рекомендательная система формирует список контента, который был положительно оценен пользователем, и переходит к следующему шагу – поиску наиболее подходящего контента.
1. Для каждого элемента контента из этого списка система вычисляет меру близости с каждым контентом из общей базы данных. Это позволяет определить наиболее похожие и потенциально интересные рекомендации для пользователя. Мера близости вычисляется с помощью косинусного сходства между двумя векторами (эмбеддингами) по формуле:
Мера близости 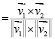
где в числителе скалярное произведение векторов эмбеддингов контента 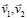 , а в знаменателе
, а в знаменателе 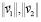 нормы этих векторов.
нормы этих векторов.
2. На основе рассчитанных мер сходства рекомендательная система формирует список наиболее похожего контента из базы данных, который затем предлагается пользователю.
В конечном итоге этот подход обеспечивает эффективный и точный механизм рекомендаций пользователю на платформе, учитывая предыдущие взаимодействия пользователя с контентом, с одной стороны, и способствуя поддержанию его вовлеченности в новый контент – с другой.
Заключение
В настоящей статье был предложен и теоретически обоснован подход к созданию адаптивной рекомендательной системы, способной учитывать как позитивные, так и негативные взаимодействия пользователей с контентом. Центральной частью такого подхода является использование мультимодальных эмбеддингов, полученных из видео, аудио и текстовых данных, что позволяет системе формировать более точные и персонализированные предложения. С помощью внедрения алгоритма DPP (Determinantal Point Process) такая рекомендательная система не только улучшает актуальность рекомендаций, но и обогащает их разнообразием, избегая формирования «фильтр-пузырей», которые могут ограничивать информационное разнообразие и влиять на формирование мнений пользователей.
Таким образом, предложенный подход к разработке рекомендательных систем открывает новые перспективы для улучшения управленческих процессов в медиасервисах. Подобные системы позволяют организациям лучше понимать потребности своих пользователей и более точно прогнозировать изменения в их интересах, что способствует улучшению стратегического планирования, тем самым укрепляет позиции компании на конкурентном рынке медиаиндустрии.
Библиографическая ссылка
Фазульянов Д.В., Гусева А.И. АДАПТИВНАЯ РЕКОМЕНДАТЕЛЬНАЯ СИСТЕМА ДЛЯ МЕДИАСЕРВИСОВ: АНАЛИЗ ПОЛЬЗОВАТЕЛЬСКИХ ВЗАИМОДЕЙСТВИЙ И ИХ ВЛИЯНИЕ НА ПЕРСОНАЛИЗАЦИЮ КОНТЕНТА // Современные наукоемкие технологии. 2024. № 5-1. С. 82-88;URL: https://top-technologies.ru/en/article/view?id=40009 (дата обращения: 01.08.2026).
DOI: https://doi.org/10.17513/snt.40009