


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
SEMANTIC SEGMENTATION OF TEXT FIELDS AND TABLES IN A DOCUMENT BASED ON THE UNETFORMER ARCHITECTURE

В настоящее время системы оптического распознавания текста обладают широким спектром функциональных применений, включая возможность интеграции в системы автоматизированного документооборота. Кроме того, данные системы могут использоваться для автоматизации создания форм документов в случаях, когда отсутствует исходный файл, а также для автоматизированного извлечения необходимых данных из фотографий или отсканированных изображений документов [1]. Обычно система оптического распознавания текста включает в себя два основных модуля [2]: сегментации текстовых строк в документе и распознавания детектированных строк, то есть преобразования изображения в текстовую строку.
Задача сегментации текстовых строк в документе является ключевым этапом в области оптического распознавания текста. Разработка эффективных методов для решения этой задачи представляет собой обязательное условие для обеспечения высокой точности и производительности системы распознавания текста.

Рис. 1. На верхнем изображении – пример работы MultiplexedOCR [5], красные рамки – найденные алгоритмом текстовые строки, зеленые – текст, распознанный системой. На нижнем изображении – пример работы алгоритма, предлагаемого авторами, зеленые рамки – найденные текстовые строки, красные рамки – разделение текстовых строк на отдельные слова
Существует множество подходов для решения данной задачи, основанных как на алгоритмах компьютерного зрения, например smearing [3], так и методах с использованием нейронных сетей [4]: например, в работе Ц. Хуана [5] и в статье М. Буста, Л. Неймана и Дж. Мэйтаса [6] для детекции текста на изображении используется подход с использованием нейронных сетей. Эти решения не обладают достаточным качеством сегментации строк на собранных авторами данных (далее датасет Nexus): возникают ложноположительные срабатывания на дефекты печати и сканирования, ложноотрицательные срабатывания на ориентациях, отличных от нормальной. К системе предъявляются высокие требования качества распознавания, поэтому подобные ошибки имеющихся решений неприемлемы. Существующие системы имеют еще один существенный недостаток: они не способны определять ориентацию строк (например, текст, повернутый на 90 градусов), что ведет к ошибке в OCR. Сравнение работы на датасете Nexus алгоритма MultiplexedOCR [5] и предлагаемого авторами можно увидеть на рис. 1. Собранный датасет имеет следующую специфику: строки в пределах одного документа могут иметь разную ориентацию, имеются наложения рукописного текста и печатей поверх таблиц и печатного текста.
Эффективное определение позиции и размера текстовых областей непосредственно влияет на качество всей системы оптического распознавания текста. Неверное определение текстовой области приводит к падению точности распознавания текста, к нему можно отнести:
1) недовыделение текста;
2) выделение как текста объекта, не являющегося текстом;
3) «срастание» выделенных областей текста.
Поэтому повышение эффективности методов семантической сегментации документов играет решающую роль в обеспечении успешного функционирования системы оптического распознавания текста.
В работе предлагается метод решения вышеизложенных проблем, основанный на подходе с использованием архитектуры UNetFormer. Эта архитектура направлена на повышение эффективности и точности в задачах семантической сегментации спутниковых снимков [7] и медицинских изображений [8]. Целью этого исследования является решение задачи семантической сегментации документов на основе архитектуры UNetFormer.
Материалы и методы исследования
Архитектура решения
Для решения задачи используется архитектура UNetFormer на базе предобученного ResNet-18 в качестве энкодера и декодера с блоками Global Local Attention. Известные архитектуры нейронных сетей для решения задачи семантической сегментации, основанные на сверточных слоях, такие как SegNet [9], UNet [10], имеют ограниченное рецептивное поле, поэтому они извлекают только признаки ближнего контекста, игнорируя или слабо реагируя на признаки, находящиеся вне зоны рецептивного поля. Из-за этого существенного недостатка могут пропадать недостаточно контрастные строки и линии таблиц. Блоки Global Local Attention помогают модели извлекать также признаки дальнего контекста, что приводит к существенному росту качества семантической сегментации, что и показывают в статье, посвященной архитектуре UNetFormer [7]. Модель возвращает N карт сегментации по количеству классов. То есть выходной тензор имеет размерность
(B, N, H, W),
где B – размер батча, N – число семантических классов, H, W – высота и ширина входного изображения соответственно. Каждая карта размерности (B, 1, H, W) – батч бинарных изображений, соответствующих положению объектов присущего этой карте класса на исходных изображениях. В нашем случае число классов N = 7:
1) текст, ориентированный горизонтально (0 градусов);
2) текст, повернутый на 90 градусов по часовой стрелке;
3) текст, повернутый на 90 градусов против часовой стрелки;
4) текст, повернутый на 180 градусов;
5) узлы таблиц;
6) ребра таблиц;
7) ядра строк – тонкие линии, проведенные через середину строки вдоль направления текста (рис. 4).
В отличие от статьи [7] карта фона (специальный класс для пикселей, не принадлежащих ни одному из семантических классов) не используется.
Подобное разбиение на классы позволяет определить ориентацию каждого текстового поля на этапе сегментации и повернуть вырезанный прямоугольник с текстом на необходимый угол при подаче на вход системе распознавания текста. Также данное разбиение позволяет определить позицию и структуру таблиц, а также ориентацию страницы документа в целом.
Функция потерь и оптимизатор
В качестве функции потерь была выбрана комбинированная функция:
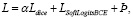 (1)
(1)
основанная на работе [7], адаптированная под задачу добавлением слагаемого Ϸ, где α = 0.4, а составляющие функции потерь определяются как
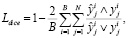 (2)
(2)
где 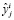 – предсказанная моделью карта для i-го сэмпла и j-го класса,
– предсказанная моделью карта для i-го сэмпла и j-го класса, 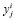 – маска i-го сэмпла и j-го, класса, ∧ – операция поэлементного логического «и», ∨ – операция поэлементного логического «или».
– маска i-го сэмпла и j-го, класса, ∧ – операция поэлементного логического «и», ∨ – операция поэлементного логического «или».
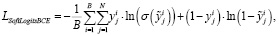 (3)
(3)
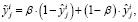 (4)
(4)
где β – сглаживающая константа.
С целью уменьшения «срастания» строк было добавлено слагаемое в функцию потерь:
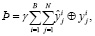
где ⊕ – операция поэлементного XOR, а γ = 14. Это слагаемое позволяет дополнительно штрафовать модель за расхождение с целевым тензором. Задача минимизации L → min решалась оптимизатором Adam [11] с различными скоростями обучения для энкодера и декодера: 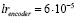 ,
, 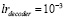 .
.
Подход к обучению и аугментации данных
На вход модели подавались трехканальные изображения разрешением 1024х1024, то есть тензор размерности (B, 3, 1024, 1024), тензор ожидаемых масок имеет размерность (B, 7, 1024, 1024). Схема подготовки обучающих данных представлена на рис. 2.
Все эти действия происходят в реальном времени, то есть генерация изображений происходит непосредственно во время обучения модели. Предложенный подход позволяет создать разнообразие данных, подаваемых модели и увеличить ее обобщающую способность, что положительно сказывается на качестве обучения и предотвращает переобучение. Пример входных данных и масок для них по классам можно увидеть на рис. 3.
Решение проблемы пересечения строк
При использовании обученной модели обнаружилась проблема «срастания» («срастание» или пересечение строк – вид ошибки, при котором n строк определяются алгоритмом сегментации строк как одно целое) находящихся близко строк, возникающая из-за ошибок в разметке датасета, а также за счет ошибок самой модели сегментации.
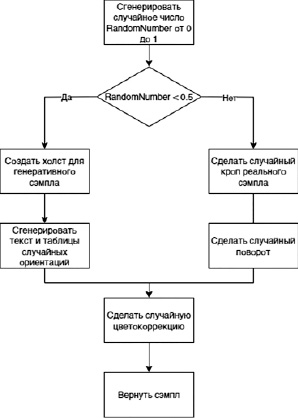
Рис. 2. Схема генерации сэмплов для обучения и валидации модели
«Срастание» строк приводит к неправильной вырезке текстовых прямоугольников, а далее к неверному распознаванию текста в вырезанных областях. Для решения этой проблемы используются два подхода: дополнительная карта, о которой написано выше – карта ядер строк и дополнительном слагаемом в функции потерь. Комбинированный подход позволяет избежать большинства проблем при распознавании текста, связанных с такой особенностью работы модели сегментации. Пример разделения пересекающихся строк можно увидеть на рис. 4.
Результаты исследования и их обсуждение
Для вычисления метрик качества обученной модели используются не попавшие в тренировочную выборку, а также генерируемые в реальном времени данные. Ключевая метрика качества модели для нашего исследования – mIoU (средний индекс Жаккара). Также важным является индекс Жаккара для каждого класса отдельно. Значения для этих метрик приведены в таблице.
Высокие значения этих метрик обусловлены самой архитектурой выбранной модели, поскольку UNetFormer учитывает как локальный (ближний), так и дальний контекст. Не последнюю роль играет количество и разнообразие данных. Предложенный подход к обучению позволяет постоянно подавать модели новые данные для обучения, что положительно сказывается на работе модели в реальных условиях на неизвестных ранее данных.
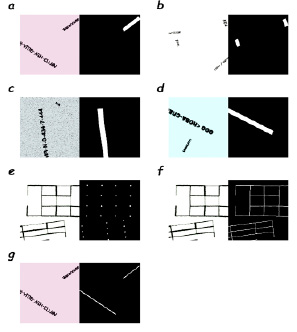
Рис. 3. Сгенерированные изображения и маски для обучения. Пары входное изображение – маска: a – строк горизонтальной ориентации текста (0 градусов), b – строк, повернутых на 90 градусов по часовой стрелке, c – строк, повернутых на 90 градусов против часовой стрелки, d – строк, повернутых на 180 градусов, e – узлов таблиц, f – ребер таблиц, g – ядер строк

Рис. 4. Пример разделения пересекающихся строк на карте сегментации с помощью карты ядер строк. Серым цветом изображен результат сегментации текстовых строк нормальной ориентации, фиолетовым – результат сегментации ядер строк. Синие рамки вокруг текста – определенные алгоритмом текстовые строки
Метрики обученной модели на тестовых данных
|
Метрика |
Значение |
|
mIoU |
0,833 |
|
IoU для карты нормальной ориентации |
0,895 |
|
IoU для карты ориентации 90 градусов по часовой стрелке |
0,886 |
|
IoU для карты ориентации 90 градусов против часовой стрелки |
0,887 |
|
IoU для карты ориентации 180 градусов |
0,894 |
|
IoU для карты узлов таблиц |
0,798 |
|
IoU для карты ребер таблиц |
0,741 |
|
IoU для карты ядер строк |
0,730 |

Рис. 5. Результат сегментации моделью; a – входное изображение, b – карта горизонтальной ориентации текста, c – карта текста, повернутого на 90 градусов по часовой стрелке, d – карта текста, повернутого на 90 градусов против часовой стрелки, e – карта текста, повернутого на 180 градусов, f – карта ядер строк
Важным достоинством модели является скорость предсказания: 8–12 мс при размере входного изображения 6 мегапикселей на графическом процессоре Nvidia RTX 3080Ti. Примеры работы модели сегментации на реальных документах можно увидеть на рис. 5.
Заключение
В статье показана возможность эффективного применения архитектуры UNetFormer в задаче детекции текстовых полей с учетом их ориентации и таблиц в документах, и подход к решению такой задачи. Для любой системы OCR детекция текста является одной из подзадач, которую требуется решить для построения системы. Документы, обрабатываемые такими системами, могут иметь особенности: таблицы, текст, имеющий ориентацию, отличную от нормальной, близко расположенный текст, наложения объектов друг на друга, тени, печати. Разработанная система способна распознавать все возможные ориентации текста и таблицы, что позволяет избежать проблем неверного распознавания текста из-за ошибки в определении ориентации, а также сохранять информацию о структуре документа (положении текстовых полей, таблицах).
UNetFormer показывает высокие значения метрики Жаккара в задаче семантической сегментации документов, значит, можно сделать вывод о том, что модель подходит для решения такой задачи.
Библиографическая ссылка
Климов А.М., Котюжанский Л.А., Четверкин Н.В. СЕМАНТИЧЕСКАЯ СЕГМЕНТАЦИЯ ТЕКСТОВЫХ ПОЛЕЙ И ТАБЛИЦ В ДОКУМЕНТЕ НА ОСНОВЕ ПРИМЕНЕНИЯ АРХИТЕКТУРЫ UNETFORMER // Современные наукоемкие технологии. 2024. № 3. С. 49-55;URL: https://top-technologies.ru/en/article/view?id=39945 (дата обращения: 23.07.2026).
DOI: https://doi.org/10.17513/snt.39945