


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
PREDICTIVE MODELS IN BRAIN’S MRI: THE SAMPLE SIZE DEFINITION ON DEEP LEARNING MODEL

Различные отклонения в области головного мозга составляют примерно 85–90 % от общего количества патологий центральной нервной системы [1, с. 114–123]. В этой связи вопрос улучшения диагностики при проведении МРТ должен быть реализован с целью качественного улучшения дальнейшей жизни наблюдаемых.
Специалист, читающий МРТ-снимки, должен принимать решения, основываясь лишь на своем наблюдении отклонений. Так, опухоли на снимке МРТ выделены светлыми, ассиметричными пятнами с нарушенными границами. При инсульте (ишемии головного мозга) образуется область кислородного голодания светлого цвета с выделением мозговых артерий. При рассеянном склерозе накапливаются осветленные области очагового характера, концентрация которых зависит от стадии заболевания. При сосудистых заболеваниях: при аневризме расширяются и истончаются стенки артерий; при атеросклерозе – сужаются просветы артерий из-за наличия закупоривающих бляшек [2, с. 83]. И все это специалист должен уметь уловить собственным взглядом.
Несомненно, факт человеческой ошибки при определении различных патологий головного мозга крайне велик, поскольку при сканировании методом МРТ генерируется значительное количество снимков (информации). Человек не всегда способен уловить малейшие отклонения, возникающие на снимках ввиду высокой сложности и разнообразности таких отклонений и их свойств.
С учетом все большего накопления цифровых данных в этой области, а также поступательного развития современных графических процессоров становится возможным применение методов машинного и глубинного обучения для построения различного рода предсказательных моделей поведения головного мозга. Более того, данные методы зачастую показывают гораздо более высокую эффективность и точность предсказаний по сравнению с теми решениями, которые принимаются человеком.
Материалы и методы исследования
В рамках исследования использованы следующие данные (датасеты): HCP [3], ABIDE I + II (spac) [4]. Данные датасеты являются открытыми.
Датасет HCP содержит 1113 наборов данных от людей со структурными МРТ. Данные представлены от 507 мужчин и 606 женщин. Датасет был преобразован в трехмерные изображения размером 58х70х58 точек. Для визуализации данных использовалась библиотека nilearn.
Датасет ABIDE I представлен в августе 2012 г. и содержит 1112 наборов данных, в том числе 539 – от людей с проявлениями аутизма и 573 – от здоровых людей, подвергшихся периодическому контролю (в возрасте от 7 до 64 лет, в среднем 14,7 лет в разрезе групп). Кроме того, представлены метки о гендерной принадлежности снимка головного мозга.
В датасет ABIDE II дополнительно добавлено более 1 тыс. сэмплов. Релиз был представлен в июне 2016 г. и включал 1114 наборов данных от 521 чел. с проблемами аутизма и 593 контрольных лиц (возрастной диапазон от 5 до 64 лет). Также есть признаки с гендерной принадлежностью.
Общий датасет ABIDE I + II (spac) представлен 2122 сэмплами, сжатыми до размерности 45х54х45. Для визуализации также использовалась библиотека nilearn, метод new_img_like.
Можно предположить, что в ABIDE I+II были учтены результаты исследований, основанных на датасете HCP, и часть «ненужной» информации, хранящейся в изображении, но не оказывавшей существенного влияния на поведение предсказательной модели, была исключена из изображений с целью экономии данных и, как следствие, более быстрого обучения, валидации и тестирования модели.
Первым этапом в части подготовки данных стало написание класса MriData, который на входе принимает объекты X и Y и преобразует их в torch.tensor. Кроме того, осуществлены стандартные функции, возвращающие длину входящего тензора X, а также сэмплы X и Y по конкретному индексу.
На втором этапе была написана функция, которая итерационно разделяет датасет на train- и test-выборки. Первично в train-выборке оказываются 100 сэмплов. Впоследствии на каждой итерации к ним прибавляется по 100 сэмплов. Количество итераций – 10. Таким образом, общее количество сэмплов в train-выборке достигает 1 тысячи.
Размер батча, загружаемого в dataloader: для train-выборки – 45, для test-выборки – 28.
В качестве лосса использован nn.NLLLoss, в качестве оптимизатора – Адам с lr = 3e-4, в качестве шедулера – MultiStepLR с гиперпараметрами milestones = [5, 15], gamma = 0.1, в качестве метрики – Roc_Auc_Score или Accuracy.
Количество эпох в рамках обучения = 20.
Для подсчета Roc_Auc_Score по каждой из итераций, увеличивающих общий размер train-выборки, использовались средние значения по 20 эпохам обучения.
Для визуализации полученных результатов использовалась библиотека matplotlib.
Результаты исследования и их обсуждение
Обычно используемые структуры сверточных нейронных сетей основаны на двумерных изображениях. При использовании 2D CNN для обработки 3D-изображений МРТ нам необходимо сопоставить исходное изображение с разных направлений, чтобы получить 2D-изображения, которые будут терять информацию о пространственной структуре изображения. В нашей работе мы использовали разработанную трехмерную сверточную нейронную сеть с трехмерными сверточными ядрами, что позволило нам извлечь трехмерные структурные особенности из изображений. Кроме того, традиционная модель CNN обычно использует несколько полносвязных слоев для соединения скрытых слоев и выходного слоя. Полносвязный слой может быть подвержен проблеме чрезмерной подгонки в двоичной классификации, когда количество выборок ограничено. Чтобы решить эту проблему, в предложенной архитектуре использован линейный слой для замены полносвязного. Линейный слой объединяет выходные данные скрытых слоев (т.е. 3D-матрицу, состоящую из нескольких карт признаков) во входные данные (т.е. 1D-вектор) выходного слоя, который является классификатором softmax. Кроме того, архитектурой предусмотрена батч-нормализация после каждой операции свертки. Она используется во избежание проблемы внутреннего ковариантного сдвига при обучении модели. Таким образом, разработанная 3D PCNN состоит из трех скрытых слоев, линейного слоя и слоя softmax. Каждый скрытый слой содержит сверточный слой, слой батч-нормализации, слой активации, пулинговый слой с несколькими картами функций в качестве выходных данных [5]. Архитектура сетки представлена на рис. 1. Кроме того, после каждого сверточного слоя был применен дропаут в размере 0,2 (получен опытным путем). Таким образом, отбрасывая 20 % полученных весов, мы практически не теряем в качестве модели, экономя ресурсы и оптимизируя сам процесс обучения. Причем использование дропаута возможно на любой из стадий работы сверточной сети: как, например, после самой свертки, так и после применения функции активации или пулинга.
Summary полученных моделей для датасетов HCP, а также ABIDE I+II представлено на рис. 2.
В рамках исследования было проведено 12 экспериментов. Параметры экспериментов и полученные результаты представлены ниже.
Параметры эксперимента № 1:
- датасет: HCP;
- train = 80 % выборки;
- test = 20 % выборки;
- метрика: Roc_Auc_score.
Полученные результаты на train и test представлены на рис. 3.
Параметры эксперимента № 2:
− датасет: HCP;
− train = 80 % выборки;
− test = 20 % выборки;
− метрика: Accuracy.
Полученные результаты на train и test представлены на рис. 4.
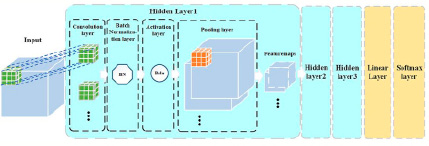
Рис. 1. Архитектура сверточной нейронной сети, используемой в модели
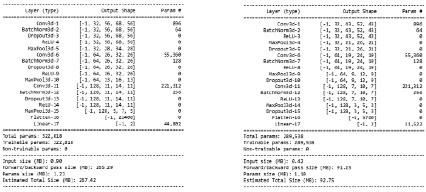
Рис. 2. Summary полученных моделей для датасетов HCP, а также ABIDE I+II
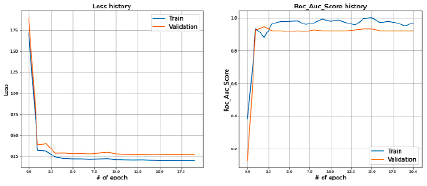
Рис. 3. Значения Loss и ROC_AUC_SCORE при сплите датасета в 80 и 20 %
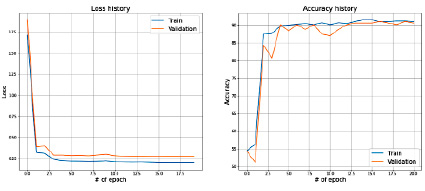
Рис. 4. Значения Loss и Accuracy при сплите датасета в 80 и 20 %
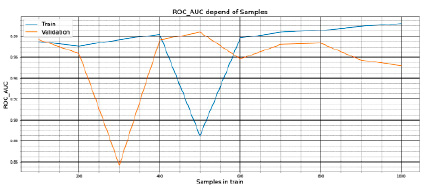
Рис. 5. Значения ROC_AUC_SCORE в зависимости от размера выборки в train
Параметры эксперимента № 3:
− датасет: HCP;
− train: от 100 до 1000 сэмплов с шагом в 100 сэмплов;
− метрика: Roc_Auc_score.
Полученные результаты на train и test представлены на рис. 5.
Параметры эксперимента № 4:
− датасет: HCP;
− train: от 100 до 1000 сэмплов с шагом в 100 сэмплов;
− метрика: Accuracy.
Полученные результаты на train и test представлены на рис. 6.
Параметры эксперимента № 5:
− датасет: ABIDE I + II (несбалансированный);
− количество сэмплов: 2122;
− train = 80 % выборки;
− test = 20 % выборки;
− метрика: Roc_Auc_score.
Полученные результаты на train и test представлены на рис. 7.
Параметры эксперимента № 6:
− датасет: ABIDE I + II (несбалансированный);
− количество сэмплов: 2122;
− train = 80 % выборки;
− test = 20 % выборки;
− метрика: Accuracy.
Полученные результаты на train и test представлены на рис. 8.
Параметры эксперимента № 7:
− датасет: ABIDE I + II (несбалансированный);
− количество сэмплов: 2122;
− train: от 100 до 1000 сэмплов с шагом в 100 сэмплов
− метрика: Roc_Auc_score.
Полученные результаты на train и test представлены на рис. 9.
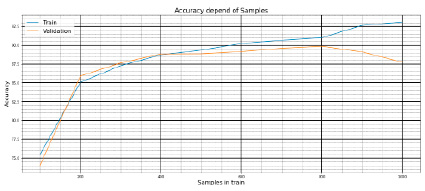
Рис. 6. Значения Accuracy в зависимости от размера выборки в train
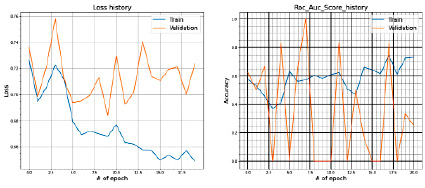
Рис. 7. Значения Loss и ROC_AUC_SCORE при сплите датасета в 80 и 20 %
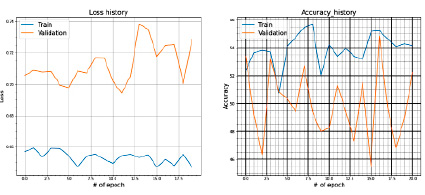
Рис. 8. Значения Loss и Accuracy при сплите датасета в 80 и 20 %
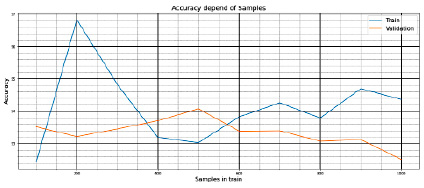
Рис. 9. Значения ROC_AUC_SCORE в зависимости от размера выборки в train
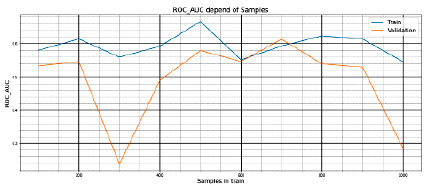
Рис. 10. Значения Accuracy в зависимости от размера выборки в train
Параметры эксперимента № 8:
− датасет: ABIDE I + II (несбалансированный);
− количество сэмплов: 2122;
− train: от 100 до 1000 сэмплов с шагом в 100 сэмплов
− метрика: Accuracy.
Полученные результаты на train и test представлены на рис. 10.
Параметры эксперимента № 9:
− датасет: ABIDE I + II (сбалансированный);
− количество сэмплов 842;
− train = 80 % выборки;
− test = 20 % выборки;
− метрика: Roc_Auc_score.
Полученные результаты на train и test представлены на рис. 11.
Параметры эксперимента № 10:
− датасет: ABIDE I + II (сбалансированный);
− количество сэмплов 842;
− train = 80 % выборки;
− test = 20 % выборки;
− метрика: Accuracy.
Полученные результаты на train и test представлены на рис. 12.
Параметры эксперимента № 11:
− датасет: ABIDE I + II (сбалансированный);
− количество сэмплов 842;
− train: от 100 до 700 сэмплов с шагом в 100 сэмплов;
− метрика: Roc_Auc_score.
Полученные результаты на train и test представлены на рис. 13.
Параметры эксперимента № 12:
− датасет: ABIDE I + II (несбалансированный);
− количество сэмплов 842;
− train: от 100 до 700 сэмплов с шагом в 100 сэмплов;
− метрика: Accuracy.
Полученные результаты на train и test представлены на рис. 14.
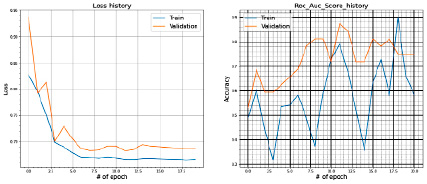
Рис. 11. Значения Loss и ROC_AUC_SCORE при сплите датасета в 80 и 20 %
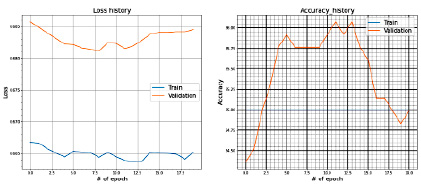
Рис. 12. Значения Loss и Accuracy при сплите датасета в 80 и 20 %
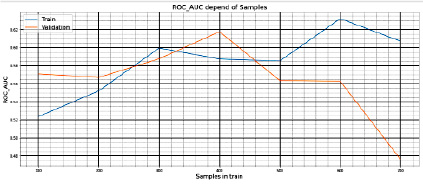
Рис. 13. Значения ROC_AUC_SCORE в зависимости от размера выборки в train
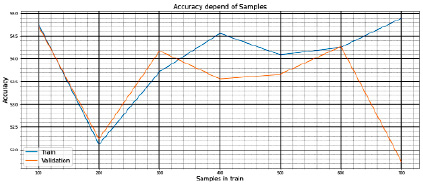
Рис. 14. Значения Accuracy в зависимости от размера выборки в train
Заключение
По результатам проведенных экспериментов можно сделать следующие выводы:
1. Для датасета HCP:
1.1. Датасет является более сбалансированным с точки зрения наличия признаков.
1.2. Предложенная модель хорошо обучается.
1.3. Лосс ведет себя предсказуемо.
1.4. Метрики качества (Roc_Auc_Score и Accuracy) ~ 90 %, что говорит о высокой точности модели.
1.5. Оптимальные значения качества начинаются при выборке в 200–800 сэмплов при метрике качества Accuracy, 400–800 сэмплов – при метрике качества Roc_Auc_Score.
2. Для датасета ABIDE I+II (несбалансированный):
2.1. Предложенная модель плохо отрабатывает и на train- и на test-выборках.
2.2. Лосс непредсказуем.
2.3. Более предсказуемо ведет себя метрика Accuracy.
2.4. Наибольшие значения качества наблюдаются при выборке в 200–900 сэмплов при метрике качества Accuracy, 400–900 сэмплов – при метрике качества Roc_Auc_Score.
3. Для датасета ABIDE I+II (сбалансированный):
3.1. Предложенная модель лучше отрабатывает и на train-, и на test-выборках, чем несбалансированный датасет.
3.2. Лосс более предсказуем, чем на несбалансированном датасете, но значения сохраняются на высоком уровне по сравнению с датасетом HCP.
3.3. Более предсказуемо ведет себя метрика Roc_Auc_Score.
3.4. Наибольшие значения качества наблюдаются при выборке в 200–600 сэмплов при метрике качества Accuracy, 200–500 сэмплов – при метрике качества Roc_Auc_Score.
Подводя итоги, стоит отметить, что проведенные исследования подтверждают возможность получения схожих по качественным метрикам результатов на меньших объемах тренировочных данных, что имеет несомненное практическое значение при обучении моделей машинного и глубинного обучения. Работа с объемом выборки позволяет (по результатам исследований) получить более чем 2-кратную экономию времени при тренировке нейросети, а в некоторых случаях – 5-кратное сокращение по времени, что повышает общую эффективность процесса.
Эксперименты подтвердили вариативные составляющие при изменении предложенной архитектуры нейросети, влияние качества предобработки батчей, а также получение различных результатов при изменении гиперпараметров модели.
Таким образом, можно прийти к выводу о том, что использование методик машинного и глубинного обучении имеет научно-практическое значение в медицинской деятельности и способно быть перспективным направлением для дальнейшего изучения и совершенствования со стороны исследователей.
Библиографическая ссылка
Талалаев М.В. ПРЕДСКАЗАТЕЛЬНЫЕ МОДЕЛИ НА МРТ-СНИМКАХ ГОЛОВНОГО МОЗГА: ВЛИЯНИЕ РАЗМЕРА ВЫБОРКИ НА СТАБИЛЬНОСТЬ МОДЕЛИ ГЛУБИННОГО ОБУЧЕНИЯ // Современные наукоемкие технологии. 2023. № 1. С. 64-72;URL: https://top-technologies.ru/en/article/view?id=39498 (дата обращения: 21.06.2026).
DOI: https://doi.org/10.17513/snt.39498