


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
COMPARATIVE ANALYSIS OF VARIOUS OPTICAL CHARACTER RECOGNITION SYSTEMS WHEN WORKING WITH TEXT WRITTEN USING THE CYRILLIC ALPHABET

В мире наступила эпоха цифровизации, когда бумажные документы переводятся в цифровой вид. Огромное количество текста не позволяет использовать человеческий труд из-за низкой скорости печатания. Исследование, проведенное группой ученых в 1999 г., показало, что средняя скорость ввода слов на клавиатуре человеком – 19 слов в минуту [1]. Если взять за среднее число символов в слове равное 5,1 [2], то в среднем человек вводит 5,1×19=96,9 символов в минуту. Так, чтобы перепечатать документ с 40000 символами (один авторский лист) потребуется 40000/96,9/60=6,88 ч, а таких документов может быть очень много. Поэтому практичным решением будет переложить процесс переноса текста из бумажного вида в цифровой с человека на компьютер, а человеку оставить только редактуру введенного программой текста, однако и тут можно значительно снизить участие человека, если использовать системы корректировки грамотности слов.
Преимущество передачи роли наборщика текста компьютеру также заключается в том, что компьютер не знает усталости, и если человек при долгом наборе текста устает и начинает делать ошибки, то компьютер не подвержен этому и точность вводимого текста не зависит от времени работы.
Примером, когда может понадобиться данный подход, может служить следующий случай: имеется большой объем документации, представленной в бумажном виде, при этом нет цифровых оригиналов. В этой ситуации автоматическое введение текста может сильно упростить жизнь человеку. Такой подход полезен, когда надо оцифровать содержимое старой книги. Ведь постоянное перелистывание страниц может повредить листы старого документа.
В связи с этим встает вопрос: какую систему оптического распознавания символов (OCR) стоит использовать при работе с документами, написанными с помощью кириллического алфавита? Чтобы ответить на этот вопрос, необходимо провести исследование, в ходе которого будут установлены характеристики (точность, скорость, потребление памяти) различных систем оптического распознавания символов при работе с кириллическим алфавитом. В данной статье будет приведено описание такого исследования и результаты его проведения.
В мире существуют исследования, сравнивающие различные системы оптического распознавания символов [3, 4]. Однако все они были проведены на некириллических символах.
В большинстве OCR процесс распознавания символов обязательно содержит следующие этапы [5]:
− определение потенциальной области интереса;
− обнаружение признаков символов в области интереса;
− определение символа по обнаруженным признакам.
В отдельно взятых системах оптического распознавания символов могут присутствовать и дополнительные действия как, например, в Tesseract, который в процессе распознавания текста дополнительно обучается [6].
Материалы и методы исследования
Существуют различные системы оптического распознавания символов, однако часть из них может работать только с текстами, состоящими из одной латиницы. Такие OCR в данной работе рассматриваться не будут. В качестве исследуемых OCR выступают следующие системы оптического распознавания символов, в скобках указана версия: ABBYY FineReader (15.0.117.9681), CuneiForm (1.1.0), OCRopus (1.3.2), Tesseract (5.1.0.20220510) и Transym OCR (5.1). Существуют и другие OCR, которые работают с кириллическими символами, например OmniPage, однако они будут рассмотрены в последующих работах.
ABBYY FineReader – коммерческое программное решение, созданное российской компанией ABBYY. Работа над первой версией программы началась в 1992 г. из-за возникшей потребности при разработке комплекса программ Lingvo Systems [7]. Внутренняя технология распознавания держится в секрете [8]. Программа поддерживается и по сей день, периодически выходят обновления и новые версии.
CuneiForm – бесплатная система OCR, которая изначально разрабатывалась российской компанией Cognitive Technologies. Первая версия программы появилась в 1993 г. и изначально распространялась как коммерческий продукт, однако в 2008 г. Cognitive Technologies решила открыть исходный код CuneiForm всему миру. Система оптического распознавания символов в своей работе использует следующие технологии: адаптивное распознавание, нейронные сети, когнитивный анализ альтернатив распознавания, меридианная сегментация таблиц [9]. Программа CuneiForm способна распознавать тексты на более чем 17 языках, при этом программа может обрабатывать кириллицу и латиницу в одном тексте [10]. На текущий момент эта OCR не развивается.
OCRopus – набор программ с открытым исходным кодом для анализа документов, в том числе для распознавания текста. Первая версия системы анализа документов была выпущена в 2007 г. OCRopus является расширяемой системой, что позволяет изменять ее под свои нужды, стоит отметить, что модульность в его архитектуру закладывалась ещё в самом начале разработки [11]. OCRopus написан на устаревшей на сегодняшний день версии Python – 2.7.
Tesseract – система оптического распознавания символов, изначально разработанная компанией HP для использования в принтерах своего производства. Примечательно, что Tesseract начинался как PhD проект [12]. Первое публичное упоминание датируется 1995 г. на конференции, посвященной системам OCR, после чего Tesseract на какое-то время исчез из информационного поля [12]. В 2005 г. HP открыла исходный код Tesseract [6], после этого с 2006 по 2018 г. система поддерживалась и разрабатывалась компанией Google. Стоит отметить, что Tesseract проходит по тексту два раза, в первый раз он распознает то, что получится, при этом он одновременно дополнительно обучается; и во второй раз Tesseract распознает, то что не было распознано в первый раз [6]. Также Tesseract предлагает три натренированные модели: быстрая, точная и стандартная, которая поддерживается старыми версиями программы.
Transym OCR – коммерческая система оптического распознавания символов, разработанная компанией Transym Computer Services и выпущенная в 2002 г. TOCR разработан специально для встраиваемых систем и различных интеграций. По заявлениям разработчиков для обучения TOCR используется более 108000 файлов изображений документов. Для проверки правильного распознавания слов в системе используется соответствие распознанного слова со списком часто употребляемых слов [10]. Перед распознаванием TOCR проводит предварительную подготовку изображения текста в виде перевода изображения в оттенки серого [13]. При работе с изображением документа программа сама определяет язык, на котором нужно производить распознавание текста [14].
В качестве тестовых данных для исследования использовались отсканированные страницы из книги Джека Лондона «Белый клык» в количестве 20 экземпляров. Для более объективных результатов сравнительного анализа предварительная подготовка изображений страниц книги не проводилась. Сделано это было для того, чтобы на результате распознавания отразилось наличие или отсутствие предварительной обработки изображений, непосредственно встроенной в конкретную систему оптического распознавания символов. Фрагмент одной отсканированной страницы представлен на рис. 1.
Стоит отметить, что никакие настройки в системах оптического распознавания символов не изменялись, за исключением установки русского языка, однако в Transym OCR это не применялось из-за заверений разработчиков, что система может сама определять язык. Вся работа происходила с установленными разработчиком настройками. Некоторые системы OCR являются коммерческим продуктом, в этом случае для сравнительного анализа использовались их пробные версии.
Само исследование проводилось на персональном компьютере, обладающем следующими характеристиками: процессор – Intel Core i5 8500 с частотой 3 ГГц; оперативная память – DDR4 24 Гб с частотой 1 ГГц.
Сравнение различных систем оптического распознавания символов проводилось по определенному алгоритму. Были подготовлены отсканированные страницы книги в формате PNG. Если OCR представлял собой программный фреймворк, то была написана программа, использующая его. Далее одновременно замерялось время выполнения распознавания и расход памяти в диспетчере задач. После распознавания символов полученный текст сравнивался с эталонным, то есть оригинальным; подсчитывалось число ошибок и исходя из этого вычислялась точность распознавания символов. Вычисление точности распознавания текста с кириллическими символами производилось по формуле
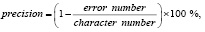
где precision – точность распознавания символов; error number – число ошибок; character number – число символов в эталонном тексте.
В качестве еще одной меры точности распознавания использовалось расстояние Левенштейна, которое представляет собой минимальное количество операций, производимых над символами и необходимых для преобразования одной строки в другую. Чем меньшее значение имеет расстояние Левенштейна, тем больше совпадение распознанного текста и эталонного.
В качестве результирующих данных для каждой OCR были взяты средние арифметические значения результатов, полученных для всех 20 изображений текста.
Графическое представление вышеописанного алгоритма изображено на рис. 2.

Рис. 1. Фрагмент отсканированной страницы
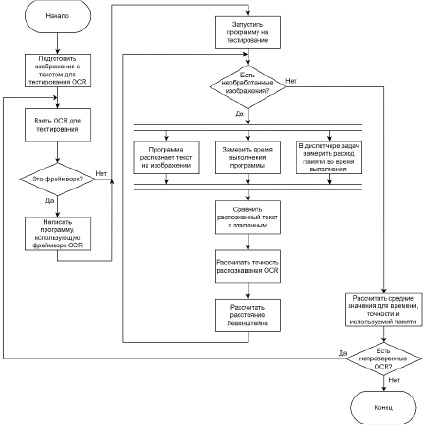
Рис. 2. Алгоритм сравнения систем оптического распознавания символов
Результаты исследования и их обсуждение
В процессе распознавания системами OCR были допущены различные ошибки. Некоторые из них представлены в табл. 1.
Результаты сравнительного анализа представлены в табл. 2.
В процессе проведения сравнительного анализа были отмечены различные особенности некоторых систем OCR. Система OCRopus требует выполнения сложной установки относительно всех остальных систем оптического распознавания символов. Помимо этого, система написана на старой версии языка программирования Python, что накладывает некоторые ограничения при работе с ней. Еще одним выделяющимся аспектом является то, что необходимо вручную запускать множество скриптовых сценариев. Весьма важную особенность также продемонстрировала система Tesseract, при выполнении распознавания текста данная OCR добавляет множество символов переноса в результат своей работы, что следует учитывать при работе с Tesseract.
В процессе распознавания символов OCR допускали различные ошибки, которые были продемонстрированы в табл. 1. Можно предположить, что при проведении аналогичного этой работе исследования при наличии гораздо большей выборки можно будет выделить некоторые частотные характеристики для пар «Правильный символ – Ошибка», наличие этой информации позволит построить систему корректировки слов, опирающуюся на вероятностные значения. Однако стоит отметить, что для каждой OCR будет своя частотная таблица с парами «Правильный символ – Ошибка», связано это с тем, что различные OCR задействуют различные технологии при своём целевом использовании.
Таблица 1
Некоторые ошибки, допущенные различными OCR
|
OCR |
Оригинал |
Ошибка |
|
ABBYY FineReader |
И |
11 |
|
О |
() |
|
|
Л |
-1 |
|
|
CuneiForm |
Он |
Ип |
|
й |
н |
|
|
Н |
П |
|
|
OCRopus |
П |
1г |
|
У |
1 |
|
|
И |
П |
|
|
Tesseract |
Д |
Ц |
|
М |
З |
|
|
Г |
Т |
|
|
Transym OCR |
О |
() |
|
Н |
11 |
|
|
И |
U |
Затрагивая результаты сравнительного анализа, приведенные в табл. 2, стоит отметить некоторые моменты, которые сильно выделяются на фоне показателей остальных OCR. Так, худший результат по скорости показала система OCRopus, связано это с тем, что в процессе распознавания требуется запуск множества скриптовых сценариев. Среди моделей Tesseract, к удивлению, самой быстрой оказалась стандартная модель, она обошла быструю модель (Fast) почти на целую секунду. Transym OCR показала себя наихудшим образом по качеству распознавания, это связано с тем, что система, несмотря на заверения разработчиков, не смогла правильно определить язык, на котором написан текст. Больше всех использует оперативную память ABBYY FineReader, можно предположить, что это связано с тем, что сама система является весьма громоздкой и обладает обширным графическим пользовательским интерфейсом.
Результаты данного сравнительного анализа несут в себе следующую практическую ценность – на основе данных, приведенных в табл. 2, можно делать выбор в пользу той или иной системы OCR для применения в конкретном программном проекте.
Научная новизна исследования заключается в следующем: впервые проведен сравнительный анализ для некоторых систем оптического распознавания символов при работе с кириллическим текстом, а также установлены численные характеристики: точность, скорость, потребление памяти – различных OCR при работе с кириллическим алфавитом.
В будущем планируется проведение аналогичного исследования для других систем оптического распознавания символов. Также планируется проведение исследования, в ходе которого будут установлены частотные характеристики для пар «Правильный символ – Ошибка» для рассмотренных в этой работе систем OCR, а также для других систем оптического распознавания символов, которые будут затрагиваться в будущих исследованиях.
Таблица 2
Сводная таблица с результатами сравнительного анализа
|
OCR |
Бесплатно |
Время выполнения, с |
Точность |
Используемая память, Мб |
Расстояние Левенштейна |
|
ABBYY FineReader |
Нет |
4,15 |
99,14 % |
150,2 |
16 |
|
CuneiForm |
Да |
2,08 |
78,05 % |
25,1 |
906 |
|
OCRopus |
Да |
84,70 |
71,73 % |
89,3 |
1048 |
|
Tesseract |
Да |
1,84 |
96,41 % |
51,9 |
55 |
|
Tesseract Best |
Да |
3,11 |
96,52 % |
39,9 |
53 |
|
Tesseract Fast |
Да |
2,96 |
96,25 % |
43,3 |
66 |
|
Transym OCR |
Нет |
2,06 |
4,07 % |
54,4 |
3825 |
Заключение
Опираясь на результаты исследования, можно сказать, что лучшей из рассматриваемых OCR по точности распознавания кириллических символов является ABBYY FineReader, однако данная система является коммерческой, и если стоит вопрос об использовании бесплатной системы, то тут стоит остановить свой выбор на Tesseract. По качеству распознавания хуже всего показала себя Transym OCR. С точки зрения скорости распознавания лучший результат показал Tesseract со стандартной моделью. Хуже всего результаты скорости оказались у OCRopus. Лучший результат по используемой памяти показала система CuneiForm. Худший же – ABBYY FineReader.
Стоит отметить, что среди рассматриваемых систем оптического распознавания символов нельзя однозначно выбрать лучшую, так как по каким-то критериям одна OCR лучше другой, по другим – результат противоположный. И выбор конкретной системы для проекта стоит делать исходя из налагаемых ограничений. Так, например, если критическим фактором является скорость выполнения распознавания, то, опираясь на результаты этого исследования, можно в качестве кандидатов на использование в проекте рассматривать Tesseract или CuneiForm.
Библиографическая ссылка
Качалин В.С., Панов Ю.Н., Попов Н.-Л.Э. СРАВНИТЕЛЬНЫЙ АНАЛИЗ РАЗЛИЧНЫХ СИСТЕМ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ ПРИ РАБОТЕ С ТЕКСТОМ, НАПИСАННЫМ С ПОМОЩЬЮ КИРИЛЛИЧЕСКОГО АЛФАВИТА // Современные наукоемкие технологии. 2022. № 8. С. 65-70;URL: https://top-technologies.ru/en/article/view?id=39268 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.39268