


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
STUDY OF THE MOST EFFICIENT MODELS AND ATRIBUTION ALGORITHMS USING THE ROC AUC INDICATOR

С 1980-х годов начало приобретать популярность моделирование маркетингового комплекса (Marketing mix modeling) – метод анализа, который позволял маркетологам измерять влияние своих маркетинговых и рекламных кампаний, чтобы определить, как различные элементы способствуют достижению их цели, по повышению конверсии. По мере развития интернет-коммерции росло количество доступных для использования рекламных каналов, помогающих компаниям эффективнее продавать свои услуги. Однако для работы с такими каналами требуется разработка новых стратегий оценки их эффективности.
Развитие технологий позволяет отслеживать и анализировать действия пользователей, привлеченных с помощью различных онлайн-каналов. Полученные таким образом данные необходимо максимально использовать при разработке эффективной стратегии интернет-продвижения. Но в настоящее время существует недостаток знаний о поведении клиентов на рынке.
При обработке больших объемов информации, которые могут находиться в неструктурированном виде, исследователи используют модели на основе различных алгоритмов машинного обучения: интеллектуальный анализ текста; методы обработки естественного языка (NLP) и другие. Моделирование атрибуции – один из способов использования данных. Многоканальная атрибуция предназначена для оценивания вклада различных рекламных каналов в итоговую конверсию интернет-продукта и отвечает на вопрос: какой из рекламных каналов оказал влияние на клиента.
Вопросам атрибуции посвящено значительное количество работ. Так, например, в исследовании [1] проведен обзор существующих методов атрибуции, представлена их таксономия на основе современных научных публикаций. В работе [2] с опорой на структурированный процесс исследования литературы были оценены существующие подходы с точки зрения их применимости в многоканальной среде. По результатам исследования научных публикаций в области применения машинного обучения для атрибуции ценности по разным источникам трафика было выявлено отсутствие исследований сравнения моделей и алгоритмов атрибуции.
Целью данного исследования является сравнительный анализ различных методов и алгоритмов атрибуции, а также оценка точности рассмотренных алгоритмов по показателю ROC AUC и выявление наиболее эффективных и практически применимых моделей на основе пользовательского набора данных.
Для достижения поставленных целей были решены следующие задачи:
− исследование существующих методов и моделей атрибуции каналов;
− анализ цепочек взаимодействия для рекламных каналов при помощи эвристических и базовых многоканальных алгоритмических моделей атрибуции;
− создание и обучение моделей машинного обучения, проверка точности классификации и сравнительный анализ времени работы всех рассмотренных алгоритмов;
− визуализация полученных результатов расчета физического времени работы эвристических, алгоритмических моделей атрибуции и моделей машинного обучения в виде графиков.
Научная новизна заключается в предложенной методике использования машинного обучения для выбора наиболее эффективных моделей и алгоритмов атрибуции, которые позволяют с использованием показателя ROC (Receiver operating characteristic) AUC (Area Under Curve) получить оптимальный метод работы фирмы для привлечения клиентов. Предложенный в статье анализ моделей атрибуции помогает понять, какой из каналов продвижения товара на рынке является максимально эффективным. Список каналов продвижения товара на рынке будет приведён ниже.
Материалы и методы исследования
В работе использован пользовательский набор данных [3], который содержит информацию о работе реального интернет-магазина. Информация была обработана таким образом, чтобы можно было использовать для её анализа программные модули из библиотеки «MTA» [4], которые позволяют сравнить цепочки взаимодействия клиента с каналами продвижения, а также проверить эффективности всех рассмотренных алгоритмов.
Многие системы аналитики, используемые современными маркетологами, предлагают эвристические модели для атрибуции ценности канала.
Начнем с моделей атрибуции, которые основаны на распределении ценности по одному каналу:
− по первому взаимодействию (First Interaction);
− по последнему взаимодействию (Last Interaction);
− по последнему непрямому клику (Last Non-Direct Click).
Несмотря на то что упомянутые выше модели тривиальны в использовании и расчете, а также часто игнорируют всю дополнительную информацию, они тем ни менее часто используются. Необходимо учитывать, что каждый канал в более длинных воронках продаж может как положительно, так и отрицательно влиять на решение клиентов продолжить движение по воронке, а само воздействие промежуточных точек различного характера может иметь нарастающий эффект.
При необходимости проанализировать несколько каналов следует объединить несколько источников из различных рекламных сервисов, а также применять наиболее комплексные модели атрибуции. Таким образом, можно получить информацию, какие пары или связки рекламных каналов эффективно взаимодействуют в совокупности и на каких этапах.
Рассмотрим модели атрибуции для нескольких каналов одновременно. К ним относятся:
− линейная модель атрибуции (Linear model);
− с учетом давности взаимодействия (Time Decay);
− на основе позиции (Position Based или U-образная).
В многоканальных моделях учитывается большее количество взаимодействий с клиентом. Однако все они работают по заданным траекториям и не учитывают отклонений в сторону. Ещё одна проблема таких моделей связана с тем, что точки взаимодействия, инициированные клиентами, и точки взаимодействия, инициированные фирмой, не всегда совпадают. Поэтому оценку атрибуции следует выполнять с осторожностью.
Атрибуция на основе цепей Маркова – это модель, использующая вероятности перемещений по шагам воронки, которая дает оценку влиянию шагов на конверсию и позволяет определить наиболее значимый вклад в общую конверсию. Идея рассматриваемой модели состоит в определении набора состояний клиента и оценке вероятности перехода между различными состояниями [5].
Кроме того, существуют наиболее точные алгоритмы атрибуции, основанные на применении данных, собранных заранее. Главное преимущество моделей атрибуции на основе таких данных состоит в том, что в них не учитывается порядок канала в цепочке, а анализируется влияние на конверсию конкретного канала.
В библиотеке MTA имеются модули, позволяющие провести анализ рекламных каналов с помощью таких моделей, как модели Shao&Li, которые предлагают несколько статистических моделей атрибуции ценности на основе заранее собранных данных: bagged logistic regression model и simple probabilistic model [6]. Кроме модели Shao&Li, авторами также был выбран для работы подход с использованием вектора Шепли [7].
При изменении порядка сессий ценность каналов по вектору Шепли не меняется. Вектор Шепли – это метод, изначально изобретенный для назначения выигрыша игрокам в зависимости от их вклада в общий выигрыш [8].
Ценность канала по вектору Шепли рассчитывается по формуле 1:
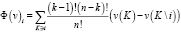 , (1)
, (1)
где n – количество игроков (в нашем случае это рекламные каналы); v – ценность, которую принес источник; k – количество участников коалиции K.
Кроме того, было уделено внимание системам машинного обучения. C помощью машинного обучения система обрабатывает некоторое количество заданных примеров, идентифицирует похожие цепочки взаимодействия клиентов с каналами и использует их для прогнозирования новых данных [9].
В то же время становится всё более очевидным, что «ретроспективный подход» к атрибуции перестал обладать достаточной эффективностью, а саму концепцию атрибуции следует рассчитывать, используя для расчётов вероятностную характеристику [10].
Гибридный подход к атрибуции будет помогать эффективно предсказывать вероятность покупки.
Результаты исследования и их обсуждение
Прежде всего, для выполнения процесса распределения ценностей по каналам загрузим заранее обработанные данные и выполним их анализ с помощью модулей из библиотеки «MTA» [4].
Для моделирования эвристических и алгоритмических моделей атрибуции использовались следующие методы: mta.first_touch(); mta.last_touch(); mta.time_decay(); mta.markov(); mta.shapley(); mta.shao().
Были проанализированы следующие каналы: Affiliates (Партнеры); Direct (Прямой трафик); Display (Медийная реклама); Organic Search (Органический поиск); Paid Search (Платная реклама); Referral (Реферальный трафик); Social (Социальные сети); Other (Прочее).
На рисунке 1 показаны результаты выполнения анализа цепочек взаимодействия с помощью модулей из библиотеки «MTA».
Как видно из рисунка 1, большинство моделей для расчёта атрибуции присвоили максимальное значение каналу Direct (Прямой трафик).
Перейдём непосредственно к обучению методов машинного обучения. Попробуем создать и обучить модель градиентного бустинга, а затем произвести оценку сложности работы данного алгоритма, подсчитаем время его работы.
Процесс обучения модели содержит в себе следующие этапы: подготовка данных, создание наборов данных для обучения, создание классификатора, обучение классификатора, составление прогнозов и оценка сложности, времени работы классификатора.
В процесс предварительной обработки данных по маркетинговым каналам для классификатора входит следующее: преобразование данных в форму, подходящую для классификации; обработка аномалий в этих данных, например аномалий отсутствия некоторых значений в подготавливаемых данных и т.п. Если не убрать аналогичные аномалии, они в конечном итоге могут негативно повлиять на производительность алгоритма классификации и снизить качество полученных результатов.
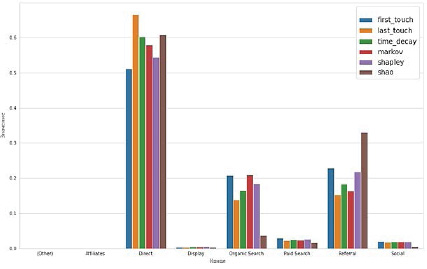
Рис. 1. Результаты выполнения анализа цепочек взаимодействия
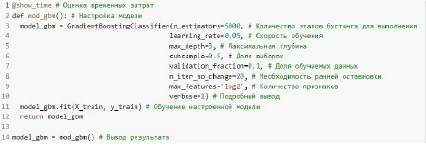
Рис. 2. Настройка модели машинного обучения
Сравнивая показания классификатора с фактически известными данными, можно сделать вывод о точности классификатора.
После процесса обучения можно проверить точность классификации, используя площадь ROC-кривой (AUC). Таким образом, процесс обучения представляет собой оценку способности классификатора различать подходящие и не подходящие какому-либо классу объекты. Для обучения модели градиентного бустинга [11] и оценки ее производительности был написан модуль на языке Python. Текст модуля показан на рисунке 2.
Таким образом, были получены следующие результаты оценки производительности. Затраченное время на обучение – 1,040 сек., рассчитана площадь под ROC-кривой и построен график (рис. 3).
Полученный результат AUC свидетельствует о приемлемом классификаторе.
Площадь под ROC-кривой – AUC (Area Under Curve) – является характеристикой качества классификации, чем больше охватываемая область, тем больше значение AUC и тем лучше модель классификации. Так принято, что AUC = 1 – лучший случай, при AUC = 0.5 – алгоритм случайного гадания, который соответствует худшему случаю. В нашем случае AUC = 0.78, что говорит о том, что данную модель классификации можно использовать для оценки вероятности конверсии.
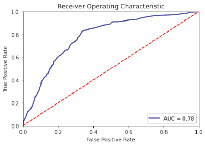
Рис. 3. Визуализированная кривая ROC
Для комплексной оценки производительности указанных алгоритмов и сравнения времени работы указанных алгоритмов с данными по точкам касания клиентов и маркетинговых каналов, было проведено обучение алгоритмов Random forest, градиентного бустинга GBM и нескольких его реализаций: LightGBM, XGBoost на наборах данных, содержащих сведения за 1, 2, 4, 8, 12 месяцев. Результаты расчета AUC после обучения каждого классификатора показаны в таблице.
Результаты расчета AUC после обучения каждого классификатора
|
№ |
Алгоритм |
Train_AUC |
Valid_AUC |
|
0 |
Random Forest |
0,75 |
0,75 |
|
1 |
GBM |
0,75 |
0,75 |
|
2 |
LightGBM |
0,74 |
0,75 |
|
3 |
XGBoost |
0,73 |
0,74 |
|
4 |
All |
0,76 |
0,75 |
По результатам расчёта AUC после обучения каждого классификатора можно сделать вывод, что все модели показали примерно одинаковый результат, без большого разброса с приемлемым качеством классификации.
Перейдем к сравнению физического времени работы эвристических, алгоритмических моделей атрибуции и моделей машинного обучения.
На рисунке 4 показана визуализация полученных результатов расчета физического времени работы эвристических, алгоритмических моделей атрибуции и моделей машинного обучения в виде графиков, на которых показана зависимость физического времени работы алгоритма (в секундах) по оси Y от количества данных (за 1, 2, 4, 8, 12 месяцев) в обрабатываемом наборе по оси X. Контрольное количество данных по оси X (за 1, 2, 4, 8, 12 месяцев) для сравнения на графиках обозначено метками.
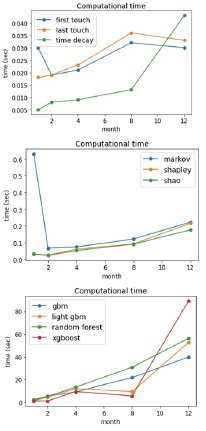
Рис. 4. Сравнение времени работы эвристических, алгоритмических методов и моделей машинного обучения
Таким образом, сравнительный анализ времени работы эвристических моделей показал, что разброс во времени работы моделей – незначителен и зависит от количества данных, а сравнение времени работы алгоритмических моделей показало, что разброс во времени работы разных алгоритмов – не существенный и также зависит от количества данных. Было выявлено, что времени на выполнение было затрачено больше, чем в эвристических моделях. Сравнение времени работы моделей машинного обучения также выявило, что присутствует зависимость скорости обработки моделей от количества данных. Наиболее быстрым методом является – метод gbm с точностью 0,74. Самый медленный алгоритм – метод xgboost с точностью 0,73. Контрольное количество данных было взято за 12 месяцев.
В данной работе была проведена комплексная оценка точности всех указанных алгоритмов по показателю ROC AUC, а также были выявлены наиболее эффективные и практически применимые модели. Было проведено исследование существующих методов распределения ценности рекламных каналов. Проанализировано взаимодействие рекламных каналов. Создано программное обеспечение для оценки точности классификации по показателю ROC AUC. Проведен сравнительный анализ времени работы рассмотренных алгоритмов. Была построена визуализация полученных результатов расчета физического времени работы эвристических, алгоритмических моделей атрибуции и моделей машинного обучения.
Несмотря на незначительное количество времени работы как эвристических, так и алгоритмических моделей, точность данных методов крайне мала. Результаты точности моделей машинного обучения можно проверить различными способами, в том числе методом вычисления площади под кривой ошибок, что дает основное преимущество при выборе модели многоканальной атрибуции.
Библиографическая ссылка
Хайдаров А.Г., Соловьев А.И., Будко Д.А. ПРИМЕНЕНИЕ ПОКАЗАТЕЛЯ ROC AUC ДЛЯ ОБОСНОВАНИЯ НАИБОЛЕЕ ЭФФЕКТИВНЫХ МОДЕЛЕЙ И АЛГОРИТМОВ АТРИБУЦИИ // Современные наукоемкие технологии. 2022. № 7. С. 63-68;URL: https://top-technologies.ru/en/article/view?id=39234 (дата обращения: 02.07.2026).
DOI: https://doi.org/10.17513/snt.39234