


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
INVESTIGATION OF A TASK MANAGER MODEL WITH A DISTRIBUTED QUEUE OF A RECONFIGURABLE COMPUTING SYSTEM

На сегодняшний день методы и средства повышения производительности вычислительных систем (ВС), такие как более плотное размещение транзисторов на кристалле, увеличение числа одновременно выполняемых команд, расширение объемов кэш-памяти процессоров (ЦП), постепенно исчерпывают свои возможности. Для того чтобы сохранить темпы роста производительности высокопроизводительных ВС (ВВС), недостаточно совершенствовать технологические решения, а также схемотехнику ЦП. В данной ситуации следует основательно рассмотреть способы перестройки самой архитектуры ВВС, например, представленной в виде реконфигурируемой вычислительной системы (РВС).
Синхронизация процессов в ВС с одним ЦП реализована программно в пространстве пользователя или ядра операционной системы (ОС), при этом не влияя на производительность ВВС, тогда уже в РВС будет присутствовать достаточно серьезное увеличение времени выполнения при синхронизации процессов. Можно допустить, что программа, которая выполняет свои процессы в однопроцессорном и многопроцессорных режимах, имеет одинаковые затраты по времени на синхронизацию процессов. Затраты значительно могут отличаться в тот момент, когда будет наблюдаться уменьшение времени выполнения параллельных потоков. Упомянутый процесс обусловлен последовательностью связанного с синхронизацией процессов элемента программы и согласно закону Амдала [1] – это фактор, который снижает производительность РВС. Эффективное решение обозначенной проблемы – аппаратная реализация функций планирования и диспетчеризации задач, которая в значительной степени снимает проблему временных потерь при синхронизации.
Цель настоящей работы – проанализировать известные РВС и возможные способы диспетчеризации задач, а также разработать и исследовать математические модели таких систем с использованием широко применяемого аппарата теории массового обслуживания (ТМО). Описать возможности практического применения предложенных математических моделей. Достижению поставленной в работе цели способствует решение следующих задач: исследование, расчет и анализ параметров моделей диспетчеров задач (ДЗ) в составе РВС; подтверждение достоверности работы алгоритма ДЗ экспериментальным путем в режиме реального времени.
Материалы и методы исследования
К настоящему времени сложилась определенная классификация архитектур вычислительных систем, так называемая классификация по Флинну [2], которая анализирует архитектуру по способу обрабатываемых данных и взаимодействия потоков выполнения команд. К классу SISD относятся классические фон-неймановские машины. Архитектура SIMD формирует поток векторных команд, что позволяет производить арифметическую операцию над множеством данных. Векторная обработка может быть выполнена с помощью, конвейера процессорной матрицей. Класс MISD предполагает архитектуру, в которой несколько ЦП осуществляют обработку одного и того же потока данных. Но данная архитектура так и не нашла практическое применение. Широкое применение в сфере высокопроизводительных вычислений получила архитектура MIMD, на основе данной архитектуры строится большинство многопроцессорных параллельных ВС. MIMD разбивается на подклассы: мультипроцессоры и мультикомпьютеры. В свою очередь, мультипроцессоры делятся на UMA и NUMA-системы [1].
Система с общей памятью представляет собой структуру (рис. 1, а), в которой оперативная память является общей для всех ЦП. Достоинство такой архитектуры заключается в экономии времени на пересылку данных, так как эти данные, помещенные в общую память, доступны сразу всем ЦП с помощью общей шины. ЦП, имеющие одинаковый доступ к устройствам ввода-вывода и ко всем ячейкам оперативной памяти, к которой процессы обращаются единообразно и обращение происходит с одинаковым временем – такие системы называются симметричными (symmetric multiprocessor – SMP). Принцип действия подобной системы в том, что при помощи схемы приоритетов определенный ЦП получает данные из общей памяти, шина занята в течение времени передачи данных, другие ЦП отключаются от общей шины и выполняют задачи, не связанные с доступом в оперативную память.
Система с распределенной (сосредоточенной) памятью (рис. 1, б) содержит в себе множество ЦП, каждый из которых имеет свою собственную оперативную память. Чтобы организовать обмен данных между ЦП, существует канал связи, подобные системы делятся на два типа: с универсальной коммутацией, где любой ЦП может быть связан с любым другим, и с жесткой коммутацией, в которой связь определенного ЦП существует только с определенным количеством других ЦП. Достоинство данной архитектуры в эффективном решении задач, так как ЦП не требуется ожидать освобождения оперативной памяти. Архитектура NUMA обеспечивает обращение к данным при физическом распределении памяти, поэтому длительность доступа является неодинаковой для всех элементов памяти. Системы с распределенной памятью делятся еще на два типа, с локальной кэш-памятью (cache only memory architecture – COMA) ЦП и системы с когерентностью локальной кэш-памяти ЦП (cache coherent NUMA – CC-NUMA).
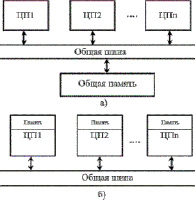
Рис. 1. Структурная схема ВС с общей (разделяемой) (а) и распределенной (б) памятью
В России известны и применяются следующие РВС – это, прежде всего, разработки ведущих научно-исследовательских институтов и крупных университетов, специализирующихся на РВС: РВС-1, РВС-0.2-РС, РУПК-50, БВР-01, KB8-К7-410-01 «Топаз-2» и др. [3, 4]. Разработчики компании Fastwel создали вычислитель БВР-01. Устройство направлено на решение таких задач, как цифровая обработка сигналов, применение методов линейной алгебры, символьной обработки, особенности – гибкая структура и возможности объединения с подобными устройствами для создания кластерных систем. Архитектура вычислителя БВР-01 (рис. 2, а) состоит из управляющего компьютера (УК) СРС1301, 8 ПЛИС Xilinx Virtex-6, модуль памяти EM-DDR3-2GB. ПЛИС соединены между собой высокоскоростным интерфейсом PCI Express Gen 2.0, что позволяет обмен данных между УК и 8 ПЛИС на скорости до 20 Гбит/с. РВС на базе Xilinx Kintex-7 KB8-К7-410-01 «Топаз-2» (рис. 2, б) создана в ФГУП НИИ «Квант». Разработанное устройство состоит из одной системной и восьми рабочих ПЛИС, которые соединены к коммутатору PCI Express, данный коммутатор представляет собой микросхему PEX8648 на 12 портов. Для соединения ПЛИС используются схемы «звезда» и кольцо, что обеспечивает высокоскоростной канал обмена информации. Разработчики ООО НПО «Роста» создали РВС RC-47 (рис. 2, в), на которой установлено четыре рабочих ПЛИС Xilinx семейства Virtex-7, также на плате установлены два мезонинных модуля памяти ЕМ4-DD, где в каждом модуле по 4 банка памяти объемом 512 Мбайт. Основные технические характеристики платы следующие, cервисная ПЛИС: Xilinx Spartan-6, четыре рабочих ПЛИС: Xilinx Virtex-7 (XC7V585/1500/2000T, XC7VX330/485/690T) FF(G) 1761, все рабочие ПЛИС поддерживают PCI Express Gen2 (для серии XC7V) или Gen3 (для серии XC7VX), сеть PCI Express: одна СБИС PEX8732 коммутатора PCI Express Gen3 x4 (8 портов), микроконтроллер STM32F, обеспечивающий контроль напряжений и температур, загрузку конфигураций в системный и рабочие ПЛИС, настройку и мониторинг коммутатора PCI Express по шине I2C [4].
Диспетчеризация задач. Суть планирования и диспетчеризации процессов и задач в РВС заключается в назначении целевого ЦП для ее решения. Современные работы по планированию в операционных системах говорят о двух часто применяемых способах организации работы ДЗ: с глобальной и распределенной очередью задач [5].
Для исследования параметров ВВС применяют простой метод, основанный на различных системах массового обслуживания (СМО), – абстрактный объект, который включает в себя заявки (задачи), поступающие в систему, несколько обслуживающих каналов (приборов) заявок и накопитель, где организуется очередь из поступивших заявок, ожидающих обслуживания. СМО или базовые модели можно соотнести в соответствие со следующей классификацией: по числу классов заявок, поступающих в СМО; по количеству мест в накопителе; по количеству обслуживающих приборов. Основные параметры и характеристики СМО и построенных на их базе сетей подробно рассмотрены и описаны в работах [6].
В РВС с общей памятью программы обработки и данные, связанные с ними P = {P1,…,PM}, делятся на некоторые подмножества Q1,…,QN , Qt = {Pα,…,Pω} P(i = 1,…,N), и распределяются в памяти процессора ЦП1,…,ЦПN. По этой причине каждый из n-процессоров обрабатывает данные с размещенными в памяти ЦП программами обслуживания. При такой ситуации можно принять процесс работы РВС как функционирование совокупности n-одноканальных СМО, причем каждая из них включает в себя некоторый поступающий с интенсивностью λi поток заявок, очередь Oi и обслуживающее устройство (процессор) ЦПi. Для того чтобы выявить наиболее эффективный метод реализации при проектировании РВС, требуется произвести оценку потери производительности исследуемой системы. В данной работе рассмотрен алгоритм диспетчеризации с распределенной очередью.
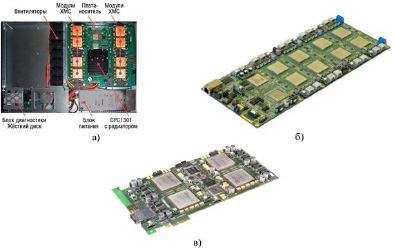
Рис. 2. БВР-01 (а); РВС KB8-К7-410-01 «Топаз-2» (б); РВС RC-47 (в)
ДЗ с общей очередью [5] имеет один существенный недостаток в структуре организации, который понижает производительность всей РВС. Недостаток заключается в том, что возникают конфликтные ситуации при обращении к ДЗ, т.е. только определенный ЦП может обратиться к очереди задач. При этом ЦП требуется обращаться к ДЗ, чтобы получить новую заявку, последние два случая требуют дополнительных затрат по времени. Возможен еще случай, когда в РВС есть не занятые работой ЦП, но обслуживание ожидающих задач не осуществляется, поскольку ДЗ не справляется с потоком поступающих на обработку задач. Использование другого по архитектуре ДЗ с индивидуальными очередями процессов к ЦП – один из путей разрешения проблемной ситуации.
Математическая модель ДЗ с индивидуальными очередями состоит из n-одноканальных СМО (S1,…,Sm) (рис. 3, а), которые моделируют обслуживание в ДЗ и ЦП (S1, S2,…, Sm) и граф передач. Структура и принцип взаимодействия блоков модели не отличается от ДЗ с общей очередью, единственное, что РВС с n ДЗ кроме формирования очередей и назначения задач на обслуживание в ЦП согласно некоторому алгоритму осуществляет балансировку наполненности очередей, когда заявки могут с определенной вероятностью (чем более загружена очередь, тем больше вероятность извлечения задачи из нее) перемещаться из i-й очереди в менее занятую очередь j-го процессора ЦП.
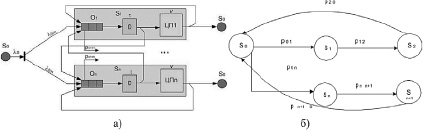
Рис. 3. Схема модели РВС с ДЗ с распределенным ДЗ (а) и ее графовая модель (б)
Параметры моделей
|
Трудоемкость |
Интенсивность входного потока, задач/мс |
Число ЦП |
Средняя занятость ЦП обработкой заявки, мс |
|
Высокая |
9,3 |
4 |
0,009 |
|
93 |
16 |
||
|
Средняя |
0,333 |
4 |
0,068 |
|
3,33 |
16 |
||
|
Низкая |
0,07 |
4 |
0,15 |
|
0,7 |
16 |
Поступающий на входы n ДЗ РВС характеризуется интенсивностью, которая описывается выражением λ00 = λ0 / n. ДЗ обрабатывает поступающие задачи с некоторой интенсивностью μD. Когда ДЗ занят обработкой текущей задачи, другие поступающие на обслуживание требования ожидают своего сервиса очереди. В случае переполнения очереди поступающие задачи перенаправляются в другую менее занятую очередь. После описания характеристик перейдем непосредственно к построению моделей в программах [7, 8]. С помощью графового представления (рис. 3, б) можно рассчитать вероятностно-временные характеристики выхода (p20, pn+1 0) задачи, полностью получившей обслуживание, и вероятностно-временные характеристики возвращения (p12, pn n+1) на дообслуживание в ДЗ. Приведенные вероятностно-временные характеристики напрямую связаны с трудоемкостью поступившей задачи: чем задача более трудоемкая, тем дольше она обрабатывается в ЦП. При исследовании приняты параметры, представленные в таблице. Данные параметры входной интенсивности поступающих задач на обслуживание обеспечивают среднюю загрузку ЦП примерно до уровня 65–70 %. Принято, что длина очереди перед ДЗ составляет 128 задач. Среднее время активности ДЗ принято равным 0,002 мс [9].
Обзор методов математического описания характеристик РВС показывает, как можно простым и наглядным образом получить значения характеристик РВС, не затрачивая при этом больших ресурсов и средств. Для проведения эксперимента получены и определены параметры исследуемых моделей, которые нашли свое применение при построении аналитических и имитационных моделей РВС.
Результаты исследования и их обсуждение
В ходе проведенных экспериментов над моделями получены результаты, которые отражены на графиках на рис. 4–6.
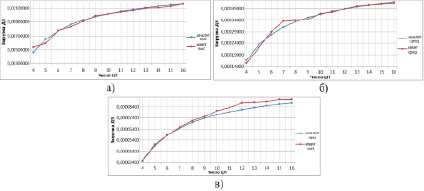
Рис. 4. Зависимость загрузки ДЗ с распределенной очередью от числа ЦП при различной трудоемкости: высокой (а) средней (б) и низкой (в)
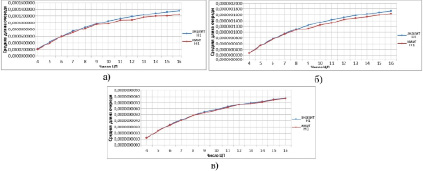
Рис. 5. Соотношение средней длины очереди Н1 в РВС от числа ЦП при высокой (а) средней (б) и низкой (в) трудоемкости поступающих на обслуживание задач
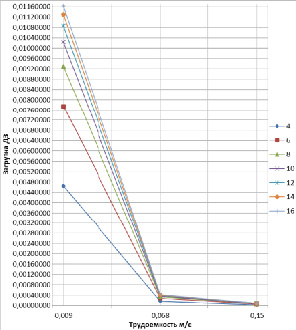
Рис. 6. Трудоемкость задач в РВС, влияющая на загрузку ДЗ с распределенной очередью
Графики, изображенные на рис. 4, показывают плавную зависимость загрузки ДЗ при увеличении числа ЦП. Отличием от системы с общей очередью также является то, что в системе с распределенными очередями ДЗ значения загрузки примерно в 10 раз меньше при всех трех значениях трудоемкости. Данные результаты дают основание утверждать, что система ДЗ с распределенной очередью имеет большую производительность, чем аналогичная.
Графики, изображенные на рис. 5, показывают соотношение средней длины очереди перед ДЗ(Н1) от количества ЦП в РВС. Данное соотношение, в сравнении с зависимостью в системе ДЗ с общей очередью [9], имеет равномерный характер роста при росте числа ЦП, само же значение средней длины очереди имеет разницу в 100 раз.
Графики, приведенные на рис. 6, характеризуют зависимость загрузки ДЗ с распределенной очередью от трудоемкости задач в РВС с числом ЦП от 4 до 16 соответственно. Отметим, что в РВС с ДЗ с распределенными очередями загрузка примерно в 10 раз меньше, чем в аналогичной системе с другим типом ДЗ [9].
Сделаем выводы по проведенным исследованиям. При проведении экспериментов на исследуемых моделях значения основных характеристик (коэффициент загрузки ДЗ, время реакции РВС, средняя длина очереди перед ДЗ) имели небольшой разброс, что подчеркивает адекватность разработанных моделей и целесообразность их применения при проведении аналогичных исследований.
Заключение
В работе проанализированы современные РВС и подсистемы диспетчеризации задач, в том числе рассмотрены возможности практического применения моделей в виде реализации функциональных узлов-диспетчеров задач в составе РВС. Основными достигнутыми результатами являются предложенные модели ДЗ с целью исследования влияния различного вида производительности, верифицированные экспериментально.
Исследование выполнено за счет гранта Российского научного фонда № 21-71-00110.
Библиографическая ссылка
Мартышкин А.И. ИССЛЕДОВАНИЕ МОДЕЛИ ДИСПЕТЧЕРА С РАСПРЕДЕЛЕННОЙ ОЧЕРЕДЬЮ ЗАДАЧ РЕКОНФИГУРИРУЕМОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ // Современные наукоемкие технологии. 2022. № 5-1. С. 100-106;URL: https://top-technologies.ru/en/article/view?id=39155 (дата обращения: 24.07.2026).
DOI: https://doi.org/10.17513/snt.39155