


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
Research and Analysis of Mathematical Models for Evaluating the Performance of Process Synchronization Primitives in Reconfigurable Computing Systems

В настоящее время известны два способа синхронизации процессов взаимодействия: методы взаимного исключения и методы синхронизации. Стремление более эффективно использовать ресурсы вычислительной машины стало толчком к развитию многозадачных операционных систем (ОС). Естественным продолжением многозадачности является многопоточность – способность ОС поддерживать выполнение нескольких потоков в рамках одного процесса, каждый из которых обладает такими характеристиками, как состояние выполнения потока, контекст, стек выполнения и т.п. [1]. Итак, использование потоков может значительно повысить производительность программы, так как их взаимодействие между собой не требует участия ядра ОС, а создание потоков и переключение контекста происходят быстрее, чем планирование их выполнения. Например, в ОС Linux используется модель потоков (легковесные процессы), которые могут совместно использовать определенные ресурсы, а также немедленно отслеживать произведенные над ними изменения. Для реализации многопоточности с каждым потоком ассоциируется легковесный процесс. Поэтому, с одной стороны, потоки могут использовать общее адресное пространство и файловые дескрипторы, а с другой – за планирование их выполнения отвечает ядро. Тем не менее одновременная попытка обращения нескольких потоков к одному общему ресурсу (ОР) может обратиться негативными последствиями [2].
Целью исследования является синтез математических моделей для оценки производительности методов синхронизации процессов в реконфигурируемых вычислительных системах (РВС). Для систем, имеющих ОР (критические секции (КС)), следует использовать модели и методы, синхронизирующие процессы, которые могут конфликтовать при использовании КС. Основная задача, решаемая в настоящем исследовании – проблема производительности РВС с параллельными процессами.
Материалы и методы исследования
Примитивы синхронизации многопоточных приложений. Синхронизация между потоками, как и между процессами, имеет колоссальное значение. Для организации возможности работы с ОР, к которым необходим эксклюзивный доступ, в коде каждого потока выделяют некоторую часть, в которой используются эти ресурсы – КС. При этом требуется, чтобы во время выполнения КС одного потока ни один другой поток не выполнялся в своей КС, использующей те же ОР. Для этого необходимо реализовать один из механизмов взаимного исключения [3]. Важно избегать ситуаций, когда какие-либо два потока ждут друг друга для доступа к КС (взаимоблокировка) или когда разделяемые ресурсы недоступны одному из потоков из-за использования их другими потоками. Для решения данной задачи известно множество алгоритмов. Их можно разделить на программные (например, алгоритм Деккера) и аппаратные решения, основанные на поддержке процессорами (ЦП) таких атомарных инструкций, как Test-and-Set и Compare-and-Swap [3]. Далее рассмотрим наиболее перспективные из них.
Алгоритм Деккера. Является первым известным корректным решением задачи взаимного исключения. Контроль входа в КС осуществляется с помощью двух переменных-флагов и переменной «turn», показывающей, очередь какого потока подошла [4]. Поток сообщает о намеренности войти в КС, установив соответствующий флаг. Если флаг второго потока не установлен, можно безопасно войти в КС. Иначе поток снимает свой флаг и ожидает, пока переменная «turn» не укажет, что подошла его очередь. Преимущество алгоритма Деккера: не требуется наличия специальных атомарных команд «Test-and-Set». Недостатки: использование «busy-wait» цикла, возможность синхронизации между собой лишь двух потоков.
Семафор. Понятие семафора впервые сформулировано Дейкстрой [4]. Семафор – объект, ограничивающий количество потоков, которые могут одновременно находиться в КС. Семафоры можно разделить на считающие и бинарные. Считающие семафоры управляются двумя операциями, исторически называемыми V и P. Операция V увеличивает счетчик семафора на единицу, освобождая, таким образом, место для другого потока в КС. Если счетчик семафора положителен, операция P уменьшает его, а поток может безопасно войти в КС, иначе поток ожидает освобождения семафора. Для реализации семафора необходима аппаратная поддержка атомарных операций, например, «Compare-and-Swap».
Мьютекс. Является аналогом бинарного семафора, который может предоставлять дополнительные возможности, среди которых запоминание идентификатора, заблокировавшего процесса для проверки того, какой процесс пытается его освободить. Также мьютекс может быть рекурсивным, т.е. предоставлять возможность одному и тому же процессу или потоку заблокировать его несколько раз. Если потоку не удалось захватить мьютекс, он засыпает, используя соответствующий системный вызов.
Использование примитивов синхронизации часто приводит к возникновению «узких мест» в коде программы, что связано с продолжительным ожиданием освобождения КС. Данное явление принято называть «конкуренцией за блокировку» [3]. Еще одно понятие, тесно связанное с примитивами синхронизации и описывающее то, насколько хорошо может быть расширена система, – масштабируемость. В случае с блокировками наибольшее значение имеет в контексте увеличения числа потоков, которым требуется доступ к КС, и увеличения количества ЦП или ядер. Третья характеристика блокировок – структурность. Она описывает объем данных, которые защищены примитивом синхронизации. Так, например, один примитив синхронизации может использоваться для всей структуры данных, или же множество примитивов для каждого элемента этой структуры [5]. Таким образом, возникает целый ряд проблем, связанных с производительностью блокировок, которые зависят как от аппаратных особенностей системы и непосредственной реализации примитивов синхронизации, так и от способа их применения в конкретной программе.
С целью анализа производительности используют утилиты-профилировщики. К примеру, профилировщик mutrace работает только с мьютексами из библиотеки pthread, оценивает время ожидания потоком доступа к КС, количество захватов мьютекса, а также количество потоков, которые не смогли получить доступ к КС с первого раза [6]. Другой профилировщик, входящий в HPCToolkit, основан на вычислении времени, которое потоки тратят на ожидание блокировки, и «blame shifting» в создании конкуренции за КС на поток, находившийся в это время внутри нее, также происходит суммирование времени по всем потокам и вычисление процента для каждого примитива синхронизации от общего простоя [7].
В настоящей статье исследуется модель применения взаимоисключения – семафор, являющийся самым распространенным и часто используемым примитивом синхронизации. Когда несколько процессов запрашивают ресурс, запрашивающий процесс ставится в очередь в соответствии с принципом семафора. В этом случае доступ к запрашиваемому ресурсу осуществляется через очередь. Процесс может занимать ОР в течение длительного времени, пока другой процесс ждет освобождения ОР, так что быстрый процесс может остановиться, ожидая запуска медленного процесса [8].
Можно определить два типа семафоров: живой и неживой. Наиболее часто используемый семафор называется живым, и в системе с N процессами и M ресурсами очередь к семафору может содержать не более N-M процессов. Итак, Т – временной отрезок, в течение которого семафор занят выполнением запроса некоторого процесса; ς – интервал между поступлением запросов к семафору от процессов для получения доступа к ОР. Есть некий процесс p1, который занимает семафор S. Другие процессы в этот момент стоят в ожидании освобождения семафора S и затем также занимают его; так как семафор S занят, они ожидают его освобождения. Причем если N-M больше, чем ς / Т, то чаще всего при очередном запросе процесса p1, ОР занят другим процессом [8]. Таким образом, ЦП в РВС тратит большую часть времени на планирование и диспетчеризацию процессов. И если происходит ситуация, при которой время переключения примерно равно Т, в таком случае к семафору S выстраивается очередь из процессов, запрашивающих ОР. Только в идеализированном случае все процессы имеют одинаковые параметры ς и Т. В реальных же системах ς и Т чаще всего сильно различаются для каждого отдельного процесса.
Доступ к ОР предоставляет диспетчер задач (ДЗ), который производит распределение ресурса (рис. 1). Предположим, что сразу несколько процессов обращаются к семафору с равной интенсивностью поступления запросов, но с разным временем, затрачиваемым на их обработку. Получим среднее время ожидания в очереди к семафору одной заявки, которое можно рассчитать выражением [9]:
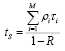 , (1)
, (1)
где ρi = λiτi – нагрузка на семафор, создаваемая i-м процессом, R – суммарная нагрузка на семафор от всех процессов. Если каждый ЦП формирует один тип процесса, то M = n.
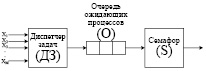
Рис. 1. Модель обслуживания на основе бесприоритетной дисциплины
Критический вопрос управления семафорами придерживается концепции: предоставление ОР в порядке поступления запросов. Чтобы решить текущую проблему, следует сократить среднее время, которое процессы тратят на выполнение действий с использованием ОР [10].
Зачастую, используя стратегию планирования «кратчайшая работа – первой», добиваются сокращения времени выполнения процессов. Для случая с семафором такая стратегия заключается в следующем: есть некие процессы, которые во время своего выполнения запрашивают, как в случае классической задачи «производители-потребители» [3], взаимодействие с семафором чаще одного раза, можно допустить нахождение в очереди ожидающих ОР процессов в любой момент времени уже обслуженных семафором процессов. В системе, удовлетворяющей такому принципу, процессы помещаются в очередь и получают соответствующий приоритет: чем выше номер очереди, тем ниже приоритет (рис. 2). ДЗ выполняет сортировку на основе измеренного времени обработки i-го семафора. Каждый ЦП обрабатывает поток запросов Xi (i = 1,...,n), и время обработки предполагается экспоненциально распределенным. Пусть ДЗ формирует потоки запросов с интенсивностями λ1,…,λn, каждый из которых имеет приоритет ki (i = 1,…,n).
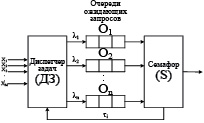
Рис. 2. Модель приоритетного обслуживания
Среднее время ожидания в очереди к семафору одной заявки k-го приоритета составит [9]:
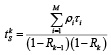 , (2)
, (2)
где ρi = λiτi – нагрузка на семафор, создаваемая i-м процессом, Rk–1 – суммарная нагрузка на семафор от процессов, создаваемых потоками λ1,…,λk–1, Rk – суммарная нагрузка на семафор от процессов, создаваемых потоками λ1,…,λk.
Математическая модель оценки потери времени для процессов, ожидающих на семафоре. Предположим, что в системе есть ОР, защищенный семафором S, к которому могут обращаться несколько процессов. При функционировании вычислительной системы один или несколько процессов формируют свои запросы на занятие семафора S. Модель РВС для оценки производительности из-за конкурирующих процессов, обращающихся к семафору S, показана на рис. 3, a. Она представляет собой сеть, состоящую из n СМО (S1,…,Sn), описывающих функционирование ЦП, и СМО Sn+1, описывающей работу семафора. Фиктивная СМО S0 является источником задач на обработку. В РВС на выполнение поступает поток процессов с интенсивностью λ0 = 1 / t, где t – период поступления запросов на обслуживание, который с вероятностью p01,…,p0n (рис. 3, б) распределяется по ЦП.
Процессы, циркулирующие в РВС, обращаются с запросами к семафору с некоторой интенсивностью λi = 1 / ς, где i = 1,...,n. Предположим, вероятность распределения запросов для каждого ЦП одинакова и составляет p01 =…= p0n = 1/n. Каждый ЦП (S1,…,Sn) посылает запрос в семафор (Sn+1) с определенной вероятностью p1,n+1 =…= pn,n+1. Обработанные на семафоре запросы возвращаются в ЦП с вероятностью pn+1,1 =…= pn+1,n = 1/n.
Примем, что вероятность полностью обслуженного на узле i запроса равна pi0, а вероятность того, что запрос останется обслуженным на узле Si, равна pij, где i,j = 1,...,n.
Среднее время выполнения i-го процесса семафором должно быть аналогично выполнению узла процесса, что характеризует живой семафор [3].
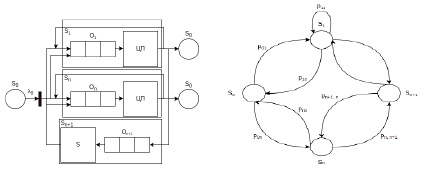
а) б)
Рис. 3. Модельное представление (а) и граф (б) РВС с n-процессорами
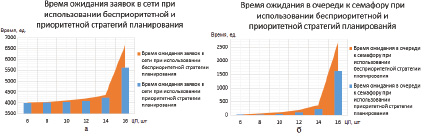
Рис. 4. Время ожидания заявок в сети (а) и время ожидания в очереди к семафору (б) при использовании бесприоритетной и приоритетной стратегий планирования
С целью упрощения расчетов примем, что среднее время обслуживания в ЦП vi = 1 (i = 1,...,n), а среднее время обслуживания в семафоре принято равным 0,8. Определим, что процесс, вызывающий семафор, выполняет в среднем 1000 циклов. В исследовании принято, что запрос покидает систему, с вероятностью pi0 = 0,001, следовательно, с вероятностью 0,999 запрос останется в системе. Предположим, что на каждые 8 единиц времени обработки приходится одна единица обслуживания в семафоре. Таким образом, вероятность того, что запрос останется в ЦП, и вероятность того, что он будет перенаправлен на семафор, составляет в среднем 8 единиц времени. Это означает, что каждый ЦП генерирует запрос семафора каждые 9 единиц времени (ς = 9). Исходя из сказанного, можно получить вероятность запроса семафора некоторым процессом, выполняющимся i-м ЦП, следующим образом pi,n+1 = 1/ς = 0,111 (i = 1,…,n), а вероятность того, что процесс останется на обслуживании в ЦП, можно получить так: pij = 1 – (pi,n+1 + pi0) = 0,888, где (i,j = 1,…,n). Ожидание исполнения задачи в сети определится в соответствие с выражением
Тож = ТЦП + ТS = α1tw1 + α2tw2 + αn+1twn+1, (3)
где ТЦП – время ожидания ЦП, ТS – время ожидания семафора; αi = λi / λ0 – коэффициент передачи (i = 1,…,n+1); twi – время ожидания в i-й СМО, twi = ρivi / (1 – ρi) [11] (i=1,…,n); twn+1 – время ожидания в очереди к семафору.
Интенсивности поступающих входных потоков задач оценим выражением
λi = ∑ pji λj, (4)
где pji – вероятность трансляции задачи из СМО Sj в Si, причем i, j = 1,…,n+1.
Зададим интенсивность λ0 = 0,008 заявок в единицу времени, пусть запросы на вход поступают с заданной интенсивностью. Далее построим график зависимости времени ожидания заявок в сети от числа потоков, обслуживаемых семафором. Параметр n в таком случае варьируется от 6 до 16 ЦП, а длительность обработки запроса семафором при постоянном среднем времени обработки запроса варьируется от 0,4 до 1,4 единиц. В итоге получим, что самый короткий процесс обрабатывается в семафоре за 0,4 единицы времени, а самый длинный – за 1,4 единицы времени.
Результаты расчетов приведены на графиках (рис. 4).
Из графиков видно, что применение приоритетного планирования дает временной выигрыш по ожиданию в очереди к семафору приблизительно на 30–38 % в зависимости от процессоров, в отличие от бесприоритетного планирования.
Заключение
Оценив результаты, приходим к выводу, что синтезированные и исследованные модели позволяют проводить количественные оценки времени ожидания исполнения процессов. Исследуемые в статье модели возможно использовать на практике при разработке новых типов реконфигурируемых вычислительных систем. Практические результаты, полученные в работе, возможно применить для разработки и новых ОС для РВС, где основополагающим является время исполнения процессов: чем оно меньше, тем производительнее будет ОС. Также по проведенному исследованию построены графики, визуально отражающие основные полученные результаты расчетов моделей. Анализируя полученные графики, выявлено, что приоритетное планирование дает возможность уменьшения времени ожидания в очереди к семафору выполняющихся процессов приблизительно на 30–38 %.
Исследование выполнено за счет гранта Российского научного фонда № 21-71-00110, https://rscf.ru/project/21-71-00110/.
Библиографическая ссылка
Мартышкин А.И., Здерев С.Г. Исследование и анализ математических моделей для оценки производительности примитивов синхронизации процессов в реконфигурируемых вычислительных системах // Современные наукоемкие технологии. 2022. № 4. С. 89-94;URL: https://top-technologies.ru/en/article/view?id=39113 (дата обращения: 02.07.2026).
DOI: https://doi.org/10.17513/snt.39113