


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
AN OVERVIEW OF THE NUMBA JIT COMPILER AS A GPU PARALLEL COMPUTING TOOL

В работе рассматриваются сигналы, которые принимают значения -1 или 1 и имеют длину от 1 до 35 тактов. Оптимальным будет считаться сигнал с наибольшим отношением амплитуды основного лепестка автокорреляционной функции к боковому лепестку. Для нахождения оптимального сигнала необходимо вычислить автокорреляционную функцию для всех вариантов сигналов заданной длины.
Полученные в результате выполнения программы оптимальные сигналы могут применяться для решения задач теории сигналов и использоваться, к примеру, в радиолокации. Для разработки программы предлагается использование языка Python с JIT-компилятором Numba и дополнительным модулем numba.cuda для параллельных вычислений на GPU.
Пакет Numba создан компанией Anaconda, Inc. (ранее – Continuum Analytics). Данный пакет даёт возможность ускорить программы при помощи высокопроизводительных функций, написанных непосредственно на языке Python. Использование специальных аннотаций (декораторов с различными параметрами) при функциях, перегруженных вычислениями и/или обрабатывающих массивы, позволяет компилировать код прямо во время исполнения (just-in-time) в машинные инструкции, приближая производительность такого кода к производительности программ, написанных на языках C/C++ и Fortran [1].
Пакет Numba генерирует оптимизированный машинный код с помощью компилятора LLVM. Поддерживается компиляция кода Python для последующего исполнения как на CPU, так и на GPU: в виде ядер и функций для устройств CUDA от nVidia или ядер и функций для устройств HSA (Heterogenous System Architecture) от AMD [2]. В данной статье будет рассматриваться применение пакета Numba для исполнения вычислений на GPU от компании nVidia. Простейший способ работы с Numba – это применять декорирование с помощью декоратора @jit, предписывающее Numba компилировать помеченную функцию, используя заданные при её вызове типы параметров. Можно также указать заранее, для каких типов параметров компилировать функцию, – с помощью строки, именуемой сигнатурой функции и передаваемой декоратору, в которой ключевыми словами типов (или их сокращениями) указаны типы возвращаемого и передаваемых параметров [2].
Большая часть программного интерфейса CUDA доступна через модуль numba.cuda, подключаемый с помощью импорта вида from numba import cuda [3].
Цель данного исследования – исследование возможности использования пакета Numba от Anaconda, Inc для проведения ресурсоемких вычислений на примере определения автокорреляционной функции дискретных сигналов заданной длины.
Материалы и методы исследования
Для расчетов времени вычисления автокорреляционной функции сигнала заданной длины были разработаны четыре программы, каждая из которых является оптимизацией предыдущей программы:
− первая выполняет последовательное вычисление функции для каждой цепочки;
− вторая программа выполняет последовательное вычисление функции для заранее сгенерированного массива цепочек одной длины;
− третья программа выполняет параллельное вычисление функции для заранее сгенерированного массива цепочек одной длины с использованием CPU;
− четвертая программа выполняет параллельное вычисление функции для заранее сгенерированного массива цепочек одной длины с использованием GPU.
Рассмотрим данные программы подробнее (рис. 1, 2).

Рис. 1. Листинги программ с последовательным вычислением АКФ

Рис. 2. Листинги программ с параллельным вычислением АКФ
Программа с последовательным вычислением функции без предварительной генерации массивов выполнена с использованием встроенных функций языка Python и модуля Numpy. В данной программе перевод строки битов из нулей и единиц (простейший вариант представления сигнала заданной длины с двумя возможными значениями в такт времени), а также вычисление амплитуды бокового лепестка вынесены в отдельные функции.
Как было сказано ранее, во второй программе перед вычислением автокорреляционной функции генерируется весь массив цепочек заданной длины. Также во второй программе учитываются особенности работы пакета Numba. Пакет Numba не обрабатывает вызовы сторонних функций внутри задекорированной [4], поэтому перевод строки битов из нулей и единиц, а также вычисление амплитуды бокового лепестка были внесены в основную функцию.
Третья программа отличается от второй только наличием декоратора @jit. Так как вторая программа уже оптимизирована для параллельных вычислений, этого оказалось достаточно, чтобы вычисления проводились параллельно на CPU [5; 6].
В четвертой программе параллельные вычисления были перенесены на GPU. Тут нужно отметить одну важную концепцию: когда какие-либо вычисления должны быть выполнены на GPU, соответствующие данные должны быть перенесены в глобальную память GPU, а результаты вычислений после этого могут быть перенесены обратно на хост. Эти операции выполняются при помощи функций cuda.to_device() и copy_to_host(), предоставляемых в библиотеке Numba на Python [7].
Листинги описанных программ приведены в таблице ниже. Для компактности в приведенных листингах опущены импорты библиотек и вызовы функций, не относящихся конкретно к вычислению автокорреляционной функции.
Результаты исследования и их обсуждение
Измерения времени выполнения программ с последовательным вычислением автокорреляционной функции и программы с параллельным вычислением на CPU производились на персональном компьютере со следующими характеристиками:
− Операционная система: Windows 10 Pro.
− CPU: Intel Xeon x3440 2.5 x 8 ГГц 64-bit.
− RAM: DDR3 2 x 8 Гб.
− ПО: Anaconda ver. 2020.11 с Python 3.9.6.
Из-за невозможности вычисления на GPU с использованием персонального компьютера ввиду отсутствия CUDA-устройства (видеокарты от компании nVidia) измерение времени выполнения параллельных вычислений на GPU было решено проводить с использованием сервиса Colaboratory от компании Google.
Colaboratory, или сокращенно Colab, – продукт компании Google Research. Colab позволяет писать и выполнять произвольный код Python через браузер и особенно хорошо подходит для машинного обучения, анализа данных и образования. С технической точки зрения Colab – это размещенная на хосте служба Jupyter Notebook, которая не требует настройки для использования, но при этом предоставляет бесплатный доступ к вычислительным ресурсам, включая графические процессоры на базе чипов nVidia [8].
Важно заметить, что из-за возрастающей сложности вычислений при каждом увеличении длины цепочки на один бит в два раза, ожидание результата становится неоправданно долгим. Поэтому результаты, ожидание которых достигает 4 ч и более, экстраполируются на более длинные цепочки.
Полученные результаты измерений представлены на графике (рис. 3).
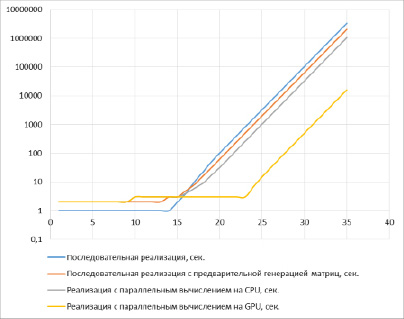
Рис. 3. Результаты измерений
Как видно из рисунка, вычисление автокорреляционной функции (АКФ) для цепочки битов длиной 35 символов занимает 39 суток. При этом даже просто оптимизация кода увеличивает скорость вычислений примерно в полтора раза. Вычисление АКФ для цепочки из 35 битов происходит уже в течение 24 суток.
Применение JIT-компилятора Numba на оптимизированном коде снижает время вычисления более чем в два раза. При использовании только CPU вычисление АКФ для цепочки из 35 бит занимает 12 суток. Это чуть более чем в три раза быстрее, чем вычисление при простейшей последовательной реализации.
При использовании JIT-компилятора Numba с модулем numba.cuda, который позволяет перенести вычисления на GPU от компании nVidia скорость расчета возросла в 66 раз по сравнению с вычислениями на CPU. В данном случае вычисление АКФ на цепочках до 35 символов занимает менее 5 ч. Возможно, при оптимизации программы результат можно улучшить и сократить время расчетов в несколько раз, однако эта задача выходит за рамки данной статьи.
Заключение
Полученные в рамках данной работы данные о скорости параллельных вычислений АКФ с использованием JIT-компилятора Numba в целом и модулем numba.cuda в частности показали, что указанные инструменты действительно помогают ускорить вычисление в десятки раз. Таким образом, с использованием Numba можно добиться вычисления АКФ функции не только до 35-битных цепочек, но и более длинных за адекватное время.
Библиографическая ссылка
Лавринов М.И. ОБЗОР JIT-КОМПИЛЯТОРА NUMBA КАК ИНСТРУМЕНТА ДЛЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ НА GPU // Современные наукоемкие технологии. 2022. № 2. С. 67-71;URL: https://top-technologies.ru/en/article/view?id=39039 (дата обращения: 15.07.2026).
DOI: https://doi.org/10.17513/snt.39039