


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
PLANNING THE PROCESS OF WAREHOUSE OBJECT USE BASED ON PARAMETER SWEEP COMPUTATIONS

Рост товаропотребления оказывает существенное влияние на складской сектор в экономике. Склады являются важными компонентами в цепочках поставок товаров. Повышение эффективности их использования является насущной проблемой любого современного склада. Необходимость оптимизации использования складских объектов возникает как на стадии проектирования складов, так и в процессе их эксплуатации [1].
Склады предназначены для приема, частичной обработки, хранения, сортировки и распространения продукции. Основными задачами оптимизации работы складов являются повышение их производительности и снижение затрат на предоставляемые ими услуги. Большое число изменяющихся во времени структурных и параметрических особенностей складских процессов, которые оказывают непосредственное влияние на показатели производительности и стоимости складских операций, чрезвычайно увеличивают вычислительную сложность решения задачи оптимизации использования складских помещений [2]. Это в свою очередь ведет к необходимости методов и средств решения задачи, обеспечивающих применение высокопроизводительных вычислительных ресурсов [3]. В современных системах моделирования складской логистики [4–7], доступных для массового применения при решении научных и прикладных задач, такие возможности, как правило, ограничены.
Целью исследования является разработка методов и средств планирования использования складских объектов. Методы и средства, разрабатываемые для решение данной задачи, базируются на применении многовариантных расчетов с использованием высокопроизводительных вычислений. Они реализуются в виде специализированного приложения и обеспечивают возможность оперативного проведения экспериментов.
Приложение для планирования использования складских объектов
Процесс моделирования склада включает два основных этапа. На первом этапе решается прямая задача выбора стратегии управления складскими операциями и оптимизации основных показателей работы склада путем исследования его аналитической модели с использованием распределенных вычислений для проведения многовариантных расчетов. На следующем этапе решается обратная задача, заключающаяся в определении параметров выполнения складских операций с учетом найденных оптимальных показателей работы склада и выбранных стратегий управления им.
Выбранная стратегия управления обуславливает формирование расписания обслуживания клиентов. В качестве исходных данных для генерации различных вариантов расписаний обслуживания клиентов в процессе моделирования используются ретроспективные данные о работе склада.
Многокритериальная оптимизация выполняется с использованием статистических данных, получаемых путем воспроизведения работы склада во времени с помощью имитационного моделирования с сохранением логической структуры, связей между событиями и последовательности протекания их во времени. Моделирование выполняется с учетом большого числа технологических характеристик процесса функционирования моделируемого объекта. Результаты моделирования фиксируются в базе расчетных данных и обрабатываются в дальнейшем с помощью различных универсальных и/или специализированных статистических пакетов. На рис. 1 приведен пример схемы базы данных с описанием предметной области (процессов работы склада).
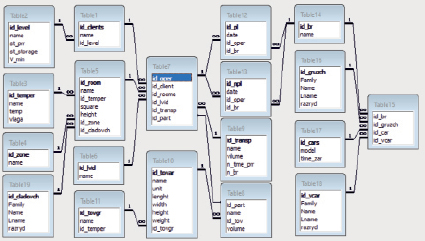
Рис. 1. Схема базы данных с описанием предметной области
В схеме базы данных выделены следующие основные таблицы:
− Table1 − данные о клиенте (поля: наименование, уровень обслуживания);
− Table2 − уровни обслуживания клиентов (поля: наименование, стоимость погрузочно-разгрузочных работ, стоимость хранения, минимальный объем хранения);
− Table3 − температурный режим (поля: наименование, температура, влажность);
− Table4 − товарные зоны (поля: наименование);
− Table5 − сведения о складских помещениях (поля: наименование, температурный режим, площадь, высота, кладовщик);
− Table6 − вид логистической операции (поля: наименование);
− Table7 − сведения о входных и выходных материальных потоках (поля: партия, клиент, помещение, вид транспортного средства, вид логистической операции);
− Table8 − партия товара (поля: наименование, товар, объем);
− Table9 − данные о видах транспортных средств (поля: наименование, грузоподъемность, норма времени проведения погрузочно-разгрузочных работ, требуемое число бригад);
− Table10 − данные о товаре (поля: наименование, единица измерения, длина, ширина, высота упаковки, товарная группа);
− Table11 − данные о товарной группе (поля: наименование, температурный режим);
− Table12 − сведения о плановых заявках (поля: дата/время, логистическая операция, назначенная бригада);
− Table13 − сведения о случайных заявках (поля: дата/время, логистическая операция, бригада);
− Table14 − сведения о бригадах рабочих (поля: наименование);
− Table15 − состав бригады (поля: грузчики, электропогрузчики, водители);
− Table16 − сведения о грузчиках (поля: фамилия, имя, отчество, разряд);
− Table17 − сведения об электропогрузчиках (поля: модель, время зарядки аккумулятора);
− Table18 − сведения о водителях (поля: фамилия, имя, отчество, разряд);
− Table19 − сведения о кладовщиках (поля: фамилия, имя, отчество, разряд).
Схема расчетной базы данных включает следующие таблицы (рис. 2):
− Table20 − сведения о вычислительном эксперименте (поля: имя модели, время начала, время окончания, время выполнения, входные и выходные параметры, используемый вычислительный ресурс, метод многокритериального выбора);
− Table21 – расчетные значения параметров складских помещений (поля: вычислительный эксперимент, складское помещение, температура, влажность);
− Table22 − расчетные значения параметров товаров (поля: вычислительный эксперимент, клиент, товар, количество, складское помещение).
В базе расчетных данных хранится информация обо всех экспериментах. При подготовке расчетов можно загружать данные предыдущего эксперимента, корректировать и использовать их в новом эксперименте. База расчетных данных определенный период времени содержит текущую информацию о работе склада. Затем она переводится в статус ретроспективной информации. Так как она характеризуется большими размерами, предполагается использовать циклическую базу данных, в которой информация о процессах и объектах усредняется и сжимается по прошествии определенных периодов времени. Данная информация будет собираться и обрабатываться специализированной системой мониторинга инфраструктурных объектов, представленной в [8].
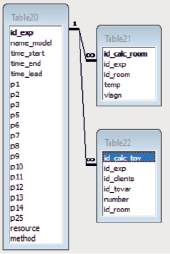
Рис. 2. Схема расчетной базы данных
Приложение для моделирования складских процессов разработано с помощью системы Orlando Tools (OT) [8]. OT применяется для разработки специального класса приложений, которые обеспечивают возможность параллельной обработки структур данных в процессе проведения многовариантных расчетов при решении прикладных задач математического моделирования в разнородных вычислительных средах. В рассматриваемом приложении описание предметной области включает следующие параметры:
− p1 – складские помещения для хранения товаров;
− p2 – товарные зоны;
− p3 – клиенты склада;
− p4 – удовлетворительные уровни обслуживания клиентов;
− p5 – складские операции;
− p6 – транспортные средства;
− p7 − технические средства;
− p8 – товары;
− p9 – товарные группы;
− p10 – критерии работы склада;
− p11 – показатели работы склада;
− p12 – количественные ограничения на пропускную способность склада;
− p13 – критерии расписания обслуживания клиентов;
− p14 – информация о текущем состоянии складских объектов;
− p15 – мощность освоенных услуг (текущих и завершенных);
− p16 – затраты на обеспечение услуг;
− p17 – оценка потенциальной мощности услуг;
− p18 – расписания обслуживания клиентов;
− p19 – суммарный доход;
− p20 – суммарные затраты;
− p21 – оценка мощности неосвоенных услуг;
− p22 – прибыль;
− p23 – рентабельность;
− p24 – оптимальные показатели работы склада;
− p25 – оптимальное расписание обслуживания клиентов.
Прикладное программное обеспечение приложения представлено следующими модулями:
− m1 (p1, p2, p3, p5, p6, p7, p8, p9, p10, p11, p12, p13, p14);
− m2 (p3, p8; p4);
− m3 (p14; p15, p16, p17),
− m4 (p1, p2, p5, p6, p7, p9, p11, p12; p18);
− m5 (p4, p18, p15, p16, p17; p19, p20, p21, p22, p23);
− m6 (p10, p19, p20, p21, p22, p23; p24);
− m7 (p13, p18, p24; p25).
В приведенных выше спецификациях модулей списки их входных и выходных параметров разделены символом ‘;’. Рабочий процесс, реализующий план решения задачи, представлен на рис. 3. Модуль m1 осуществляет подготовку исходных данных. Модули m2 – m4 производят их расщепление. Эти модули могут выполняться параллельно. Экземпляры модуля m5 реализуют многовариантные расчеты на основе расщепленных данных. Модуль m6 производит агрегирование данных. Модули m6 и m7 выполняют многокритериальную оптимизацию. Они реализуют правила многокритериального выбора, представленные в [9].
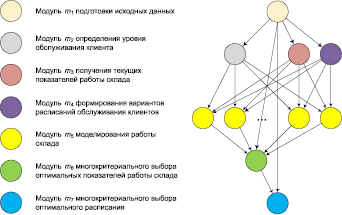
Рис. 3. Рабочий процесс и его модули
Результаты профилирования и тестирования модулей приложения в узлах вычислительной среды позволяют предсказывать время их выполнения на реальных данных [10]. В таблице приведены прогнозное и реальное время выполнения рабочего процесса на ПК и с использованием высокопроизводительного вычислительного кластера [11] для разных экспериментов, отличающихся степенью детализации постановки задачи и, соответственно, числом вариантов. Погрешность предсказания не превышает 8 %. С повышением сложности решения задачи, характеризующейся увеличением числа вариантов расписаний обслуживания клиентов, мощности персональных компьютеров становится недостаточно и преимущество использования высокопроизводительных вычислительных ресурсов становится очевидным.
Время выполнения рабочего процесса
|
Число вариантов |
t1, с |
r1, с |
ε1, % |
t2, с |
r2, с |
ε2, % |
|
142560 |
209,00 |
193,61 |
7,36 |
0,73 |
0,68 |
6,85 |
|
285120 |
418,00 |
388,03 |
7,17 |
1,47 |
1,37 |
6,80 |
|
570240 |
836,00 |
778,46 |
6,88 |
2,94 |
2,74 |
6,80 |
|
1140480 |
1672,00 |
1557,31 |
6,86 |
5,88 |
5,49 |
6,63 |
В таблице переменные интерпретируются следующим образом: t1 и r1 – соответственно прогнозируемое и реальное время решения задачи на ПК, e1 – погрешность прогнозирования для ПК, t2 и r2 – соответственно прогнозируемое и реальное время решения задачи на кластере, e2 – погрешность прогнозирования для кластера.
Заключение
Статья посвящена проблеме решения задач планирования использования складских помещений. Предложен оригинальный подход к ее решению с применением высокопроизводительных вычислений. С этой целью разработано специализированное приложение для проведения крупномасштабных экспериментов на основе многовариантных расчетов. Полученные результаты показали эффективность его применения на практике.
Дальнейшее направление исследований связано с детальной оценкой эффективности складских операций. Методы получения таких оценок будут базироваться на интеллектуальном анализе результатов обработки текущих и ретроспективных данных о работе склада. Представленная в статье схема базы данных обеспечивает необходимые возможности хранения и обработки всей информации о функционировании склада, необходимой для выполнения такого анализа.
Исследование выполнено в рамках проекта IV.38.1.1 программы фундаментальных исследований СО РАН.
Библиографическая ссылка
Башарина О.Ю., Феоктистов А.Г. ПЛАНИРОВАНИЕ ПРОЦЕССА ИСПОЛЬЗОВАНИЯ СКЛАДСКИХ ОБЪЕКТОВ НА ОСНОВЕ МНОГОВАРИАНТНЫХ РАСЧЕТОВ // Современные наукоемкие технологии. 2020. № 10. С. 17-21;URL: https://top-technologies.ru/en/article/view?id=38248 (дата обращения: 27.05.2026).
DOI: https://doi.org/10.17513/snt.38248