


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
MODEL FOR DETERMINING THE NOVELTY OF A REQUEST FOR PROJECT FINANCING VIA TERMINOLOGICAL ANALYSIS METHODS

В 2019 г. Президентом Российской Федерации была утверждена национальная стратегия развития искусственного интеллекта до 2030 г., в перечень задач которой входит разработка интеллектуального программного обеспечения. В рамках реализации этой стратегии представляется актуальной разработка программного обеспечения для проведения экспертных оценок, в частности, как одного из представителей такого класса задач, автоматизированной системы распределения грантов на проектное финансирование.
Попыткой решения этой задачи можно считать создание автоматизированной системы распределения грантов (АСРГ), концепция разработки которой сформулирована авторами в работе [1]. Целью системы является удовлетворение заявки на проектное финансирование на основе экспертного анализа состава заявки, её целей, новизны, ожидаемого эффекта и пр. Авторы данной разработки позволили себе смелость назвать модель проекта Idea, Formalization, Analysis of the Request – IFAR, каковая аббревиатура будет далее использоваться для упоминания о системе.
Целью исследования является разработка автоматизированной информационной системы распределения грантов. Предметом исследования в рамках данной работы является модель определения новизны заявки на проектное финансирование.
Материалы и методы исследования
Предварительный анализ заявки на грантораспределение, предшествующий, собственно, экспертной оценке, по мнению авторов, включает в себя следующие этапы:
1. Определение отраслевой принадлежности заявки. Постановка этой задачи представлена в работе [2]. Идея такой идентификации исходит из универсального характера системы АСРГ, не ориентированного на какую-либо конкретную область деятельности человека. Поскольку последующие оценки основаны на тематическом анализе, требующем привлечения соответствующих тезаурусов, необходимо заранее определить тематическую область, что значительно сократит время, затрачиваемое на анализ. Эта задача решается на этапе определения отраслевой принадлежности.
2. Анализ оригинальности заявки. Включает в себя определение целей анализа на основе целей заявки, сравнение с другими заявками, накопленными в системе, и при необходимости сравнение с иными документами, определёнными целеполаганием заявки.
3. Анализ новизны предлагаемого решения. Этот этап необходим для установления оригинальности предлагаемого заявителем решения и, по мнению разработчиков, представляет некоторый интерес с точки зрения своей реализации, что и является предметом настоящей работы.
Анализ заявки, реализующий три перечисленных этапа, можно представить в виде процессно-поточной модели тематического анализа, схема которой представлена на рис. 1. При создании модели авторы позволили себе отойти от канонических графических примитивов для представления идеи и использовать свои, наилучшим образом отражающие семантику проекта.
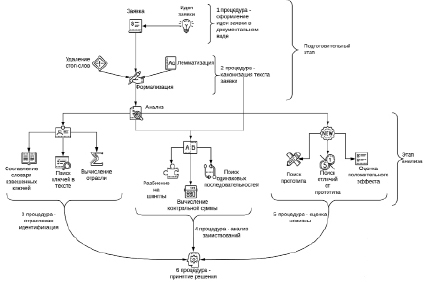
Рис. 1. Модель предварительного анализа заявки
Согласно модели принятие решения о допуске заявки к экспертной оценке состоит из двух этапов:
1. Подготовительный. На данном этапе формируется идея проекта, которая впоследствии формулируется в заявку на финансирование. Текст заявки приводится к каноническому виду, пригодному для дальнейшего тематического анализа, удаляются стоп-символы, стоп-слова, проводится лемматизация [3] каждого термина. Подобная подготовка необходима для дальнейшей обработки заявки методами терминологического анализа.
2. Предметный. На данном этапе анализируется канонический текст заявки, определяется отрасль деятельности, в рамках которой разрабатывается проект, оценивается уникальность проекта и его новизна. Расчет значений указанных метрик заявки является необходимым и достаточным для принятия решения о допуске заявки к дальнейшему прохождению экспертной оценки или отказе в таковом.
Для решения поставленных задач отраслевой идентификации, анализа уникальности и оценки новизны требуется разработать модель заявки. Поскольку данный тип документов не обладает очевидными атрибутами, требуемыми для анализа, в первую очередь следует формализовать заявку. Пусть Docs – множество заявок на проектное финансирование, хранящихся в системе, Req – элементы множества. Коллекцию Docs можно представить в виде множества
Docs = {Req1, Req2,.., Reqk}, (1)
где 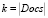 .
.
Модель заявки можно составить на основе формулы изобретения [4]. Этот механизм формализации и определения новизны для заявок на изобретения, прошедший столетнюю апробацию, показал свою высокую эффективность и может быть принят нами как прототип данного решения. Мы назовём данный механизм «формулой заявки».
Состав формулы заявки, сформулированный по методике формулы изобретения, на наш взгляд, наилучшим образом будет отражать признаки – характеристики проекта, участвующего в розыгрыше гранта. В частности, формула заявки предусматривает определение вида проекта и явного перечисления качеств, способных эффективно повлиять на конечный результат, причем для каждого вида заявок определяется свой набор показателей. Заявку можно представить в виде модели
Req = lt;F, C, Vgt;, (2)
где F – формула заявки, C – детальное описание проекта, V – атрибуты заявки, определяемые АСРГ в процессе анализа. Формула заявки может быть представлена следующим кортежем:
F = lt;FT, FS, FNgt;, (3)
где FT – наименование проекта; FS – краткое описание проекта общими признаками, FN – признаки, обеспечивающие новизну решения, причем все признаки представлены термами. Атрибуты АСРГ сопровождаются кортежем
V = lt;I, U, Hgt;, (4)
где I – отрасль заявки; U – уникальность заявки; H – величина новизны проекта. Отраслевая идентификация определяет величину r соответствия заявки g-й отрасли деятельности и рассчитывается по формуле
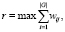 (5)
(5)
где wij – вес j-го терма в i-й отрасли, G – множество отраслей, G = {g1, g2,…, gc}, 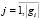 . Авторами данный метод был реализован в программном исполнении и показал высокую эффективность.
. Авторами данный метод был реализован в программном исполнении и показал высокую эффективность.
Анализ заявки на плагиат реализуется с помощью алгоритма шинглов, эффективность которого рассмотрена в работе [5]. Данный алгоритм разбивает канонический текст анализируемой заявки и тексты из архива документов на последовательности, называемые шинглами, причем размер шингла обратно пропорционален эффективности поиска дубликатов. После формирования подстрок вычисляются контрольные суммы последовательностей, совпадение которых между текстом заявки и архивным текстом снижает оригинальность рассматриваемого документа.
Для задачи оценки новизны, несмотря на широкое освещение в научной публицистике (например, [6–8]), не существует универсального решения, так как в большинстве случаев не сформированы наборы показателей для многопараметрических подходов. Например, в работе [9] авторы при решении задачи ранжирования новостей по критерию новизны предлагают учитывать дату публикации новости и скорость появления похожих новостей в сети Интернет. В работе [10] автор предлагает решать задачу оценки новизны через составление словаря маркеров – слов, регулярно появляющихся в авторефератах диссертаций, и дальнейший поиск маркеров в тексте, для которого требуется провести оценку новизны. Широкое распространение получили такие методы выявления новизны, как кластеризация и релевантный анализ. Одним из наиболее известных методов кластеризации является построение самоорганизующейся карты Кохонена (в научной публицистике также встречается обозначение «нейронная сеть Кохонена») [11]. Карта Кохонена распознает схожие элементы в обучающих данных и относит все данные к тем или иным группам, близким по своему содержанию. Обучающие данные для карты формируются на основе векторной модели TF-IDF. Если после проведения кластеризации учебных данных карта обнаружит набор, который по своим характеристикам не принадлежит ни одной из сформированных групп, то она не сможет классифицировать такой набор и тем самым выявит его новизну. Сеть Кохонена работает по принципу соревнования – нейроны второго слоя соревнуются друг с другом за право наилучшим образом сочетаться с входным вектором сигналов [12]. Мерой близости двух векторов чаще всего выступает Евклидова метрика:
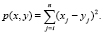 (6)
(6)
Несмотря на широкое применение кластерного анализа в задачах выявления новизны, данный метод более пригоден для выявления отличий. Не каждое отличие приводит к формированию положительного эффекта или эффективности его достижения, в связи с чем авторами было принято решение отказаться от кластерного анализа. На этом основании была сформулирована задача разработки собственного решения, использующего другие подходы к анализу новизны, которые также нужно было разработать.
Новизна – это совокупность новых качеств, устанавливающих достижение положительного эффекта. Качественная оценка таких качеств позволяет выявить актуальность проекта и подтвердить необходимость его реализации. Таким образом, новизну проекта можно представить в виде
H = (D, N) > max, (7)
где N = {ni} – множество качеств, выгодно отличающих проект, D – условие отличия анализируемой заявки от множества других (8), которое выполняется при D gt; 0. Отличие – это признак, создающий разницу между объектами, без оценки качества этого отличия.
D = dif(x, Y), (8)
где 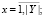
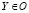 , где O – отрасль деятельности.
, где O – отрасль деятельности.
Процесс решения задачи оценки новизны состоит из трех этапов:
1. Поиск прототипа рассматриваемого предмета.
2. Поиск отличий предмета от прототипа.
3. Оценка декларируемого положительного эффекта.
Поиском прототипа можно считать поиск такой заявки Req из множества Docs, у которой признаки, обеспечивающие новизну проекта, встречаются в других заявках наиболее часто. Множество таких признаков лаконично, элементы в нем не повторяются, что позволяет на первом этапе отказаться от использования метрики TF-IDF [13] в силу отсутствия необходимости учитывать частоту терма. Анализировать список можно только по количеству совпадений признаков. Пусть Sim – количество совпадений признаков из формулы рассматриваемой i-й заявки в списке новшеств заявки из коллекции Docs, d – прототип анализируемого проекта, тогда совпадения можно рассчитать по формуле
di = max Simj, (9)
где 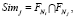
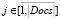 . В случае отсутствия результата можно применить оценку важности признаков. Для этого относительно рассматриваемого множества термов описательной части заявки С сопоставляем каждому признаку (терму) ki величину wi, называемую весом. В этом случае прототипом d проекта, претендующего на грант, можно считать проект, удовлетворяющий выражению
. В случае отсутствия результата можно применить оценку важности признаков. Для этого относительно рассматриваемого множества термов описательной части заявки С сопоставляем каждому признаку (терму) ki величину wi, называемую весом. В этом случае прототипом d проекта, претендующего на грант, можно считать проект, удовлетворяющий выражению
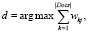 (10)
(10)
где k – терм в детальном описании проекта, w – вес терма, 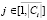 . Установим критерий оценки новизны – Criteria:
. Установим критерий оценки новизны – Criteria:
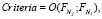 (11)
(11)
где 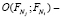 разность между количеством идентичных признаков новизны в заявке из коллекции и количеством признаков новизны в рассматриваемой заявке.
разность между количеством идентичных признаков новизны в заявке из коллекции и количеством признаков новизны в рассматриваемой заявке.
Установим, что величина совпадений новых признаков в рассматриваемой заявке с признаками, предложенными в архивных документах, не может превышать 50 %. Если результат не удовлетворяет данному условию, то есть 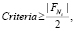 то проект не соответствует критериям новизны, грант в таком случае не может быть одобрен.
то проект не соответствует критериям новизны, грант в таком случае не может быть одобрен.
Данная модель была реализована в виде веб-приложения на базе архитектуры Application Server и стека FAMP – FreeBSD, Apache, MySQL, PHP. Выбор данных средств обусловлен их популярностью, надежностью, гибкостью в настройке и администрировании [14]. В качестве низкоуровневой подсистемы MySQL была выбрана InnoDB, так как данная подсистема поддерживает механизмы транзакций, внешних ключей и полнотекстового поиска. Для работы с MySQL используется библиотека объектно-реляционного отображения RedBeanPHP, которая автоматизирует процесс создания, редактирования и удаления баз данных, таблиц, записей в зависимости от состава данных, подлежащих сохранению.
Схема взаимодействия компонентов системы представлена на рис. 2. В качестве шаблона проектирования был выбран полиморфизм.
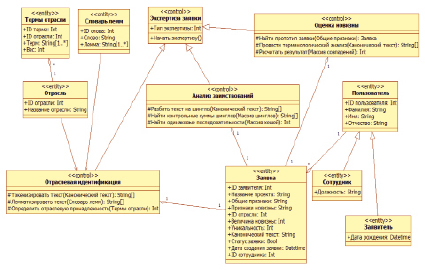
Рис. 2. Взаимодействие компонентов
В соответствии с данным шаблоном каждый тип экспертизы является производным классом от управляющего класса «Экспертиза заявки» и характеризуется своими операциями. Классы-сущности «Сотрудник» и «Заявитель» являются производными от класса «Пользователь», в котором описаны базовые атрибуты всех акторов системы. Диаграмма также отражает мощность отношений между классами проектирования. Например, каждая отрасль деятельности в рамках АСРГ представлена множеством взвешенных тематических ключей, экспертная оценка значимости которых определяет результаты анализа на отраслевую принадлежность. Заявка принадлежит только одному заявителю и рассматривается одним сотрудником.
Выводы
Разработанные критерии и модель помимо данной задачи также могут быть применены для создания программных средств, ориентированных на оценку новизны документированных предметов, а также могут быть использованы в решении иных задач, нацеленных на выявление качественных отличий. Представленная модель была реализована программными средствами и показала высокую эффективность решения.
Библиографическая ссылка
Сироткин А.В., Копченко В.К. МОДЕЛЬ ОПРЕДЕЛЕНИЯ НОВИЗНЫ ЗАЯВКИ НА ПРОЕКТНОЕ ФИНАНСИРОВАНИЕ МЕТОДАМИ ТЕРМИНОЛОГИЧЕСКОГО АНАЛИЗА // Современные наукоемкие технологии. 2020. № 4-2. С. 239-244;URL: https://top-technologies.ru/en/article/view?id=38003 (дата обращения: 20.06.2026).
DOI: https://doi.org/10.17513/snt.38003