


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
BRANCH IDENTIFICATION OF DEMANDS IN THE AUTOMATED EXPERT SYSTEM OF DISTRIBUTION OF GRANTS

В настоящее время возросло количество задач, доверяемых решению автоматизированных экспертных системам. Следует отметить возрастание сложности задач и, как следствие, появление в них интеллектуальных систем, призванных решать задачи, основанные на неформализуемых или плохо формализуемых критериях, требующих использования не только знаний, но и систем, имитирующих работу эксперта, то есть его опыт, интуицию и пр.
Существуют задачи, решение которых требует анализа формализованных критериев наряду с неформализованными, относящихся к узкой области знаний или деятельности человека и общества, оценка принадлежности к которой также требует работы эксперта. К классу таких задач, например, можно отнести рассмотрение и удовлетворение заявок на проектное финансирование по отраслям деятельности, иначе называемое распределение грантов. Анализ и повышение эффективности решения таких задач имеют высокую актуальность, что отражается в работах исследователей, в частности [1].
В подобного вида деятельности практикуется привлечение экспертов, при том, что для этого класса задач не наблюдается широкого освещения в научной публицистике информации о разработке и использовании искусственных систем, основанных на автоматизированных технических решениях. В силу этого возникает возможность формулирования задачи построения автоматизированной системы распределения грантов (АСРГ) с использованием системы искусственного интеллекта, работающей на основе разработанных шаблонов по отраслям знаний.
Работа эксперта по рассмотрению заявки на грант достаточно типизирована независимо от предметной области. Как правило, в современных условиях, с использованием Web-технологий, процесс удовлетворения заявки и взаимодействия с заявителем подчиняется сценарию, приведённому на рис. 1.
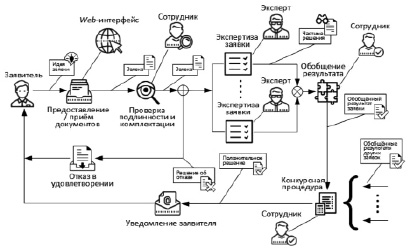
Рис. 1. Диаграмма поточной модели (AS-IS) процесса удовлетворения заявки на грант
1. Заявитель самостоятельно направляет заявку грантооператору с использованием Web-формы.
2. Сотрудник грантооператора проводит первичную оценку заявки на соответствие базовым требованиям.
3. Эксперты проводят анализ заявки на соответствие требованиям и выносят частные решения об удовлетворении заявки.
4. Производится обобщение частных решений и принимается решение об удовлетворении заявки (как правило, сотрудником грантооператора).
5. Заявитель получает уведомление о результатах удовлетворения заявки.
Подобная модель действует для большинства предметных областей, различия могут быть в составе критериев, знаниях, используемых для оценки, а также в составе некоторых процедур оценки, характерных для конкретной отрасли.
Цель исследования: разработка автоматизированной информационной системы распределения грантов. Предметом исследования в рамках данной работы является разработка методики определения принадлежности заявки к конкретной области знания.
Для достижения поставленной цели был проведён анализ процесса рассмотрения заявки в моделях AS-IS и концептуализирован процесс автоматизированного рассмотрения в модели TO-BE.
Организационно-процессная модель удовлетворения заявки (на грант) Θ в модели AS-IS, задающая контекст отношений целевого процесса, может быть представлена следующим образом:
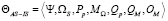 , (1)
, (1)
где Ψ – множество заявок, ΩS – множество экспертов, Pp – множество процедур предварительной оценки (на соответствие требованиям), MΩ – множество процедур экспертной оценки, Qp – множество критериев для предварительной оценки (на соответствие требованиям), QM – множество критериев для экспертной оценки, OM – множество численных оценок.
Статическая модель эксперта в модели AS-IS может быть представлена следующим выражением
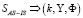 , (2)
, (2)
где k – идентификатор эксперта, Υ – описание атрибутов эксперта, Φ – значение компетенции эксперта в соответствующей области знаний (фиксированное максимальное значение на текущий момент времени).
Исходя из модели (1–2) можно сделать предположение, что возможно построение универсальной системы распределения грантов, пригодной для использования в любой прикладной области, сопровождаемой кортежем
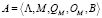 , (3)
, (3)
где Λ – база знаний и фактов для проведения экспертной оценки по не формализуемым или плохо формализуемым критериям, B – отраслевой шаблон экспертной оценки, который устанавливает процедурные различия для проведения оценки для различных предметных областей. Данная модель, в отличие от модели (1–2), содержит только одну процедуру экспертной оценки, поскольку в системе присутствует только один эксперт – АСРГ. Соответственно (3), организационно-процессная модель удовлетворения заявки (на грант) Θ в модели TO-BE может быть представлена следующим образом:
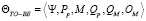 . (4)
. (4)
Приняв данную модель, можно сформулировать задачу разработки универсальной АСГР, контекстная диаграмма которой представлена на рис. 2.
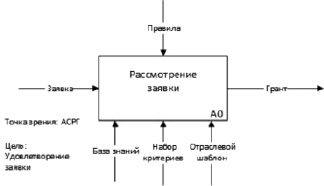
Рис. 2. Главная контекстная диаграмма «Работа универсальной АСРГ»
В пояснение к диаграмме были сформулированы следующие аргументы.
Основным процессом в данной области деятельности является процесс рассмотрения заявки. Отклонение заявки (её неудовлетворение) не является целью и может рассматриваться как отрицательный результат. Целью грантодателя является именно удовлетворение заявок, соответствующих по наборам критериев требованиям выделения средств. Поэтому следует акцентировать внимание на том, что именно удовлетворение, но не рассмотрение заявки является целью всего процесса.
Статическая модель критериев для проведения экспертной оценки QM может быть построена на множествах 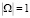 формализованных
формализованных 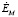 и неформализованных
и неформализованных 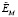 критериев как
критериев как
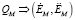 .
.
Статическая модель экспертных оценок OM строится на основе множеств оценок по формализованным критериям 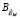 и множестве оценок по неформализованным или плохоформализованным критериям, требующим интеллектуальной оценки,
и множестве оценок по неформализованным или плохоформализованным критериям, требующим интеллектуальной оценки, 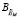
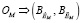 .
.
Модель процесса экспертного оценивания может быть построена как для традиционной модели (1–2), так и для АСРГ (3–4) при условии 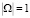 . Её вид может быть представлен следующим кортежем:
. Её вид может быть представлен следующим кортежем:
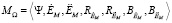 , (5)
, (5)
где R – процесс оценивания на множествах 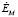 или
или 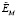 .
.
Диаграмма поточной модели TO-BE, иллюстрирующая модель (5) для АСРГ, представлена на рис. 3.
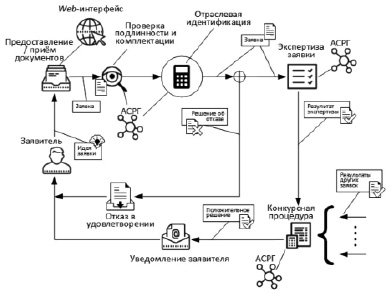
Рис. 3. Диаграмма поточной модели TO-BE работы АСРГ
Статическая модель оценки отдельной заявки может быть представлена выражением
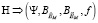 ,
,
где f – функция свёртки обобщённого показателя, принимаемого к розыгрышу гранта. Соответственно модель розыгрыша может быть представлена следующим кортежем:
 ,
,
где G – множество грантов, w – функция выбора (конкурсная процедура).
Реализация модели (3) возможна только после определения отраслевой принадлежности заявки, для чего требуется соотнести поданную заявку с той или иной областью знания. Решение этой задачи возможно различными способами, в том числе методами тематического анализа, достаточно хорошо разработанными для различных документальных массивов.
Отраслевая идентификация может быть решена путём анализа соответствия содержания заявки неким признакам, например, отнесённых по областям знаний классификаторами ГРНТИ, УДК, ББК и др. Однако данный перечень не исчерпывает всех возможных признаков, поэтому реальная реализация системы может быть дополнена собственной, заранее разработанной, базой признаков, построенной на основе развешанных лингвистических ключей.
Предлагаемое решение не предусматривает машинного обучения и построения базы термов на основе анализа документов, как это применяется в общепринятой методологии TF-IDF (например, [2]) или в автоматизированных системах машинного обучения (например, [3] или [4]). Более того, мы предполагаем, что терминологическая база строго формализована для исключения неадекватного трактования предметной области заявки, как, например, предложено в [5].
Предположим, что сформирована база данных, содержащая некоторое множество L отраслей знаний, 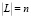 , причём каждой области знания
, причём каждой области знания 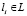 поставлен в соответствие набор Ki признаков или ключевых слов
поставлен в соответствие набор Ki признаков или ключевых слов 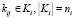 . Пусть R – множество поступивших заявок и
. Пусть R – множество поступивших заявок и 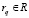 . Относительно рассматриваемого множества R сопоставляем каждому признаку kij относительно заявки
. Относительно рассматриваемого множества R сопоставляем каждому признаку kij относительно заявки 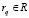 величину
величину 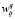 , называемую «весом». Кроме того, определяем частоты
, называемую «весом». Кроме того, определяем частоты 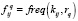 вхождений kij в rq.
вхождений kij в rq.
Далее выявляем значение частного показателя 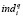 , устанавливающего степень соответствия области знания li заявке
, устанавливающего степень соответствия области знания li заявке 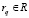 . Для этой цели возможно использование векторной модели (vector space model) метода TF-IDF [6] с учётом длины текста
. Для этой цели возможно использование векторной модели (vector space model) метода TF-IDF [6] с учётом длины текста 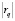 :
:
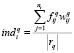 . (6)
. (6)
Для компенсации прямого влияния длины текста на величину ind можно использовать модель, учитывающую усреднённую длину текста Wavg [5]:
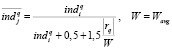 . (7)
. (7)
Модель (7) также не лишена недостатков, в частности не учитывает содержательного разнообразия, за счёт чего многократное повторение одного и того же термина может значительно повысить показатель ind, не имея при этом весомых оснований для отнесения заявки к определённой отрасли знания. Для компенсации этого недостатка может быть предложена следующая модель, основанная на уравнении Шеннона:
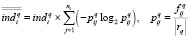 .
.
При определении отраслевой принадлежности возможен случай, когда показатель ind имеет одинаковое максимальное значение более чем для одной области. В этом случае возникает как бы условие конкуренции отраслей знаний за заявку rq. Пусть для некоторых показателей pα и pβ запись H(pα; pβ) означает, что показатель pβ не превосходит показатель pα. Условие конкуренции для отраслей lα и lβ можно выразить следующим правилом:
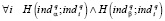 .
.
Выявляем множество
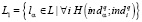 .
.
Если 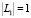 , то заявка
, то заявка 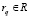 должна быть сопоставлена области знания lα. В случае, когда
должна быть сопоставлена области знания lα. В случае, когда 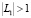 , формируем множество
, формируем множество
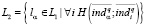 . (8)
. (8)
Множество L2 с одной стороны, с большей степенью вероятности позволяет выявить требуемую область знания lα, с другой стороны, как и в модели (8), позволяет уточнить полученный результат, например
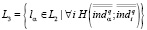 .
.
Выводы
Представленная модель отраслевой идентификации документа может быть использована для проведения предварительного этапа рассмотрения заявки при разработке универсальной автоматизированной системы распределения финансовых грантов. Данный подход также может быть применён к анализу текстов в любой области, при условии использования формализованных множеств термов, например, формализованной тематической рубрикации, классификации документов и пр. Результаты отраслевой идентификации будут использованы для формирования аналитического пакета инструментов, используемого в качестве ресурса для дальнейшего экспертного анализа заявки средствами искусственного интеллекта.
Библиографическая ссылка
Сироткин А.В., Старикова О.А. ОТРАСЛЕВАЯ ИДЕНТИФИКАЦИЯ ЗАЯВОК В АВТОМАТИЗИРОВАННОЙ ЭКСПЕРТНОЙ СИСТЕМЕ РАСПРЕДЕЛЕНИЯ ГРАНТОВ // Современные наукоемкие технологии. 2019. № 7. С. 99-103;URL: https://top-technologies.ru/en/article/view?id=37596 (дата обращения: 17.07.2026).
DOI: https://doi.org/10.17513/snt.37596