


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
MODEL OF CONSTRUCTING A SEMANTIC NETWORK OF SCIENTIFIC TEXT

Семантические сети были разработаны в качестве общего аппарата представления знаний. С момента их разработки они активно использовались в системах обработки естественного языка и оказались одним из самых наглядных способов представления семантики высказываний на естественном языке. Семантические сети являются инструментом представления сложных совокупностей объектов и отношений между ними, которые, в свою очередь, выступают в сети элементами знания [1]. Выводы в семантической сети основаны на анализе отношений между объектами. Модели семантической сети в значительной степени универсальны и являются легко настраиваемыми на любую конкретную предметную область. Задачи, связанные с извлечением знаний из текстов, обучающие системы, информационный поиск, реферирование, проверка корректности терминологических словарей и определений – это далеко не полный список задач, для решения которых успешно используются модели семантических сетей. Для создания семантической сети необходимо провести комплексный анализ текста, который позволит представить взаимосвязь объектов, их свойства и атрибуты, а также определить важность терминов и отношений текста, что даёт возможность сделать выводы о его содержании, наиболее и наименее важных фактах в рамках данного текста и их зависимостей друг от друга.
В настоящее время происходит рост объёмов обрабатываемой информации, в связи с чем растёт потребность в интеллектуальных системах. Следовательно, задачи семантического анализа графики, звука, текста приобретают всё большую актуальность. Наибольшее применение в решении прикладных задач находят методы, базирующиеся на анализе факторных (статистических) характеристик слов и словосочетаний исследуемого текста. Существенной проблемой данных методов является невозможность отображения в полной мере содержания или смысла анализируемого объекта, например текста. Кроме того, при попытке извлечения знаний из построенной семантической сети могут произойти сложности с верной интерпретацией содержания представленных текстовых данных. В связи с вышесказанным для корректного построения семантической сети текста необходимо производить интеллектуальную обработку анализируемых данных, дающую возможность совместно с использованием нечеткой системы определять композиционную структуру текста, а также при помощи предметных онтологий выделять термины и отношения между ними. Предложенная в работе [2] технология построения семантической сети позволяет проследить последовательность действий такой интеллектуальной обработки. В данной работе предпринята попытка формализованного описания предложенной технологии с позиций морфологического представления системы построения семантической сети.
Описание модели системы построения семантической сети
Семантическая сеть, построенная для текстового документа, должна достаточно точно отображать смысл и семантику текста. Поэтому основной задачей при построении семантической сети текста является извлечение его семантики, которая будет максимально отображать смысловой аспект текста. Для решения данной задачи предлагается использовать систему, структурная схема которой представлена на рисунке.
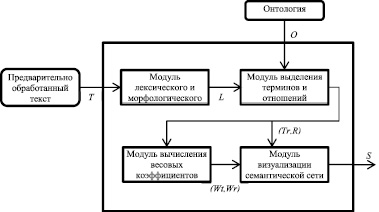
Структурная схема системы построения семантической сети
Система построения семантической сети научного текста представляет собой четверку
D = (Ml, Mtr, Mw, Ms),
где Ml – модуль лексического и морфологического анализа;
Mtr – модуль выделения терминов и отношений;
Mw – модуль вычисления весовых коэффициентов;
Ms – модуль визуализации семантической сети.
На вход данной системы поступает предварительно обработанный текст T = {pi}, i = 1..n, где p – простое предложение, не имеющее однородных членов предложения, личных, указательных, относительных местоимений. На входе кроме этого мы имеем онтологию предметной области О.
Модуль лексического и морфологического анализа Ml на основе T формирует множество описаний лексем
L = {Lxi}, i = 1..m,
Lx = (form, textForm, cid, vid, position, ftp),
где form – нормальная форма лексемы;
textForm – форма лексемы в тексте;
cid – код набора постоянных характеристик лексемы (например, часть речи);
vid – код набора временных характеристик (например, число, падеж);
position – порядковый номер лексемы в тексте;
ftp – код формального текстового признака.
Модуль выделения терминов и отношений Mtr на основе L и с помощью онтологии предметной области O формирует пару (Tr, R), где множество терминов Tr = {Trmi}, i = 1..t , Trmi = {Lxj}, j = 1..l, и множество отношений R = {Rlk}, k = 1..r, Rli = (Trml, Rel, Trmr), в котором тип отношения Rel = Lx в случае наличия функционального отношения между Trml и Trmr или Rel}{«class», «kind», «whole», «part»} в случае нефункционального отношения.
Модуль вычисления весовых коэффициентов Mw для пары (Tr, R) создаёт соответствующую ей пару (Wt, Wr), где Wt = {Wtri} – вес Trmi, Wr = {Wrlk} вес Rlk..
Модуль визуализации семантической сети Ms, являясь агрегатором, собирает результаты работы Mtr и Mw и генерирует семантическую сеть S в виде взвешенного графа (V, T), где множество вершин V = Tr, множество отношений T = R, вес вершины Vi = Wtri, а вес отношения Rk = Wrlk [3].
Далее рассмотрим каждый модуль подробнее.
Модуль лексического и морфологического анализа
На этапе лексического анализа происходит определение содержательно-смысловых блоков текста.
В научном тексте лингвисты определяют четыре логически выделенных содержательных блока:
1) проблема – блок, в котором рассказывается о постановке и понимании проблемы;
2) опыт – блок, в котором перечислен опыт предшественников по данному направлению исследования;
3) решение – блок, в котором предлагается и обосновывается способ решения проблемы, его доказательства и аргументы;
4) итог – блок, в котором происходит обобщение всех полученных данных, а также подводится общий итог.
Для идентификации содержательно-смысловых блоков используется метод поиска формальных текстовых признаков, которые употребляются в том или ином блоке [3].
Для каждого блока существует своё множество текстовых признаков. Так, для блока «Проблема» множество текстовых признаков Mp = {«в данной статье», «в данной работе», «в статье», «рассмотрим», …}, для блока «Опыт» – Me = {«в своих работах», «исходя из опыта ученых», «вспомним», «утверждает, что», …}, для блока «Решение» Md = {«анализ показал», «исследование показало», «заметим, что», «можно выделить», «нужно заметить», …}, для блока «Итог» Mt = {«можем сделать вывод», «в итоге», «отсюда», «таким образом»,…}. Множество M = {Mp, Me, Md, Mt} есть множество формальных текстовых признаков, определяющих различные блоки текста. Так как один и тот же формальный текстовый признак может принадлежать разным блокам, для определения значения ftp для всех Lxi, выделенных в данном абзаце текста, используется нечёткий регулятор [3].
Лексический анализ необходим для разбиения текста документа T на последовательность лексем L. Символы входной последовательности могут принадлежать каким-либо лексемам – A = {«a», «б», «в», «г», «д», «е», «ё», «ж», «з», «и», «й», «к», «л», «м», «н», «о», «п», «р», «с», «т», «у», «ф», «х», «ц», «ч», «ш», «щ», «ъ», «ы», «ь», «э», «ю», «я», «A», «Б», «В», «Г», «Д», «Е», «Ё», «Ж», «З», «И», «Й», «К», «Л», «М», «Н», «О», «П», «Р», «С», «Т», «У», «Ф», «Х», «Ц», «Ч», «Ш», «Щ», «Ъ», «Ы», «Ь», «Э», «Ю», «Я», «0», «1», «2», «3», «4», «5», «6», «7», «8», «9», «№»}, а могут являться символами-разделителями – Dv = {«!», «?», «.», «,», « », «:» «;»}. Только в редких случаях между лексемами не бывает разделителей. Ml представляет каждое pi∈T в виде последовательности символов X. На основе анализа вхождения очередного xi∈X в множества A и Dv можно определить значение textForm и position для очередной лексемы Lxi∈L.
Для проведения морфологического анализа используется функционал библиотеки Mcr.dll, реализующей доступ к словарю на основе n-грамм [4], который позволяет для лексемы Lxi с определённым значением textForm определить значения form, cid, vid.
Модуль выделения терминов и отношений
В данной работе выделение терминов базируется на поиске субстантивных именных словосочетаний, представляющихся моделью согласуемое слово + существительное. Согласно этой модели основой словосочетания является существительное, а в качестве зависимого выступает согласуемое слово, которое, как правило, представляется в виде имени существительного или имени прилагательного. Состав именного словосочетания не ограничивается только существительным и прилагательным. Так же в словосочетании можно встретить наречия, предлоги и сочинительные союзы.
Для выделения терминологических словосочетаний используется КС-грамматика, описанная в работе [2]. Грамматика позволяет определять семантическую связность подряд идущих лексем и определить очередной Trmi∈Tr. Данная грамматика базируется на принципе согласованности лексем, т.е. словоформа в словосочетании должна быть связана с другими словоформами и подходить к ним по временным характеристикам, таким как род, число и падеж.
Стоит учесть, что данные правила не позволяют выделять словосочетания, которые однозначно являются терминологическими. Как правило, качественные и притяжательные прилагательные не входят в их состав (большой дом, широкое распространение) за некоторым исключением. Для определения разряда прилагательного можно успешно использовать Национальный корпус русского языка (ruscorpora.ru).
В научном тексте для построения семантической сети между терминами выделяются квалитативные и квантитативные отношения [5]. Квалитативными отношениями являются отношения иерархии – «род – вид», отношения агрегации – «целое – часть» и функциональные отношения, отражающие прагматику предметной области и имеющие вид «объект действия – действие – субъект действия». Из квантитативных отношений в рамках данной работы рассматривалось только отношение тождества – «синоним».
Выделение очередного функционального отношения Rli∈R происходит с помощью поиска в тексте Lxj со значением cid, определяющим часть речи – глагол и находящуюся между Trmi и Trmi + 1. В таком случае, Rel = Lxj.
Для выделения нефункциональных отношений происходит анализ онтологии O на предмет наличия в них описания терминов Tr [6]. Таким образом, Trmi может быть сопоставлен фрейм Oj. Если фрейм Oi имеет ссылку, определяющую квалитативное отношение, на фрейм Oj, то следовательно можно утверждать, что между соответствующим фреймам Trmi и Trmj также будет квалитативное отношение. В таком случае Rel определяется как «class», «kind», «whole» или «part» в зависимости от типа обнаруженного квалитативного отношения.
Модуль вычисления весовых коэффициентов
В качестве вершин семантической сети научного текста используются термины. Дугами же являются отношения между ними. Весовой коэффициент позволяет количественно определить значимость термина и отношения. Определение весовых коэффициентов терминов и отношений текста является одной из приоритетных задач, так как данные характеристики позволяют определить важнейшие идеи и основную суть всего текста. Под «значимостью» подразумевается как «наличие смысла, значения», так и отношение данного термина к другим терминам в рамках текста. Определение значимости термина происходит на основе анализа критериев значимости:
– частота встречаемости w1: если термин часто встречается в тексте, он образует большее количество отношений;
– категория текста w2: термины, соответствующие тематике текста, являются более значимыми, чем остальные;
– содержательно-смысловой блок w3: термины, встречающиеся в основных содержательно-смысловых блоках, например «итог» или «проблема», являются более значимыми для определения смысла текста.
Для термина Trmi w1 рассчитывается по формуле
w1 = 1 – logmax(r)r, (1)
где r – ранг частоты термина.
Вес w2 принято считать равным 1, в случае, если Trmi отражает тему текста, 0 в противном случае.
Вес w3 принимает различные значения в зависимости от типа содержательно-смыслового блока, в котором встречается Trmi . Для блока «Проблема» w3 = 0,3, для блока «Опыт» w3 = 0,15, для блока «Решение» w3 = 0,25, для блока «Итог» w3 = 0,3. В случае, если Trmi встречается в нескольких блоках, то w3 рассчитывается как сумма значений w3 в соответствующих блоках.
Общий вес Wtri для Trmi рассчитывается по формуле
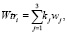 (2)
(2)
где значения k1 = 0,309, k2 = 0,406, k3 = 0,285, вычислены согласно процедуре взвешивания, предложенной в работе [7].
Значимость отношений семантической сети зависит от двух критериев:
– частота совместной встречаемости терминов в данном отношении w1;
– принадлежность отношения к содержательно-смысловому блоку w2.
Значение w1 рассчитывается по формуле 1, где r – ранг частоты встречаемости отношения.
w2 принимает различные значения в зависимости от типа содержательно-смыслового блока, в котором встречается Rli. Для блока «Проблема» w2 = 0,17, для блока «Опыт» w2 = 0,09, для блока «Решение» w2 = 0,35, для блока «Итог» w2 = 0,39. В случае, если Trmi встречается в нескольких блоках, то w2 рассчитывается как сумма значений w2 в соответствующих блоках.
Общий вес Wrli для Rli рассчитывается по формуле
Wrli = w1*k1 + w2*k2, (3)
где значения k1 = 0,425, k2 = 0,575 также вычислены согласно процедуре взвешивания, предложенной в работе [7].
Модуль визуализации семантической сети
Данный модуль предназначен для представления результатов вычислений в удобном для исследователя виде. Исходными данными модуля являются список терминов Tr, список отношений R, а также веса терминов Wtr и веса отношений Wr .
Выходными данными является список смежности графа семантической сети G = {Li}, где i = 1..t, Lsi = (Trmi, Wtri, Linksi), Linksi = {Linkj}, где j = 1..p и p – количество терминов Trmj, с которыми Trmi находится в отношении. Linkj = (Relj, Lsj, Wrj) является описанием связи Trmi с Trmj.
Заключение
Модель построения семантической сети представляет собой систему, включающую четыре взаимосвязанных модуля. Модуль лексического и морфологического анализа использует словарь на основе n-грамм из библиотеки Mcr.dll, что обеспечивает динамичное пополнение словаря. Модуль выделения терминов основан на использовании контекстно-свободной грамматики, которая позволяет расширить количество структур терминологических словосочетаний. При вычислении весовых коэффициентов терминов и отношений учитывается композиционная структура текста. Модуль визуализации обеспечивает проведение экспериментов. Предложенная модель соответствует технологии построения семантической сети, описание которой приведено в ранних работах.
Библиографическая ссылка
Аюшеева Н.Н., Диких А.Ю. Модель построения семантической сети научного текста // Современные наукоемкие технологии. 2018. № 6. С. 9-13;URL: https://top-technologies.ru/en/article/view?id=37025 (дата обращения: 03.07.2026).