


Scientific journal
Modern high technologies
ISSN 1812-7320
"Перечень" ВАК
ИФ РИНЦ = 1,279
ON THE QUESTION OF CHOOSING THE BEST RAID LEVEL FOR DATA STORAGES OF THE INFORMATION SYSTEM THAT PROVIDES FAST PROCESSING OF BIG DATA

Одна из основных функций систем хранения данных – это обеспечение сохранности информации и предотвращение её утраты. Информация может быть утеряна по разным причинам, но чаще всего, если не принимать никаких мер для предотвращения, это происходит при выходе из строя устройств хранения данных (жёстких дисков, серверов и т.д.). По данным статистики вероятность поломки жёсткого диска в первый год равна приблизительно 1,3 % для дисков desktop класса, 1 % для near line класса и 0,5 % для enterprise класса [5]. В крупных системах хранения данных число используемых жёстких дисков может исчисляться сотнями и тысячами, что увеличивает вероятность выхода из строя хотя бы одного из дисков пропорционально их количеству. Так, например, для группы из 100 дисков near line класса ежегодная вероятность выхода из строя в первый год эксплуатации хотя бы одного будет равна 100 %, что приводит к необходимости использования решений для предотвращения утраты информации стоимость которой может намного превышать стоимость её хранилищ.
Основным решением для данной проблемы является использование RAID технологии виртуализации данных, которая объединяет несколько дисков в логический элемент для избыточности и повышения производительности [9]. Существуют различные уровни RAID – архитектуры их построения: RAID 0 (чередование), RAID 1 (зеркалирование), RAID 2 (использование кодов Хемминга), RAID 3 (использование диска чётности, информация разбита на байты), RAID 4 (диск чётности, информация разбита на блоки), RAID 5 (информация диска чётности разбита по всем дискам массива), RAID 6 (дублирование чётности), а также их различные комбинации, например RAID 10 – комбинация RAID 1 и RAID 0 [1]. Они в свою очередь делятся на три различных подхода к реализации по типу RAID контроллера:
1) программный RAID – реализуемый при помощи программного обеспечения и использующий для управления массивом ресурсы ЦП [10];
2) аппаратный RAID – плата расширение или внешнее устройство, применяющие для управления массивом свои собственные процессоры и не использующие ресурсы ЦП;
3) полуаппаратный (интегрированный в материнскую плату) RAID – отдельный чип, встроенный в материнскую плату, выполняющий функции управления массивом, но при этом также использующий ресурсы ЦП.
Выбор уровня и подхода к реализации различной архитектуры RAID зависит от конкретной системы хранения данных, для которой он создаётся.
Для хранилищ данных информационной системы, обеспечивающей быструю обработку больших данных, необходим RAID с максимально возможной вероятностью безотказной работы и производительностью, в пределах заданной стоимости системы.
В соответствии с поставленными условиями для построения RAID лучшими являются аппаратные контроллеры, поскольку, во-первых, при одинаково высокой отказоустойчивости их производительность выше, чем у программных, за счёт того, что они не используют ресурсы серверного процессора, а во-вторых, благодаря использованию собственного процессора могут использовать кэш-память, что положительно сказывается на производительности массива, в особенности при проведении операций записи данных [3].
Для определения наилучшего из уровней RAID в соответствии с этими же условиями необходимо сначала рассмотреть их основные характеристики, представленные в таблице [2].
Основные характеристики уровней RAID
|
Основные характеристики исследуемых уровней RAID |
|||||
|
RAID |
K |
E |
X |
R |
W |
|
0 |
От 2 |
K |
0 |
I*K |
I*K |
|
1 |
Кратно 2 |
K/2 |
От 1 до K/2 |
I*2 |
I/2 |
|
5 |
От 3 |
K-1 |
1 |
I*K |
I*K/4 |
|
6 |
От 4 |
K-2 |
2 |
I*K |
I*K/6 |
|
10 |
От 4, чётное |
K/2 |
От 1 до K/2 |
I*K |
I*K/2 |
|
50 |
От 6, чётное |
K-2 |
От 1 до 2 |
I*K |
I*K/4 |
|
51 |
От 6, чётное |
(K-1)/2 |
От 2 до K/2+1 |
I*K |
I*K/8 |
|
60 |
От 8, чётное |
K-4 |
От 2 до 4 |
I*K |
I*K/6 |
|
61 |
От 8, чётное |
(K-4)/2 |
От 4 до K/2+2 |
I*K |
I*K/12 |
Примечание. K – число дисков, требуемое для создания массива. E – эффективно используемое число дисков (число дисков из общего количества дисков массива, не использующееся для создания избыточности). X – максимально допустимое число вышедших из строя дисков, при котором массив продолжает работу и возможно восстановление хранимой в нём информации. R – IOPS (Input/Output Operations Per Second – количество операций ввода/вывода в секунду) [7]. чтения массива [11]. W – IOPS записи массива [11]. I – IOPS одиночного жёсткого диска, аналогичного жёстким дискам, используемым в массиве.
Из таблицы видно, что производительность массива рассчитывается как среднее арифметическое между его IOPS чтения и IOPS записи. Экономичность напрямую зависит от эффективности использования дискового пространства. Вероятность безотказной работы рассчитывается в соответствии с формулой Бернулли на основе показателя максимально допустимого числа вышедших из строя дисков, при котором массив продолжает работу.
Для одиночного диска вероятность безотказной работы N равна 1 – S, где S – вероятность отказа среднестатистического одиночного жёсткого диска near line класса в результате износа в соответствии с нормальным законом распределения в течение первого года эксплуатации, равная 0,01 при работе 24 часа в сутки 365 дней в году [4].
Массив RAID 0 будет продолжать работать пока работают все его диски, следовательно
N(RAID 0) = 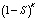 ;
;
Массив RAID 1 работоспособен, пока в каждой паре работают один или оба диска, поэтому его вероятность безотказной работы равна
N(RAID 1) =
= 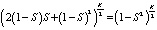 .
.
Массив RAID 5 работоспособен, пока работают все его диски или все кроме одного любого из них:
N(RAID 5) = 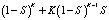 .
.
Аналогичным образом рассчитывается вероятность безотказной работы для массива RAID 6, который сохраняет работоспособность при потере не более двух любых своих жёстких дисков:
N(RAID 6) =
= 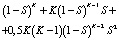 .
.
Вероятность безотказной работы RAID 10, RAID 50 и RAID 60 получается подстановкой в N(RAID 0) вместо вероятности выхода из строя одиночного диска вероятности выхода из строя массива RAID 1 для 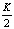 зеркал, RAID 5 и RAID 6 из
зеркал, RAID 5 и RAID 6 из 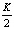 дисков соответственно.
дисков соответственно.
N(RAID 10) = 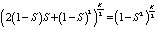 ;
;
N(RAID 50) = 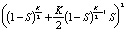 ;
;
N(RAID 60) = 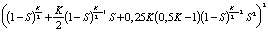 .
.
RAID 51 это два зеркальных RAID 5, поэтому вероятность безотказной работы RAID 51 получается подстановкой в N(RAID 1) при K = 2 вместо S вероятности отказа RAID 5 равную 1 – N(RAID 5).
N(RAID 51) = 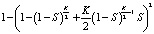 ;
;
Аналогичным образом рассчитывается вероятность безотказной работы для массива RAID 61, являющегося парой зеркальных RAID 6.
N(RAID 61) = 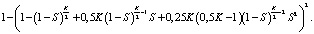
Для определения наилучшего из исследуемых уровней RAID используем функцию оптимальности, зависящую от этих критериев, с учётом ограничений, определяющих важность критериев – вероятность безотказной работы, производительность, эффективность использования дискового пространства при использовании пятибалльной шкалы будет равна 5, 5, 1. Коэффициенты для них соответственно будут равны: 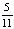 ,
, 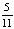 и
и 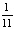 . Поскольку критерии имеют различные единицы и масштабы измерения, их необходимо нормировать. При этом функция оптимальности будет иметь следующий вид:
. Поскольку критерии имеют различные единицы и масштабы измерения, их необходимо нормировать. При этом функция оптимальности будет иметь следующий вид:
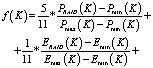
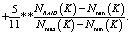 ,
,
где 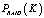 – производительность RAID в IOPS равная среднему арифметическому IOPS чтения и IOPS записи уровня RAID.
– производительность RAID в IOPS равная среднему арифметическому IOPS чтения и IOPS записи уровня RAID.
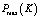 – максимальная производительность, которой можно добиться, используя K дисков.
– максимальная производительность, которой можно добиться, используя K дисков. 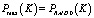 .
.
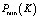 – минимальная производительность, которой можно добиться, используя K дисков.
– минимальная производительность, которой можно добиться, используя K дисков.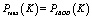 . JBOD (Just a bunch of disks) – дисковый массив, в котором единое логическое пространство распределено по жёстким дискам последовательно [8].
. JBOD (Just a bunch of disks) – дисковый массив, в котором единое логическое пространство распределено по жёстким дискам последовательно [8].
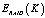 – эффективно используемое число дисков в RAID массиве, состоящем из K дисков.
– эффективно используемое число дисков в RAID массиве, состоящем из K дисков.
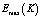 – максимально возможное число эффективно используемых дисков из K доступных.
– максимально возможное число эффективно используемых дисков из K доступных. 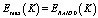 .
.
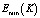 – минимально возможное число эффективно используемых дисков из K доступных.
– минимально возможное число эффективно используемых дисков из K доступных. 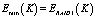 .
.
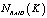 – вероятность безотказной работы RAID массива, состоящего из K жёстких дисков.
– вероятность безотказной работы RAID массива, состоящего из K жёстких дисков.
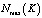 – максимально возможная вероятность безотказной работы группы из K дисков.
– максимально возможная вероятность безотказной работы группы из K дисков. 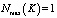 .
.
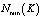 – минимально возможная вероятность безотказной работы группы из K дисков.
– минимально возможная вероятность безотказной работы группы из K дисков. 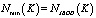 .
.
Поскольку с увеличением числа дисков в массиве растёт вероятность его отказа по различным причинам и потери хранящейся в нём информации, то появляется необходимость в введении ещё одного ограничения на число дисков, входящих в массив. Поэтому будем рассматривать RAID массивы, включающие в себя не более 50 дисков. Графики функций оптимальности f(K) для исследуемых уровней RAID при этом, как показано на рисунке, имеют следующий вид.
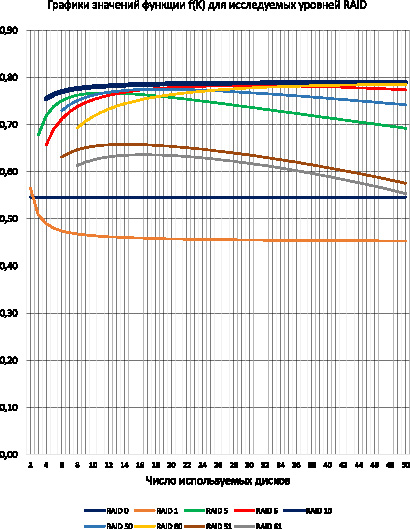
Графики функций оптимальности для исследуемых уровней RAID
Как видно из графиков функций оптимальности для исследуемых уровней RAID, представленных на рисунке, на исследуемом промежутке числа используемых дисков K, значения функции оптимальности для RAID 10 являются максимальными по сравнению со значениями функций оптимальности остальных исследуемых уровней RAID для любого значения K, за счёт наилучшей, после RAID 0, производительности среди всех исследуемых уровней RAID и высокой вероятности безотказной работы, уступающей только аналогичному показателю RAID 6. Остальные исследуемые уровни RAID, построенные на базе первого уровня и сам RAID 1 серьёзно проигрывают десятому по производительности, а построенные на базе пятого с увеличением числа используемых жёстких дисков серьёзно проигрывают ему в вероятности безотказной работы.
Однако также можно заметить, что при числе дисков от 24 до 32 значения функции оптимальности для RAID 6, а при числе дисков больше 30 значения функции оптимальности для RAID 60 практически равны значениям аналогичной функции для RAID 10, что при использовании данного числа дисков делает их достойной альтернативой RAID 10 при необходимости увеличить эффективность использования дискового пространства массива и сократить тем самым расходы на его создание.
Помимо того, что RAID 10 является наилучшим с точки зрения принятой функции оптимальности, он имеет также ряд других преимуществ перед большинством исследуемых уровней RAID. Во-первых, он имеет преимущество в скорости восстановления данных в случае выхода из строя одного из жёстких дисков массива и снижении при этом его производительности [6], поскольку в RAID 10, как и в RAID 1, для восстановления данных будет задействован только один диск зеркальный потерянному, в то время как в остальных исследуемых уровнях RAID, кроме RAID 0, где восстановление вообще невозможно, для этого будут использованы все диски массива, что на время необходимое для восстановления массива создаёт дополнительную нагрузку на систему и существенно снижает скорость её работы.
Вторым преимуществом RAID 10 является то, что вероятность выхода его из строя в процессе восстановления, из-за UER (unrecoverable error rate) – вероятности появления невосстановимой ошибки чтения на жёстком диске, по различным причинам: дефект поверхности, сбой в работе головки, контроллера и т.д. [5], – равна аналогичной у RAID 1 и меньше чем у любого другого уровня RAID. Этим преимуществом он таже, как и первым, обязан тому обстоятельству, что при восстановлении потерянного жёсткого диска используется лишь зеркальный ему жёсткий диск, а не все остальные диски массива, поскольку вероятность невосстановимой потери данных массивом в процессе восстановления по причине UER прямо пропорциональна числу жёстких дисков, которые задействованы в этом процессе.
Подводя итог, можно сделать вывод, что наилучшим RAID массивом для использования в хранилищах данных информационной системы, обеспечивающей быструю обработку больших данных, является массив с архитектурой RAID 10, построенный на базе аппаратного RAID контроллера, поскольку он обеспечивает наилучшее соотношение между высокой производительностью и высокой вероятностью безотказной работы.
Библиографическая ссылка
Атрощенко В.А., Тымчук А.И. К ВОПРОСУ ВЫБОРА НАИЛУЧШЕГО УРОВНЯ RAID ДЛЯ ХРАНИЛИЩ ДАННЫХ ИНФОРМАЦИОННОЙ СИСТЕМЫ, ОБЕСПЕЧИВАЮЩЕЙ БЫСТРУЮ ОБРАБОТКУ БОЛЬШИХ ДАННЫХ // Современные наукоемкие технологии. 2017. № 4. С. 12-16;URL: https://top-technologies.ru/en/article/view?id=36631 (дата обращения: 06.07.2026).