



Для того чтобы помочь пользователям разобраться с программами, установленными на их компьютере, оптимизировать работу на компьютере, освободить память занимаемую приложениями, проверить загружает ли программа что-то из интернета и т.д. , существуют приложения, которые в основном интегрированы в антивирусы, но нет программ в свободном доступе, которая показывает важные для пользователя данные о программах.
Главная задача исследования – помочь пользователю выяснить, какие программы ему нужны обязательно, а без каких он может спокойно обойтись.
Чтобы реализовать программу, осуществляющую автоматизированную классификацию запущенных на компьютере приложений, необходимо произвести многокритериальную классификацию приложений, и отнести запущенное приложение к какому либо разработанному кластеру.
Осуществление классификации приложений удобно производить с помощью Data Mining. Data Mining – не один метод, а некая совокупность различных методов обнаружения знаний. Сам выбор метода во многом будет зависеть от типа имеющихся данных и от того какую информацию необходимо получить в результате.
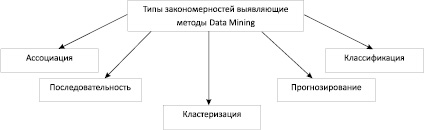
Выделяют пять стандартных типов закономерностей, позволяющие выявлять методы Data Mining (рисунок).
Для будущего исследования наиболее оптимальным типом закономерности б является кластеризация, так как в результате её решения происходит разбиение объектов на группы.
Применение кластерного анализа можно свести к следующим этапам:
1. Выбор объектов для кластеризации.
2. Определить множество переменных, по которым будут оцениваться объекты в выборке, если есть необходимость –нужно нормализовать значения переменных.
3. Вычислить значения меры сходства между всему объектами.
4. Применить метод кластерного анализа и создать группы схожих объектов (кластеров).
5. Представить результаты анализа.
Наиболее подходящим алгоритмом кластерного анализа для данной работы является иерархический алгоритм, так как он характеризуется последовательным объединением исходных элементов и соответственно, уменьшением числа кластеров.
В ходе исследования необходимо изучить методы многокритериальной классификации, точнее Data mining, и создать эффективную систему с помощью инструментария WMI.
Для выполнения поставленной цели необходимо решение следующих исследовательских задач:
• разработка математической модели идентификации типологии приложения на основе его поведения;
• разработка программной системы автоматизированной классификации запускаемых на компьютере приложений;
• оценка эффективности идентификации типологии приложений разработанной системы.