



Введение
Настоящее исследование посвящено автоматическому выявлению индикаторов убеждения в онлайн-дискуссиях и анализу их устойчивости при кросс-языковом переносе. Актуальность работы определяется растущей потребностью в автоматической оценке качества аргументации в образовательных, медиааналитических и модерационных системах, развитием диалоговых моделей, которым требуется учитывать механизмы убеждения при генерации аргументов, а также недостаточной изученностью межъязыковых аспектов персуазивности. Под кросс-языковым переносом (cross-lingual transfer) понимается применение моделей, обученных на англоязычных данных, к русскоязычным текстам – стратегия, необходимая в условиях отсутствия размеченных корпусов для целевого языка.
Персуазивность как коммуникативное явление традиционно описывается в рамках теории аргументации и персуазивной коммуникации [1; 2, c. 273; 3, c. 207–209]. В этих работах подчеркивается многослойная природа убеждения, включающая структурную организацию аргумента, прагматические, эмоциональные и эпистемические компоненты [4, с. 15–16; 5, с. 6–7, 32–33]. Это ставит принципиальный вопрос: какие механизмы убеждения являются универсальными, а какие – лингвоспецифическими? Для автоматизации детекции персуазивности релевантны два измерения: эпистемическое (уверенность, сомнение, оценка достоверности) и аффективно-оценочное (экспрессивность, эмоциональное воздействие), где феномены модальности, эмоциональности и оценочности переводятся в поверхностные признаки. Исследования показывают, что успешность убеждения определяется комплексными характеристиками текста – длиной, аналитичностью, синтаксической сложностью, сниженной нарративностью [6], что смещает фокус от отдельных индикаторов к признакам, отражающим организацию аргумента.
В отличие от задач автоматического извлечения аргументации (argument mining) [7], в детекции персуазивности центральной является разметка по результату убеждения (outcome labeling) – фиксация факта изменения позиции адресата. Ключевым ресурсом для таких исследований стал корпус r/ChangeMyView (CMV) [8], где успешность аргумента определяется присвоением дельты (∆) автором исходного поста [9]. Это позволяет строить масштабные наборы данных и анализировать убеждающее поведение в условиях «добросовестной» дискуссии. В компьютерной лингвистике на базе CMV сформировались два направления. Признаковые модели опираются на интерпретируемые характеристики – структурно-синтаксические метрики, лексическое разнообразие, самореференцию, хеджи, модальность, эмоциональные категории [6] – и позволяют оценивать вклад каждого признака через анализ важности (feature importance). Трансформерные модели обеспечивают более высокое качество классификации благодаря контекстным эмбеддингам [10], улавливающим зависимости, недоступные фиксированным признакам, однако их интерпретация затруднена. Современное состояние методов обобщено в обзоре [11].
Для русского языка ситуация существенно иная: доступные ресурсы ограничены по объему и относятся преимущественно к другим жанрам – эссе, новостным текстам, парламентским дебатам. Исследовательская повестка часто смещена в сторону классификации техник убеждения и пропаганды, особенно в рамках многоязычных соревнований [12–14]. При этом важно различать идентификацию техники убеждения и outcome-детекцию: первая фиксирует прием, вторая – результат изменения позиции адресата. Существующие русскоязычные наборы данных, например PersEssays_Russian, подчеркивают нехватку масштабных корпусов и различия в эффективности традиционных и глубоких моделей при ограниченных данных [15]. Корпуса с outcome-разметкой для русского языка отсутствуют, что делает необходимой стратегию «translate-then-learn» – перенос разметки через машинный перевод. Показано, что кросс-языковой перенос моделей убеждающей коммуникации возможен, но требует учета архитектурных различий моделей и особенностей целевого языка [16; 17].
Однако машинный перевод порождает самостоятельную проблему [18]. Translationese – систематические артефакты перевода (повышенная эксплицитность, сниженное лексическое разнообразие, упрощенный синтаксис, калькирование конструкций) [19] – создают риск смещения при классификации, поскольку значимость признаков может существенно изменяться при переходе между языками [20; 21]. Работы в области кросс-языкового извлечения аргументации подтверждают, что перенос аргументативных структур возможен, но сопровождается падением качества и изменением значимости признаков [22; 23]. Фиксируются и различия в убеждении в русском и английском языках на сопоставимых платформах [24].
В этих условиях особую роль играет сопоставительный анализ устойчивости – сохранения предсказательной силы при переходе между языками (feature stability) и универсальности – способности признака служить индикатором персуазивности независимо от языка. Для кросс-языкового переноса различие между типами моделей принципиально: признаковые модели позволяют сравнивать значимость индикаторов на исходном и целевом языках, тогда как трансформеры задают верхний уровень качества.
В работе формулируются следующие исследовательские вопросы. RQ1: Какой тип модели – признаковый, контекстный или гибридный – обеспечивает наилучший межъязыковой перенос моделей персуазивности? RQ2: Какие поверхностные лингвистические признаки образуют устойчивое кросс-языковое ядро, сохраняя предсказательную силу при переходе от английского оригинала к русскому переводу? RQ3: Какие эффекты translationese влияют на распределение, значимость и важность признаков?
На основании анализа формулируются гипотезы. H1: Контекстные многоязычные модели превосходят поверхностные признаковые в условиях межъязыкового переноса, поскольку учитывают смысл и контекст высказывания и меньше зависят от поверхностных различий между языками. H2: Поверхностные структурные и семантические признаки (длина текста, вариативность, синтаксические расстояния, абстрактность, самореференция) образуют универсальное ядро, устойчивое к переводу и сохраняющее предсказательную силу в обоих языках. H3: Эмоциональные и прагматические признаки (хеджи, модальность, отдельные эмоции) более чувствительны к translationese, сглаживающему эмоциональность и нормализующему прагматические маркеры.
Цель исследования – определить, какие типы моделей сохраняют способность различать персуазивные и неперсуазивные тексты при переходе от оригинала к переводу и какие поверхностные признаки остаются устойчивыми к переводу.
Материалы и методы исследования
Эмпирической базой исследования послужил корпус онлайн-дискуссий r/ChangeMyView, содержащий 22 765 комментариев с бинарной разметкой успешности убеждения. Для анализа кросс-языкового переноса создан параллельный англо-русский (EN–RU) корпус. Английские комментарии автоматически переведены на русский язык посредством Google Translate с сохранением идентификаторов и меток, тексты предобработаны единым пайплайном (очистка, токенизация, лемматизация, POS-разметка). Исходное распределение классов было несбалансированным: персуазивные комментарии – класс 1 (12 420 записей) значительно преобладали над неперсуазивными комментариями – классом 0 (7294 записи). Кроме того, 3051 комментарий был отнесен к категории неидентифицированных высказываний (класс 2). Для подготовки данных применен случайный андерсэмплинг мажоритарного класса и исключены неидентифицированные записи. Итоговый корпус составил 14 564 комментария с идеально сбалансированным распределением: 50 % персуазивных и 50 % неперсуазивных комментариев (табл. 1).
Таблица 1
Итоговый корпус со сбалансированными классами
|
Язык |
Класс |
Комментарии |
Общее количество слов |
Уникальные словоформы |
|
English |
Persuasive (1) |
7282 |
1 350 415 |
30 726 |
|
English |
Non-persuasive (0) |
7282 |
1 272 351 |
28 631 |
|
Russian |
Persuasive (1) |
7282 |
1 172 609 |
71 571 |
|
Russian |
Non-persuasive (0) |
7282 |
1 097 487 |
67 040 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Сопоставляются три подхода: признаковая модель (CatBoost) на 74 лингвистических признаках; mBERT (Multilingual Bidirectional Encoder Representations from Transformer) как контекстная многоязычная модель для переноса без дообучения на целевом языке; гибридная архитектура (mBERT + признаки) для оценки информативности признаков сверх контекстных эмбеддингов. Качество детекции и переноса персуазивности оценивается метриками accuracy, macro-F1 и ROC-AUC. Для анализа переносимости признаков с помощью CatBoost определялась важность каждого из 74 лингвистических признаков отдельно для английского и русского корпусов – это позволило ранжировать признаки по их вкладу в предсказание персуазивности. Признаки охватывают структурно-синтаксические характеристики (длина, вариативность, сложность, POS-распределения), лексическое разнообразие, самореференцию, дискурсивно-когнитивные показатели (хеджи, уверенность, когерентность, абстрактность), эмоциональность (NRC-эмоции). Далее было выявлено пересечение наиболее важных признаков в обоих языках, а также рассчитана корреляция Спирмена между рангами важности для количественной оценки согласованности. Наконец, устойчивые признаки, вошедшие в топ обоих языков, интерпретировались как универсальные индикаторы персуазивности, сохраняющие предсказательную силу независимо от языка, тогда как признаки, специфичные только для одного языка, рассматривались как лингвоспецифические или потенциальные артефакты машинного перевода.
Результаты исследования и их обсуждение
Сравнение CatBoost, mBERT и гибридной моделей (табл. 2) демонстрирует, что признаковые и контекстные подходы фиксируют принципиально разные уровни языковой информации.
CatBoost, основанный на поверхностных статистических характеристиках, демонстрирует слабое качество детекции персуазивности (accuracy ≈ 0,57) и ограниченную переносимость. Предсказания модели зависят от эмоциональных, прагматических и лексических индикаторов, наиболее подверженных трансформациям при переводе. Напротив, mBERT достигает более высокой точности (0,662 на английском корпусе) и сохраняет работоспособность в zero-shot режиме (0,615 на русских переводах), что подтверждает преимущество контекстных многоязычных моделей в задачах кросс-языкового переноса. Контекстные модели опираются на динамические семантические и прагматические зависимости, а не на фиксированный набор поверхностных признаков. Гибридная модель (0,64) занимает промежуточное положение – она улучшает баланс классов, но не превосходит mBERT по общему качеству, что указывает на избыточность добавления поверхностных признаков к трансформерным представлениям с точки зрения предсказательной силы.
Анализ матрицы ошибок (рис. 1) показывает выраженную асимметрию в работе модели: она хуже распознает убедительные аргументы, чем неубедительные. Из 1456 убедительных аргументов модель корректно классифицирует 812, тогда как из 1457 неубедительных – 1076. Ошибок пропуска убедительных аргументов (644 случая) больше, чем ошибок ложного приписывания убедительности неубедительным (381 случай), однако обе группы ошибок остаются значительными. Большая часть ошибок приходится на аргументы со смешанными признаками убедительности, где убедительность выражена имплицитно и не опирается на явные лексические маркеры. Именно такие «пограничные» случаи формируют основную массу неверных классификаций.
Таблица 2
Сравнение CatBoost, mBERT и гибридной моделей
|
Модель |
Язык |
Accuracy |
Precision |
Recall |
F1-score |
Macro F1 |
ROC-AUC |
|
CatBoost |
EN |
0,572 |
0,57 |
0,57 |
0,57 |
0,57 |
0,59 |
|
CatBoost |
RU |
0,567 |
0,57 |
0,57 |
0,57 |
0,57 |
0,59 |
|
mBERT (fine-tuned) |
EN |
0,662 |
0,66 |
0,66 |
0,66 |
0,66 |
0,72 |
|
mBERT (zero-shot) |
RU |
0.615 |
0.62 |
0.61 |
0.61 |
0,61 |
0,70 |
|
Hybrid (CatBoost + mBERT) |
EN |
0.640 |
0.64 |
0.64 |
0.64 |
0,64 |
0,71 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
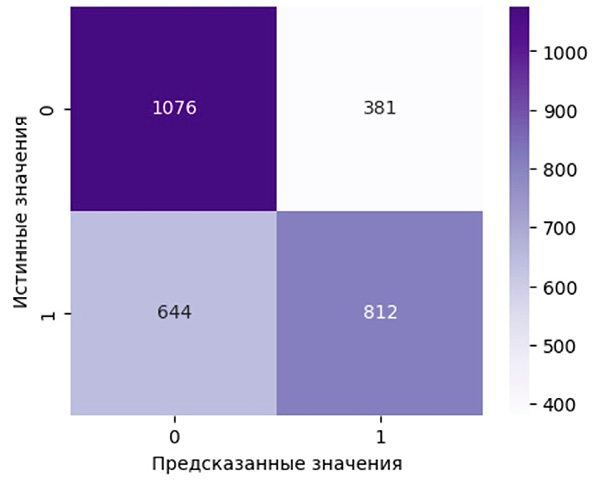
Рис. 1. Матрица ошибок Примечание: составлен авторами по результатам данного исследования
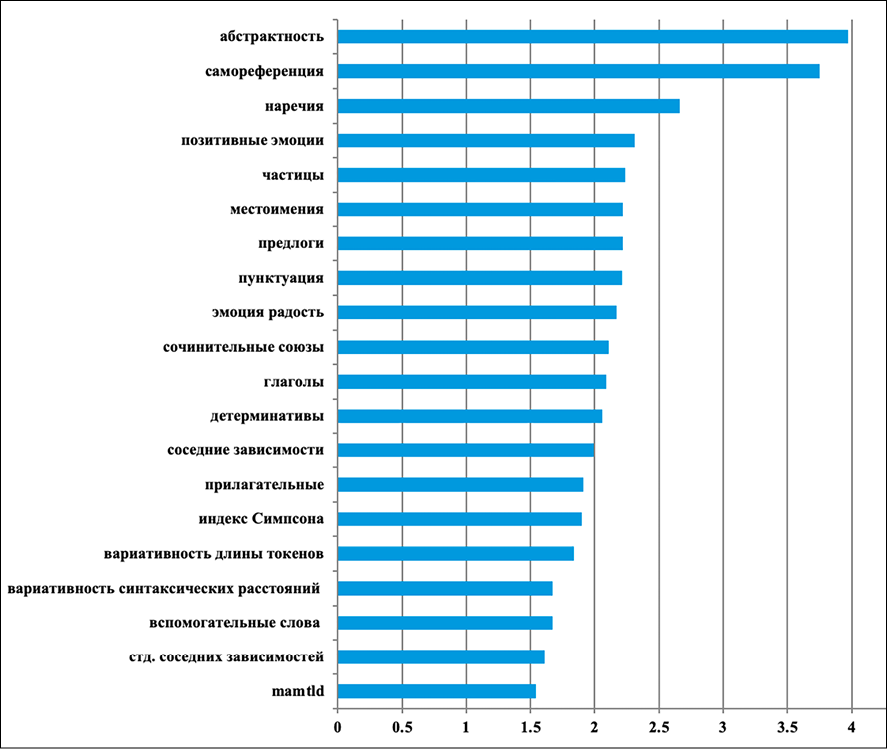
Рис. 2. Топ-20 признаков (EN) для детекции персуазивности Примечание: составлен авторами по результатам данного исследования
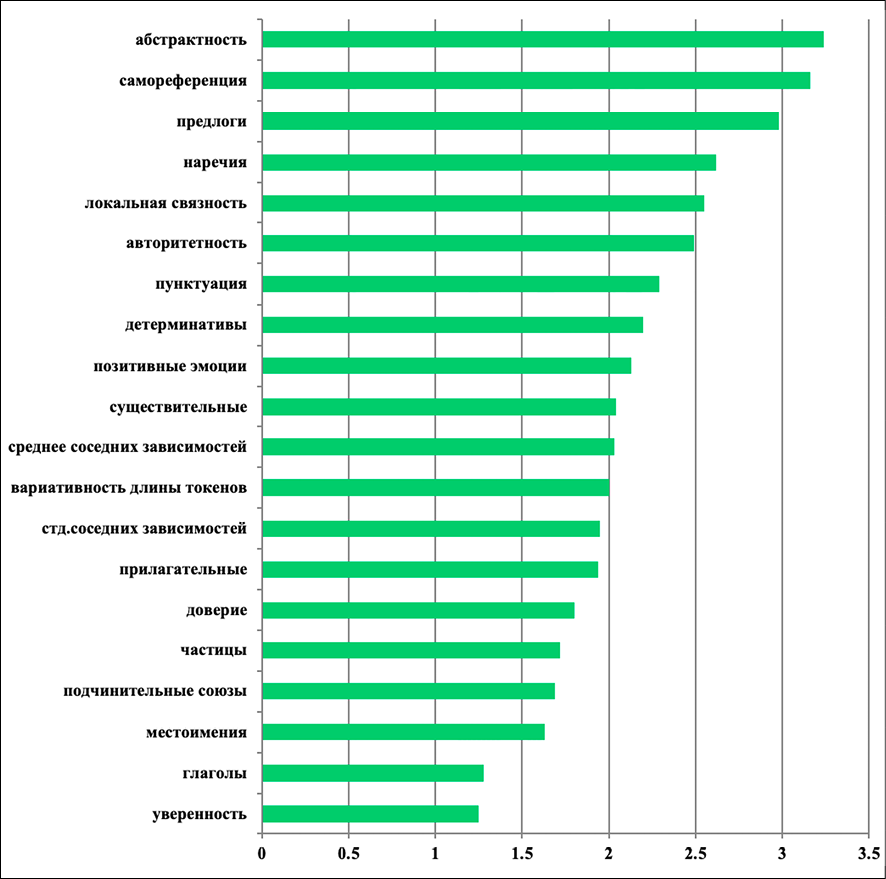
Рис. 3. Топ-20 признаков (RU) для детекции персуазивности Примечание: составлен авторами по результатам данного исследования
При этом mBERT и гибридная модель демонстрируют различные профили ошибок на переводных данных. Неперсуазивные тексты после перевода становятся более структурированными и когерентными, что приводит к ложноположительным классификациям, тогда как мягкие, эмпатические формы убеждения чаще остаются незамеченными. Эти наблюдения указывают на то, что персуазивность включает как структурный, так и прагматический уровни и что translationese воздействует на них неодинаково. Структурные характеристики могут усиливаться за счет нормализации синтаксиса, тогда как тонкие эмоциональные и прагматические сигналы сглаживаются.
Анализ устойчивых/неустойчивых индикаторов убеждения (рис. 2, 3) показал следующее.
Для английского языка ключевыми предикторами персуазивности являются абстрактность (3,97) и самореференция (3,75), которые занимают две верхние позиции. Использование абстрактной лексики и личных местоимений демонстрирует вовлеченность автора и повышает доверие читателя. Морфологические признаки также значимы: наречия (2,66), частицы (2,24), местоимения (2,22) и предлоги (2,22) структурируют текст и добавляют убедительности. Пунктуация (2,21) и сочинительные союзы (2,11) организуют аргументацию. Эмоциональный компонент представлен радостью (2,17), позитивными эмоциями (2,31) и доверием (1,41), что указывает на важность оптимистичного тона и создания доверительной атмосферы. Для русского языка ключевыми предикторами персуазивности выступают абстрактность (3,24) и самореференция (3,16), что совпадает с английскими данными. Морфологические признаки – предлоги (2,98), наречия (2,62) и детерминативы (2,20) – играют более значимую роль, чем в английском корпусе. Это указывает на важность логической структуры и связности изложения для русскоязычных аргументов. Эмоциональные характеристики представлены авторитетностью (2,49), позитивными эмоциями (2,13), доверием (1,80), удивлением (1,55) и страхом (1,46). Персуазивные русские тексты характеризуются демонстрацией авторского контроля над темой. Синтаксические метрики занимают высокие позиции в обоих языках, что подтверждает универсальность роли синтаксиса для построения убеждающих высказываний. Чем проще и понятнее построены предложения (слова короче, связей между словами больше, зависимости короче), тем легче читателю следить за логикой и тем убедительнее воспринимается текст.
При переходе от английского оригинала к русскому переводу выделяется устойчивое кросс-языковое ядро из 21 признака, которые сохраняют предсказательную силу в обоих языках. Ядро включает структурно-синтаксические метрики (вариативность длины слов и предложений, синтаксические расстояния, доля соседних зависимостей), частеречные распределения, абстрактность, самореференцию, позитивные эмоции и доверие. Эти признаки сохраняют согласованные ранги важности, что подтверждает существование универсального структурного компонента персуазивности – лингвистического ядра, остающегося значимым вне зависимости от языка. В то же время выявлена группа признаков, чувствительных к translationese и маркирующих границы применимости стратегии «translate-then-learn». В английских текстах значимыми оказываются эмоциональные категории радость, печаль, критика и метрики лексического разнообразия, тогда как в русских переводах усиливаются локальная связность, номинативность, искусственное преобладание маркеров уверенности/неуверенности, появляются артефакты перевода – сохранение английских синтаксических структур в русском переводе. Эти сдвиги отражают системные эффекты машинного перевода – сглаживание эмоций, снижение разнообразия и нормализацию синтаксиса – и демонстрируют большую уязвимость эмоциональных и прагматических признаков по сравнению со структурными. Корреляция Спирмена между рангами важности признаков на EN и RU составляет 0.66 (p < 0,01). Это указывает на то, что структурно-синтаксические индикаторы показывают высокую согласованность, тогда как эмоционально-оценочные – значительное расхождение.
Сравнение моделей для кросс-языкового переноса (RQ1) показывает, что mBERT обеспечивает наилучшие результаты благодаря способности улавливать семантические зависимости, не привязанные к конкретным лексическим маркерам. Однако переводные неперсуазивные тексты становятся более структурированными, что приводит к ложноположительным ошибкам и асимметрии классификации. Гибридная модель превосходит CatBoost, но уступает mBERT, что указывает на отсутствие синергии между признаками и контекстными эмбеддингами: значительная часть лингвистической информации уже содержится в представлениях трансформера. CatBoost демонстрирует сопоставимые результаты на EN и RU, что говорит о стабильности набора признаков (абстрактность, самореференция, синтаксис, POS-распределения), но также об ограниченной переносимости поверхностных индикаторов, чувствительных к translationese.
Анализ устойчивого кросс-языкового ядра признаков (RQ2) выявил 21 индикатор, отражающий фундаментальные механизмы аргументации. Наиболее стабильны абстрактность и самореференция, а также позитивные эмоции и признак доверие. Специфические эмоции (радость, страх, печаль) теряют предсказательную силу при переводе, что указывает на универсальность не отдельных эмоций, а позитивно-доверительной тональности. Структурные и когнитивные признаки оказываются наиболее устойчивыми, тогда как эмоционально-прагматические – уязвимыми и потенциально лингвоспецифическими. Анализ влияния translationese (RQ3) показывает, что машинный перевод усиливает структурную организованность текста и ослабляет эмоциональные сигналы. Точность всех моделей (от слабой до умеренной) отражает сложную природу персуазивности, основанную на фреймировании, нарративных стратегиях и имплицитных сигналах, а также субъективность разметки CMV.
Ограничения исследования связаны с использованием одного переводчика, что затрудняет разделение общих эффектов translationese и артефактов конкретной системы перевода. Лексическая природа эмоциональных признаков может недооценивать имплицитную эмоциональность, а жанровая специфика CMV ограничивает переносимость выводов на другие типы дискурса.
Заключение
Авторы оценили кросс-языковой перенос персуазивности на параллельном корпусе r/ChangeMyView, сравнив CatBoost на лингвистических признаках, mBERT и гибридную модель. Результаты подтверждают все три гипотезы. mBERT демонстрирует наилучший перенос (гипотеза H1), что связано со способностью модели улавливать семантико-прагматические зависимости, менее чувствительные к межъязыковым различиям. Анализ важности признаков выявил устойчивое ядро индикаторов, подтверждая гипотезу H2: структурно-синтаксические метрики, когнитивные показатели и базовые эмоциональные категории сохраняют предсказательную силу при переводе. В то же время специфические эмоции, лексическое разнообразие и прагматические маркеры оказались чувствительными к translationese, что подтверждает гипотезу H3. В целом результаты демонстрируют, что детекция персуазивности является сложной задачей, персуазивность различима слабо, но устойчиво, а перевод ослабляет ее детекцию.
Перспективы включают проверку результатов на оригинальных русскоязычных данных, расширение языкового охвата и интеграцию более глубоких прагматических характеристик.
Конфликт интересов
Финансирование
Библиографическая ссылка
Дрожащих Г.А., Дрожащих Н.В. Кросс-языковой перенос персуазивности: сравнение моделей и анализ устойчивости индикаторов // Современные наукоемкие технологии. 2026. № 4. С. 324-332;URL: https://top-technologies.ru/ru/article/view?id=40768 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40768