



Введение
Задачи глобальной оптимизации, возникающие в математическом моделировании, численных методах и прикладных вычислениях, характеризуются высокой размерностью, сложным рельефом целевой функции и наличием множества локальных экстремумов. В таких условиях широкое распространение получили эволюционные методы поиска, в частности генетические алгоритмы, благодаря их универсальности, слабой зависимости от аналитических свойств целевой функции и способности работать в условиях многоэкстремальности [1, с. 44–54; 2, с. 1–18]. Вместе с тем эффективность генетического алгоритма в значительной степени определяется выбором параметров операторов и режимом организации поиска на различных этапах эволюции.
Одной из наиболее существенных проблем классического генетического алгоритма остается преждевременная сходимость, проявляющаяся в быстром снижении разнообразия популяции и последующей стабилизации поиска в области локального экстремума. Эта проблема особенно заметна при решении многомерных задач непрерывной оптимизации, где фиксированные значения вероятностей мутации и кроссовера оказываются недостаточно универсальными: параметры, способствующие интенсивному исследованию пространства решений на начальных этапах, нередко оказываются неэффективными на стадии локального уточнения, и наоборот [1, с. 89–124; 2, с. 62–70]. В связи с этим важным направлением развития эволюционных методов является адаптивное управление процессом поиска, при котором параметры алгоритма изменяются в зависимости от текущего состояния популяции.
В современной литературе представлены различные подходы к адаптации параметров эволюционных алгоритмов. Наиболее распространены схемы динамической настройки вероятностей мутации и кроссовера, а также методы выбора операторов поиска на основе анализа текущей эффективности эволюционного процесса [3; 4]. В последнее время особое внимание уделяется применению обучения с подкреплением, в рамках которого эволюционный поиск рассматривается как управляемая динамическая система, а стратегия изменения параметров формируется агентом на основе последовательности состояний, действий и получаемых вознаграждений [5, с. 1–10]. Такой подход позволяет перейти от фиксированных или эвристически заданных правил настройки к выработке адаптивной стратегии управления, учитывающей историю поиска и текущий прогресс по целевой функции.
Дополнительный интерес представляет использование глубокого обучения с подкреплением, в частности архитектур глубокого Q-обучения, позволяющих отказаться от жесткой дискретизации пространства состояний и перейти к работе с более информативным набором признаков, описывающих состояние популяции. Применение модификаций глубокого Q-обучения, ориентированных на повышение устойчивости оценки ценности действий, расширяет возможности построения интеллектуальных контуров управления эволюционным поиском [6; 7]. Однако даже в таких постановках объект управления чаще всего ограничивается только вероятностями кроссовера и мутации, тогда как проблема поддержания разнообразия популяции обычно решается отдельно, с помощью заранее заданных эвристик.
Для сопоставимой оценки эффективности методов глобальной оптимизации в литературе широко используются стандартные тестовые функции, различающиеся структурой рельефа целевой поверхности, размерностью и сложностью поиска глобального минимума [8]. Применение такого набора функций позволяет исследовать поведение алгоритма как на сравнительно простых задачах, так и на сложных многоэкстремальных функциях, требующих поддержания баланса между исследованием пространства решений и локальным уточнением найденных областей.
Дополнительный интерес в этой связи представляет проблема сохранения разнообразия популяции в процессе эволюционного поиска. В работах, посвященных оптимизации многоэкстремальных функций, отмечается, что снижение разнообразия популяции является одной из основных причин преждевременной сходимости. Для повышения устойчивости поиска применяются ансамблевые и гибридные схемы, а также специальные механизмы поддержания разнообразия популяции [9–11]. Отдельно исследуются методы динамической коррекции области поиска [12]. Однако в большинстве таких подходов поддержание разнообразия реализуется по заранее заданным правилам и не рассматривается как самостоятельный объект адаптивного управления.
В опубликованных и подготовленных ранее работах автора последовательно рассматривались подходы к адаптивному управлению параметрами генетического алгоритма на основе искусственных нейронных сетей, табличного Q-обучения и глубокого обучения с подкреплением [13; 14]. Эти исследования показали перспективность интеллектуального регулирования вероятностей мутации и кроссовера, однако также выявили, что при длительном поиске и на сложных многоэкстремальных функциях одного лишь параметрического управления нередко оказывается недостаточно для устойчивого предотвращения стагнации. Это указывает на необходимость расширения контура управления и включения в него механизмов, непосредственно воздействующих на уровень разнообразия популяции.
Научная новизна исследования состоит в разработке метода адаптивного управления эволюционным поиском, в котором агент глубокого обучения с подкреплением формирует управляющее воздействие одновременно по трем компонентам: вероятности мутации, вероятности кроссовера и доле популяции, подлежащей замене новыми решениями. В отличие от ранее рассмотренных схем, предлагаемый подход ориентирован не только на улучшение текущего значения целевой функции, но и на предотвращение деградации поискового процесса за счет контролируемого восстановления разнообразия популяции. Это позволяет рассматривать предлагаемый метод как развитие ранее исследованных автором моделей управления генетическим алгоритмом.
Целью работы является разработка и исследование метода адаптивного управления процессом эволюционного поиска в генетическом алгоритме на основе глубокого обучения с подкреплением, обеспечивающего совместное регулирование параметров вариации и интенсивности частичной реинициализации популяции. Для достижения поставленной цели в статье предполагается решить следующие задачи: сформировать математическую модель управляемого эволюционного поиска; определить состав признаков состояния популяции, используемых агентом; задать пространство управляющих воздействий и функцию вознаграждения; реализовать программный прототип метода; провести вычислительные эксперименты на наборе тестовых функций многомерной оптимизации, различающихся структурой рельефа и сложностью поиска глобального минимума.
Практическая значимость работы определяется возможностью применения предложенного подхода в задачах численной оптимизации, где требуется автоматическое управление балансом между исследованием пространства решений и локальным уточнением найденных областей. В отличие от схем с фиксированными параметрами и от методов, в которых поддержание разнообразия задается заранее, предлагаемый метод ориентирован на ситуационное изменение режима поиска, что особенно важно для сложных многоэкстремальных задач и прикладных постановок с признаками стагнации.
Материалы и методы исследования
В работе рассматривается задача минимизации целевой функции
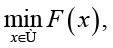
где x = (x1, x2,…,xn) – вектор искомых параметров, Ω ⊂ ℝn – допустимая область поиска, F(x) – целевая функция. Для решения задачи используется генетический алгоритм, в котором процесс эволюционного поиска рассматривается как управляемая динамическая система.
В отличие от классического генетического алгоритма с фиксированными параметрами, в предлагаемом подходе значения вероятности мутации, вероятности кроссовера и интенсивности пополнения популяции новыми особями изменяются адаптивно в зависимости от текущего состояния поиска. Такой подход направлен на повышение устойчивости поиска и снижение вероятности преждевременной сходимости к локальным экстремумам [1, с. 89–124; 2, с. 62–70].
Состояние алгоритма на итерации t описывается вектором
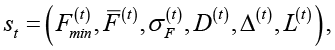
где 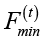 – лучшее значение целевой функции в популяции,
– лучшее значение целевой функции в популяции, 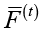 – среднее значение,
– среднее значение, 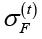 – стандартное отклонение значений целевой функции, D(t) – показатель разнообразия популяции, Δ(t) – относительное улучшение лучшего решения за шаг, L(t) – счетчик стагнации. Включение в описание состояния характеристик разнообразия и стагнации позволяет учитывать не только текущее качество найденных решений, но и общую динамику эволюционного процесса.
– стандартное отклонение значений целевой функции, D(t) – показатель разнообразия популяции, Δ(t) – относительное улучшение лучшего решения за шаг, L(t) – счетчик стагнации. Включение в описание состояния характеристик разнообразия и стагнации позволяет учитывать не только текущее качество найденных решений, но и общую динамику эволюционного процесса.
Управляющее воздействие формируется агентом глубокого обучения с подкреплением и задается в виде
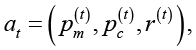
где 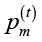 – вероятность мутации,
– вероятность мутации, 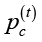 – вероятность кроссовера, r(t) – доля популяции, подлежащая замене новыми особями. Тем самым в контур управления включаются не только параметры генетических операторов, но и механизм поддержания разнообразия популяции. Это отличает предлагаемый подход от схем адаптивного управления, в которых регулировались только вероятности мутации и кроссовера [3; 4]. Близкие постановки ранее рассматривались в работах автора [13; 14], а смежные гибридные подходы к развитию генетических алгоритмов представлены и в других исследованиях [15].
– вероятность кроссовера, r(t) – доля популяции, подлежащая замене новыми особями. Тем самым в контур управления включаются не только параметры генетических операторов, но и механизм поддержания разнообразия популяции. Это отличает предлагаемый подход от схем адаптивного управления, в которых регулировались только вероятности мутации и кроссовера [3; 4]. Близкие постановки ранее рассматривались в работах автора [13; 14], а смежные гибридные подходы к развитию генетических алгоритмов представлены и в других исследованиях [15].
Таблица 1
Параметры вычислительного эксперимента
|
Тестовая функция |
n |
Интервал |
N |
T |
Эпизоды обучения DQN2 |
Эпизоды обучения DQN3R |
Запуски |
|
Сферическая функция |
20 |
[-100; 100] |
50 |
100 |
150 |
200 |
20 |
|
Функция Розенброка |
20 |
[-30; 30] |
50 |
100 |
150 |
200 |
20 |
|
Функция Растригина |
20 |
[-5,12; 5,12] |
50 |
100 |
150 |
200 |
20 |
|
Функция Экли |
20 |
[-32,768; 32,768] |
50 |
100 |
150 |
200 |
20 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Для выбора управляющего воздействия используется нейросетевая аппроксимация функции ценности действий
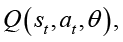
где θ – параметры модели. После выполнения действия at – генетический алгоритм переходит в новое состояние st+1, а агент получает вознаграждение, зависящее от улучшения значения целевой функции и текущего уровня разнообразия популяции. В общем виде функция вознаграждения может быть записана следующим образом
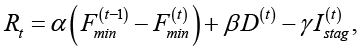
где α, β, γ – весовые коэффициенты, 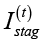 – индикатор стагнации. Такая функция ориентирует агент на достижение двух взаимосвязанных целей: улучшение качества решений и предотвращение деградации популяции.
– индикатор стагнации. Такая функция ориентирует агент на достижение двух взаимосвязанных целей: улучшение качества решений и предотвращение деградации популяции.
Ключевой особенностью метода является механизм контролируемого пополнения популяции. Если выбранное значение r(t) > 0, то часть особей с наихудшими значениями целевой функции заменяется новыми решениями, случайно сгенерированными в допустимой области поиска. Число заменяемых особей определяется выражением
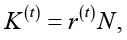
где N – размер популяции. Такая процедура представляет собой частичную реинициализацию популяции и применяется не по фиксированному правилу, а в зависимости от текущего состояния поиска. Это позволяет адаптивно восстанавливать разнообразие популяции при появлении признаков стагнации. Современные исследования подтверждают, что повышение эффективности эволюционного поиска связано с развитием обобщенных подходов к адаптивному управлению параметрами и механизмов поддержания разнообразия популяции [16–18]. Кроме того, существенную роль играет интеграция обучения с подкреплением в структуру метаэвристических алгоритмов [19; 20]. С учетом этих подходов вычислительный эксперимент проводился в два этапа. На первом этапе выполнялось предварительное обучение агента глубокого обучения с подкреплением на серии эпизодов, сформированных на тестовых функциях глобальной оптимизации. На втором этапе проводилась независимая оценка эффективности обученных стратегий без дополнительного обучения в процессе тестового запуска. Сравнение выполнялось для трех вариантов алгоритма: классического генетического алгоритма, алгоритма с предварительно обученным агентом адаптивного управления вероятностями мутации и кроссовера, а также предлагаемого метода, в котором дополнительно регулируется интенсивность контролируемого пополнения популяции новыми особями. Для всех алгоритмов использовались одинаковые значения размера популяции, числа поколений и диапазонов изменения переменных (табл. 1). Оценка результатов выполнялась по среднему финальному лучшему значению целевой функции, стандартному отклонению результатов, лучшему значению за прогон и динамике изменения разнообразия популяции.
Результаты исследования и их обсуждение
Результаты вычислительных экспериментов представлены в табл. 2. Сравнение выполнялось для классического генетического алгоритма, алгоритма с предварительно обученным агентом адаптивного управления вероятностями мутации и кроссовера и предлагаемого метода, в котором дополнительно регулируется интенсивность контролируемого пополнения популяции новыми особями.
Таблица 2
Результаты сравнения алгоритмов на тестовых функциях глобальной оптимизации
|
Тестовая функция |
Алгоритм |
Среднее финальное лучшее значение |
Стандартное отклонение |
|
Сферическая функция |
GA |
4978,49 |
1981,78 |
|
Сферическая функция |
GA+DQN2 |
4165,27 |
1384,89 |
|
Сферическая функция |
GA+DQN3R |
3919,82 |
1177,76 |
|
Функция Розенброка |
GA |
289304,41 |
253314,27 |
|
Функция Розенброка |
GA+DQN2 |
256804,16 |
178957,01 |
|
Функция Розенброка |
GA+DQN3R |
101306,48 |
128227,11 |
|
Функция Растригина |
GA |
58,32 |
14,29 |
|
Функция Растригина |
GA+DQN2 |
57,99 |
7,86 |
|
Функция Растригина |
GA+DQN3R |
56,86 |
13,33 |
|
Функция Экли |
GA |
14,38 |
2,20 |
|
Функция Экли |
GA+DQN2 |
12,52 |
3,48 |
|
Функция Экли |
GA+DQN3R |
14,19 |
2,31 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
Анализ полученных данных показывает, что предварительное обучение агента позволяет повысить эффективность адаптивного управления эволюционным поиском по сравнению с классическим генетическим алгоритмом. Вариант GA+DQN2 обеспечивает улучшение средних результатов на всех рассмотренных тестовых функциях по отношению к базовому генетическому алгоритму. Это свидетельствует о том, что использование заранее обученной стратегии выбора вероятности мутации и вероятности кроссовера является более эффективным, чем применение фиксированных параметров на всем протяжении поиска.
Предлагаемый метод GA+DQN3R, в котором дополнительно осуществляется адаптивное управление пополнением популяции новыми особями, показал наилучшие средние результаты на трех из четырех исследованных функций. Наиболее выраженное преимущество наблюдается на функции Розенброка, где среднее финальное значение целевой функции оказалось существенно ниже, чем у классического генетического алгоритма и у варианта с управлением только вероятностями мутации и кроссовера. Аналогичная тенденция наблюдается на сферической функции и функции Растригина, хотя в последнем случае выигрыш носит более умеренный характер.
На функции Экли лучшим оказался вариант GA+DQN2, тогда как метод GA+DQN3R уступил ему, сохранив при этом преимущество по отношению к классическому генетическому алгоритму. Это позволяет сделать вывод о том, что эффективность механизма контролируемого пополнения популяции зависит от структуры ландшафта целевой функции и характера эволюционной динамики. В отдельных задачах дополнительное вмешательство в состав популяции способствует более эффективному поиску, тогда как в других случаях управление только вероятностями мутации и кроссовера оказывается достаточным.
На рис. 1 представлена средняя динамика сходимости алгоритмов на функции Розенброка. Из графика следует, что предлагаемый метод обеспечивает более быстрое снижение значения целевой функции на основных этапах поиска и сохраняет преимущество вплоть до завершения вычислительного процесса. Это позволяет говорить о более эффективной организации поиска в условиях сложного рельефа целевой поверхности.
На рис. 2 показана средняя динамика разнообразия популяции на функции Розенброка. Видно, что метод GA+DQN3R поддерживает более высокий уровень разнообразия популяции по сравнению с классическим генетическим алгоритмом и вариантом GA+DQN2. При этом среднее значение параметра, отвечающего за пополнение популяции, остается небольшим, что указывает на корректирующий, а не агрессивный характер применения данного механизма. Иными словами, пополнение популяции используется не как постоянный источник случайного обновления, а как средство адаптивного противодействия стагнации поиска.
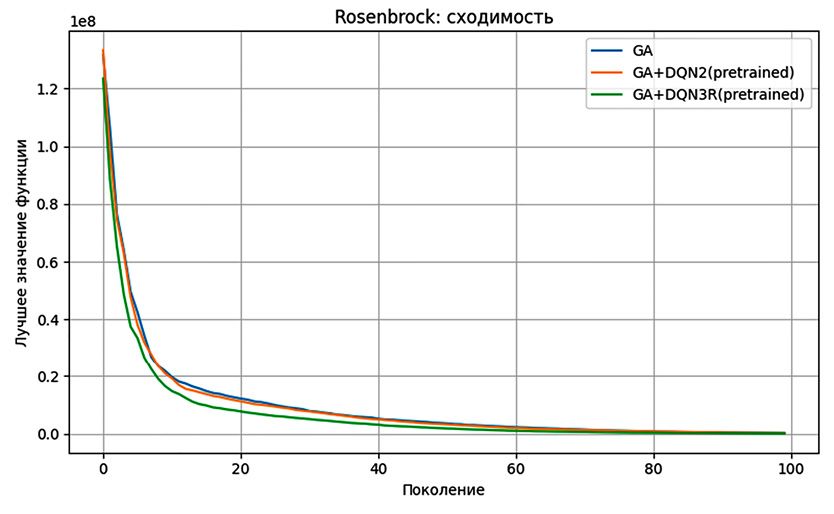
Рис. 1. Средняя динамика сходимости алгоритмов на функции Розенброка Примечание: составлена авторами по результатам данного исследования
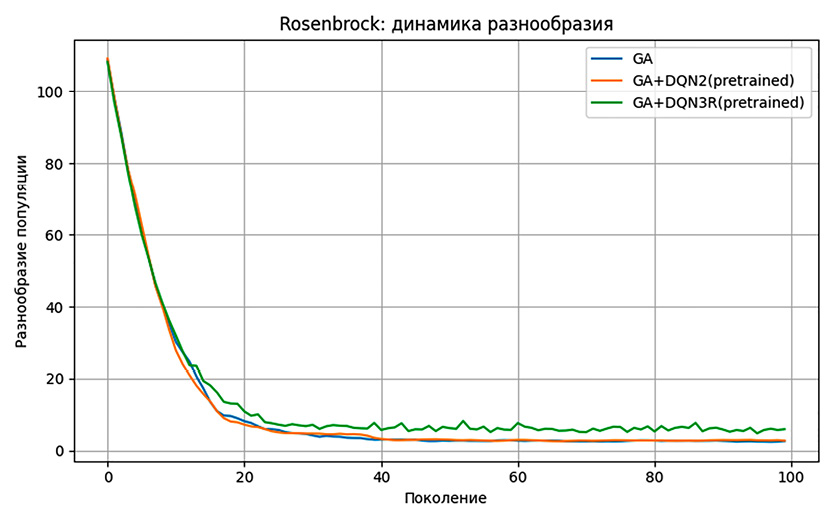
Рис. 2. Средняя динамика разнообразия популяции на функции Розенброка Примечание: составлен авторами по результатам данного исследования
Таким образом, полученные результаты подтверждают, что предварительно обученный агент глубокого обучения с подкреплением может быть использован для эффективного адаптивного управления эволюционным поиском. Дополнительное управление пополнением популяции новыми особями в большинстве рассмотренных случаев приводит к улучшению итоговых результатов и повышению устойчивости поиска, хотя степень его эффективности определяется особенностями решаемой задачи.
Заключение
В работе предложен метод адаптивного управления эволюционным поиском в генетическом алгоритме на основе предварительно обученного агента глубокого обучения с подкреплением. В отличие от схем, в которых регулируются только вероятности мутации и кроссовера, в предлагаемом подходе в контур управления дополнительно включен механизм контролируемого пополнения популяции новыми особями. Это позволяет учитывать не только текущую динамику изменения целевой функции, но и состояние разнообразия популяции.
Результаты вычислительных экспериментов показали, что использование предварительно обученного агента повышает эффективность управления параметрами генетического алгоритма по сравнению с классической схемой с фиксированными параметрами. Предлагаемый метод с управлением пополнением популяции продемонстрировал наилучшие средние результаты на большинстве исследованных тестовых функций. Наиболее выраженный эффект наблюдался на функции Розенброка, где дополнительное поддержание разнообразия популяции обеспечило более устойчивую динамику поиска и более высокое качество итоговых решений.
Вместе с тем результаты на функции Экли показали, что эффективность механизма контролируемого пополнения популяции зависит от структуры целевой поверхности и требует дальнейшей настройки стратегии его активации. Перспективы дальнейшего исследования связаны с совершенствованием механизма принятия решений о пополнении популяции, расширением набора тестовых задач и исследованием применимости разработанного подхода к прикладным задачам численной оптимизации.
Конфликт интересов
Финансирование
Библиографическая ссылка
Привалов К.С., Хорт Д.О. Адаптивное управление генетическим алгоритмом на основе обучения с подкреплением с контролируемым пополнением популяции // Современные наукоемкие технологии. 2026. № 4. С. 123-129;URL: https://top-technologies.ru/ru/article/view?id=40738 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40738