



Введение
В эпоху цифровой трансформации финансового сектора проблема обнаружения мошеннических транзакций приобретает критическое значение для обеспечения экономической безопасности как отдельных кредитных организаций, так и национальной платежной системы в целом. Однако разработка эффективных детектирующих моделей сталкивается с фундаментальным препятствием – экстремальным дисбалансом классов, при котором доля целевых событий (мошеннических операций) составляет доли процента от общего массива данных. Возникает парадоксальная ситуация: наиболее значимые с точки зрения предотвращения ущерба события являются статистически редкими, что делает их труднодоступными для обучения классических алгоритмов. Традиционные методы машинного обучения, ориентированные на минимизацию общей ошибки, закономерно смещаются в сторону предсказания мажоритарного класса, достигая высокой точности за счет игнорирования миноритарного [1]. Как следствие, формально успешная модель может оказаться практически бесполезной, пропуская значительную долю мошеннических операций и создавая тем самым латентные уязвимости в системе безопасности. Особую остроту данной проблеме придает тот факт, что цена ошибок принципиально несимметрична: стоимость пропуска мошеннической транзакции (false negative) на порядки превышает издержки, связанные с ложным срабатыванием (false positive) и последующим расследованием инцидента. Это требует принципиально иного подхода к оценке качества моделей – не на основе агрегированных метрик, а с позиции минимизации реальных экономических потерь.
Для преодоления указанного разрыва в данном исследовании предлагается стоимостно-ориентированная методология, интегрирующая два ключевых компонента: сравнительный анализ методов балансировки классов (ресемплинг, взвешивание, ансамблирование) и последующую оптимизацию порогов принятия решений на основе модели реальных экономических потерь. Такой подход позволяет не только оценить техническую эффективность алгоритмов, но и сформулировать практически значимые рекомендации для систем обнаружения мошенничества, функционирующих в условиях экстремального дисбаланса (доля миноритарного класса менее 1 %), где стандартные предположения классического машинного обучения оказываются нарушенными.
Цель исследования – разработка и верификация стоимостно-ориентированной методологии комплексной оценки методов обработки экстремального классового дисбаланса (ресемплирование, взвешивание, ансамбли, градиентное усиление) с оптимизацией порогов принятия решений на основе реальных экономических потерь для задач обнаружения финансового мошенничества.
Материалы и методы исследования
Предметом исследования является проблема классификации на экстремально несбалансированных данных в задачах машинного обучения, применяемых в финансовых системах, а также связанные с ней риски и угрозы экономической и информационной безопасности. Для достижения поставленной цели в ходе исследования были использованы методы анализа и обобщения научных исследований в области машинного обучения, экспериментальное моделирование и сравнительный анализ.
Эксперимент проводился на наборе данных, который имеет устоявшееся англоязычное наименование Credit Card Fraud Detection (в переводе с английского языка обозначает «Выявление случаев мошенничества с кредитными картами») и доступен на международной платформе Kaggle по анализу данных и машинному обучению [2]. Этот набор данных содержит 284 807 транзакций, из которых только 492 (0,17 %) являются мошенническими. Выбор данного набора данных обусловлен его широким использованием в научных исследованиях и разработках в области обнаружения финансового мошенничества. Наличие экстремального дисбаланса классов делает его показательным примером для анализа поведения классификаторов в условиях, максимально приближенных к реальным сценариям функционирования финансовых систем.
Для решения проблемы дисбаланса классов рассмотрены методы формирования выборки: случайное уменьшение выборки (с коэффициентом отбора 0,5), случайное увеличение выборки и метод синтетического дополнения миноритарного класса SMOTE (с пятью ближайшими соседями и начальным значением генератора 42) [3]. Среди алгоритмических методов применено взвешивание классов с параметром «сбалансированный». Из ансамблевых методов использован EasyEnsemble (с десятью базовыми классификаторами – логистическими регрессиями) [4]. Дополнительно протестированы современные алгоритмы: XGBoost [5] (с количеством базовых оценок 300, максимальной глубиной деревьев 6, шагом обучения 0,1 и масштабированием веса положительного класса по принципу «сбалансированный»), LightGBM [6] (с 300 базовыми оценками), случайный лес (с 200 деревьями и взвешиванием классов по принципу «сбалансированный»), а также глубокая нейронная сеть (архитектура 64-32-1, функция активации ReLU, ранняя остановка обучения после 10 эпох без улучшения). В качестве базового классификатора использована логистическая регрессия (коэффициент регуляризации 1,0, регуляризация L2, метод оптимизации liblinear, начальное значение генератора 42). Для воспроизводимости результатов применена стратифицированная 5-кратная кросс-валидация (с перемешиванием данных и начальным значением генератора 42); методы сэмплирования и балансировки затрагивали исключительно обучающую выборку. Исходный код находится в Google Colab в открытом доступе для всех желающих по адресу: [https://colab.research.google.com/drive/1NWXSvNJ8pqs2UF14_NYIjrgzjJDYsWny#scrollTo=rfZI_F5mK7r0].
Оценка качества моделей выполнена с использованием метрик F1-меры (гармоническое среднее точности и полноты), площади под ROC-кривой (рабочая характеристика приемника), площади под кривой точность-полнота, а также точности, полноты, анализа матриц ошибок и кривых точность-полнота [7, 8]. Под агрегированными метриками здесь понимаются интегральные скалярные показатели, такие как F1-мера, площадь под ROC-кривой и площадь под кривой точность-полнота, которые обобщают качество модели и используются для сравнения методов. Для количественной оценки экономической эффективности введена стоимостная модель:
Стоимость_ошибки = FN × 1000 + FP × 10,
где FN (false negative) – количество пропущенных мошеннических операций (ложноотрицательные решения), а FP (false positive) – количество ложных срабатываний (ложноположительные решения), при этом стоимость пропуска мошенничества в 100 раз превышает стоимость ложного срабатывания, что соответствует отраслевым оценкам.
Результаты исследования и их обсуждение
Растущая значимость задач обнаружения финансового мошенничества в условиях цифровой трансформации экономики порождает множество публикаций в научной литературе, посвященных как самим методам выявления аномальных транзакций, так и сопутствующей проблеме классового дисбаланса. Как отмечается в статье [9], интерес исследователей к данной проблематике неуклонно растет: количество публикаций, индексируемых в международных научных базах по тематике кредитного мошенничества и машинного обучения, увеличивалось ежегодно на протяжении последних пяти лет, достигнув пика в 2024 г., что отражает как остроту проблемы для финансового сектора, так и поиск новых технических решений. Мировые потери от мошенничества с платежными картами превышают несколько десятков миллиардов долларов, при этом более 70 % мошеннических транзакций приходятся на цифровые каналы. В таких условиях традиционные системы демонстрируют свою несостоятельность, уступая место алгоритмам машинного обучения. Однако, как подчеркивается в современной научной литературе, ключевой проблемой остается экстремальный дисбаланс классов: доля мошеннических операций в реальных наборах данных составляет от 0,1 до 0,17 % [10, 11]. Это приводит к тому, что модели, оптимизирующие общую точность, оказываются смещенными в сторону мажоритарного класса и неспособны выявлять редкие, но критически значимые события. Более того, исследователи обращают внимание на то, что использование традиционных агрегированных метрик, таких как точность или F1-мера, может вводить в заблуждение при оценке качества моделей в условиях дисбаланса. В исследовании [10] отмечается проблема высокого уровня ложных срабатываний, которая приводит к нерациональным временным и финансовым затратам при расследовании инцидентов службами мониторинга мошенничества. Это не только снижает операционную эффективность банков, но и подрывает доверие к автоматизированным системам безопасности.
Дополнительную сложность создает высокая стоимость разметки данных и проблема «холодного старта» при отсутствии или недостаточности размеченных примеров мошеннических операций. В исследовании [12], посвященном проблемам старта обучения с нулевой разметкой и высоким издержкам, доказывается, что традиционные подходы часто оказываются неэффективны в условиях, когда размеченные данные о мошенничестве отсутствуют или крайне ограничены, что требует разработки адаптивных гибридных стратегий, объединяющих обучение без учителя, полуавтоматическое обучение и активное обучение с учетом бюджетных ограничений.
Также критически важным аспектом, поднимаемым в современной научной литературе, является не только техническая эффективность моделей, но и их экономическая состоятельность. Исследователи все чаще обращаются к подходам с учетом ошибок, в рамках которых выбор модели и настройка порогов классификации производятся не на основе абстрактных метрик, а исходя из реального соотношения издержек от ложных срабатываний и пропуска мошеннических операций [9, 13, 14].
В данном исследовании рассматриваются различные подходы к решению проблемы дисбаланса классов и проводится их сравнительный анализ на реальном наборе данных финансовых транзакций. Классические подходы включают методы передискретизации [15], алгоритмическое взвешивание классов и ансамблевые методы [16, 17]. Современные исследования демонстрируют эффективность метода градиентного усиления для задач обнаружения мошенничества [18], однако комплексное сравнение традиционных и современных методов с учетом стоимостных моделей остается недостаточно изученным. В статье [19] автор акцентирует внимание, что существующие методы с трудом справляются с решением проблемы дисбаланса классов и часто не позволяют получить качественные метки, что приводит к высокому уровню ложноположительных результатов (законные случаи отмечаются как мошеннические), что приводит к потере времени и финансовых ресурсов при расследовании случаев, которые не являются мошенническими. Как мы видим, это является следствием неверно настроенной модели.
С позиции экономической и информационной безопасности экстремальный дисбаланс классов следует рассматривать не только как техническую проблему машинного обучения, но и как самостоятельный источник системных угроз [20]. Использование моделей, некорректно работающих с редкими, но критически значимыми событиями, приводит к искажению процессов принятия управленческих решений и формированию ложного ощущения надежности автоматизированных систем.
В финансовом секторе подобные искажения способны привести к существенным экономическим потерям [21, 22]. Формально высокие показатели точности и F1-меры могут служить основанием для внедрения модели в промышленную эксплуатацию, однако фактическая неспособность выявлять значительную долю мошеннических операций формирует латентную уязвимость системы [23]. Такая уязвимость может быть целенаправленно использована злоумышленниками, адаптирующими свои действия под поведение алгоритмов обнаружения аномалий [24, 25]. Дополнительную угрозу представляет эффект так называемой «метрической слепоты», при котором разработчики и аналитики ориентируются на агрегированные показатели качества, не отражающие реальную эффективность модели на миноритарном классе. В условиях экстремального дисбаланса классов это приводит к тому, что система демонстрирует высокие формальные показатели при фактической неспособности выполнять свою ключевую функцию – предотвращение ущерба [26]. Следовательно, проблема дисбаланса классов выходит за рамки чисто вычислительной задачи и затрагивает вопросы устойчивости, надежности и безопасности интеллектуальных информационных систем, применяемых в критически важных областях [27, 28].
Выбор данного набора данных обусловлен его широким использованием в научных исследованиях и разработках в области обнаружения финансового мошенничества. Наличие экстремального дисбаланса классов делает его показательным примером для анализа поведения классификаторов в условиях, максимально приближенных к реальным сценариям функционирования финансовых систем.
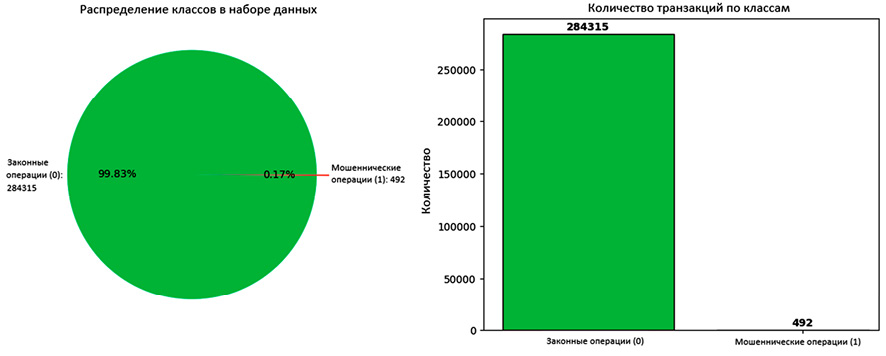
Рис. 1. Распределение классов в наборе данных Credit Card Fraud Detection Примечание: составлен авторами по результатам данного исследования
Таблица 1
Сравнительный анализ методов обработки несбалансированных данных
|
Метод |
F1-мера |
Площадь под кривой точность- полнота |
Полнота |
Точность |
Площадь под ROC-кривой |
Стои-мость ошибки |
Ложные срабатывания |
Пропу-щенные операции |
|
XGBoost |
0,870 |
0,863 |
0,829 |
0,916 |
0,981 |
16876 |
7,6 |
16,8 |
|
Случайный лес |
0,858 |
0,850 |
0,787 |
0,944 |
0,952 |
21046 |
4,6 |
21,0 |
|
EasyEnsemble |
0,086 |
0,754 |
0,913 |
0,045 |
0,980 |
27694 |
1909 |
8,6 |
|
Взвешенная логистическая регрессия |
0,121 |
0,729 |
0,911 |
0,065 |
0,980 |
21768 |
1297 |
8,8 |
|
SMOTE |
0,161 |
0,729 |
0,882 |
0,088 |
0,970 |
20592 |
899 |
11,6 |
|
Случайное увеличение выборки |
0,109 |
0,702 |
0,898 |
0,058 |
0,971 |
24988 |
1499 |
10,0 |
|
Случайное уменьшение выборки |
0,300 |
0,687 |
0,815 |
0,185 |
0,939 |
21920 |
372 |
18,2 |
|
Базовая модель |
0,661 |
0,596 |
0,581 |
0,781 |
0,925 |
41366 |
16,6 |
41,2 |
|
Глубокая нейронная сеть |
0,215 |
0,167 |
0,171 |
0,415 |
0,638 |
81660 |
6,0 |
81,6 |
|
LightGBM |
0,103 |
0,048 |
0,862 |
0,056 |
0,899 |
50454 |
3685 |
13,6 |
Примечание: составлена авторами на основе полученных данных в ходе исследования
Набор данных (рис. 1) характеризуется экстремальным дисбалансом: доля мошеннических операций составляет лишь 0,17 %, что создает серьезные трудности для обучения классификаторов.
Результаты эксперимента (табл. 1) показывают ключевую проблему выбора метрик. Базовая модель показывает наивысшее значение F1-меры (0,661), однако имеет относительно низкую полноту (Полнота = 0,581), что означает пропуск 41,9 % мошеннических операций. Методы обработки дисбаланса значительно улучшают полноту (до 0,8784), но за счет снижения точности, что приводит к уменьшению F1-меры. Статистическая значимость различий по метрикам качества подтверждена результатами применения парного t-критерия (p < 0,05 при сравнении с базовой моделью логистической регрессии). Среднеквадратические отклонения по пяти блокам кросс-валидации: для XGBoost площадь под кривой точность-полнота составляет 0,863±0,021, а F1-мера составляет 0,870±0,015.
На рис. 2 представлено визуальное сравнение ключевых метрик. Алгоритмы XGBoost и случайный лес (RandomForest) превосходят остальные по большинству показателей. Несмотря на низкие значения F1-меры у методов EasyEnsemble и взвешенной логистической регрессии (Weighted_LR), они обеспечивают максимальную полноту, что критически важно для задач обнаружения мошенничества. Остальные методы (SMOTE, LightGBM, случайное увеличение выборки (RandomOver), случайное уменьшение выборки (RandomUnder), глубокая нейронная сеть (DNN), базовая модель (Baseline LR)) показывают более низкие результаты.
Кривые точность-полнота (рис. 3) наглядно демонстрируют компромисс между точностью и полнотой. Алгоритм XGBoost обеспечивает наибольшую площадь под кривой (0,862), случайный лес (RandomForest) имеет значение 0,850. Взвешенная логистическая регрессия (Weighted_LR) и SMOTE показывают сопоставимые результаты (0,730 и 0,708 соответственно), тогда как базовая модель (Baseline LR) значительно уступает (0,572). Глубокая нейронная сеть (DNN) продемонстрировала наихудший результат (0,145), что связано с недостаточным объемом данных для эффективного обучения сложной архитектуры в условиях экстремального дисбаланса.
Анализ матриц ошибок (рис. 4) подтверждает полученные выводы. Алгоритм XGBoost допускает в среднем 7,6 ложноположительных и 16,8 ложноотрицательных предсказаний на блок кросс-валидации. Случайный лес обеспечивает минимальное число ложных срабатываний (4,6) при 21 пропущенном мошенничестве. Методы EasyEnsemble и взвешенной логистической регрессии увеличивают число ложных срабатываний до 1300–1900, но сокращают пропуски до 8–9 случаев.
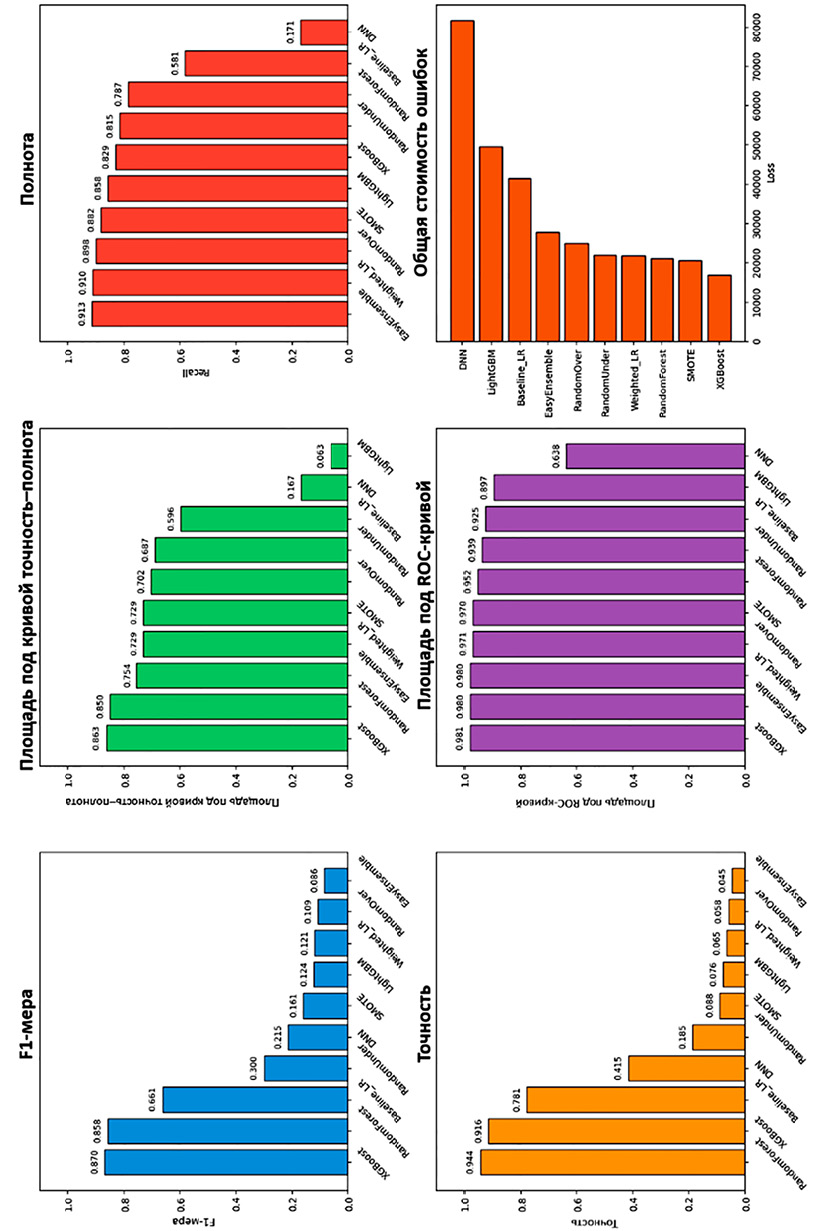
Рис. 2. Сравнение метрик качества для методов обработки несбалансированных данных Примечание: составлен авторами по результатам данного исследования
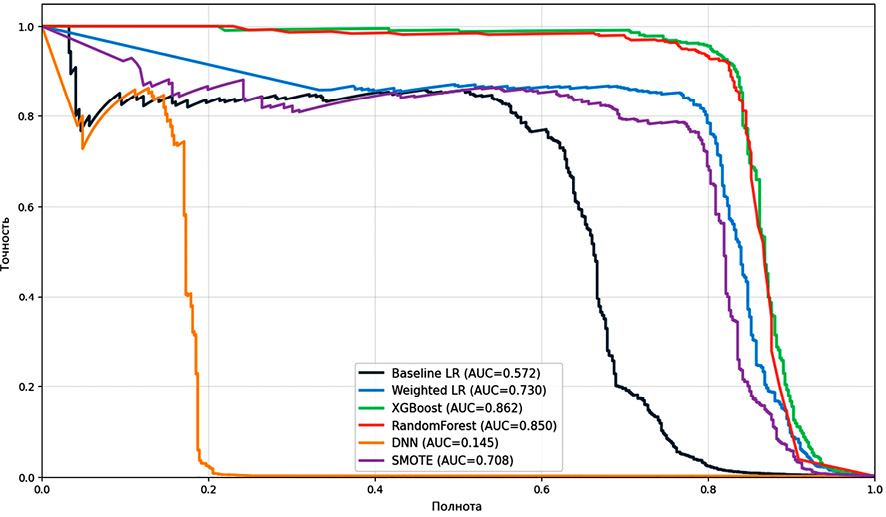
Рис. 3. Кривые точность-полнота для различных методов обработки данных Примечание: составлен авторами по результатам данного исследования
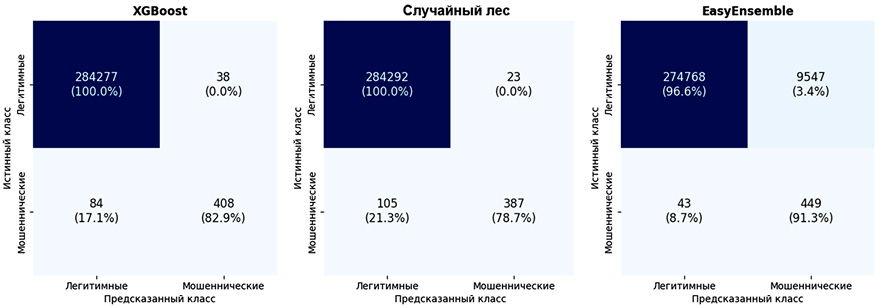
Рис. 4. Матрицы ошибок для трех лучших методов Примечание: составлен авторами по результатам данного исследования
Полученные результаты требуют нетривиальной интерпретации. Базовая модель достигает формально высокого F1-мера (0,661) за счет относительно высокой точности (0,781), но ценой пропуска 41,9 % мошеннических операций (Полнота = 0,581). В контексте обнаружения мошенничества такая модель неприемлема, так как более 40 % случаев останутся незамеченными. Методы обработки дисбаланса радикально меняют баланс метрик: они увеличивают полноту до 87–91 %, обнаруживая практически все случаи мошенничества, но при этом снижают точность до 4–8 %. Это означает, что на каждые 100 помеченных как подозрительные операций лишь 4–8 действительно являются мошенническими, что приводит к высоким затратам на расследование ложных срабатываний.
Для оценки надежности полученных различий применен парный t-критерий для метрик F1-меры и стоимости ошибок между базовой моделью и каждым из рассматриваемых методов. Результаты, представленные в табл. 2, подтверждают, что большинство методов демонстрируют статистически значимое улучшение (p < 0,05) как по F1-мере, так и по экономическим потерям. Исключение составила глубокая нейронная сеть: различия по F1-мере оказались на грани значимости (p = 0,0543), а по стоимости – статистически незначимы (p = 0,0590). Метод LightGBM, несмотря на высокую полноту, не показал значимого снижения затрат по сравнению с базовой моделью (p = 0,5624), что объясняется чрезмерно большим числом ложных срабатываний (в среднем 3685 ложных срабатываний на блок кросс-валидации). Эти наблюдения подчеркивают важность комплексной оценки, учитывающей не только технические метрики, но и практические последствия ошибок классификации.
Отрицательные значения t-статистики указывают на то, что среднее значение метрики у метода ниже, чем у базовой модели (например, случайный лес и XGBoost имеют более низкую F1-меру, но значительно меньшую стоимость ошибок).
Экономический анализ (рис. 5) позволяет ранжировать методы по реальным потерям. XGBoost обеспечивает минимальные потери 16 876 у. е. – на 59 % ниже, чем базовая модель. SMOTE – 20 592 у. е. (экономия 50 %), случайный лес – 21 046 у. е. (экономия 49 %). Глубокая нейронная сеть показывает наихудший результат – 81 660 у. е. Статистическая значимость экономических потерь подтверждена результатами применения парного t-критерия Стьюдента: сравнение XGBoost с базовой моделью (t = 5,75; p = 0,0045), среднее значение 16 876±2 340 у. е. по пяти блокам кросс-валидации.
Таблица 2
Результаты парного t-критерия (сравнение с базовой моделью логистической регрессии)
|
Метод |
t-статистика (F1) |
p-значение (F1) |
t-статистика (Стоимость_ошибки) |
p-значение (Стоимость_ошибки) |
|
Взвешенная логистическая регрессия |
21,1110 |
< 0,0001 |
4,5884 |
0,0101 |
|
Случайное уменьшение выборки |
8,9091 |
0,0009 |
5,7937 |
0,0044 |
|
Случайное увеличение выборки |
15,6046 |
0,0001 |
3,1552 |
0,0343 |
|
SMOTE |
17,3673 |
0,0001 |
5,1218 |
0,0069 |
|
EasyEnsemble |
23,1350 |
< 0,0001 |
3,2072 |
0,0327 |
|
Случайный лес |
-6,7404 |
0,0025 |
4,6909 |
0,0094 |
|
XGBoost |
-6,1806 |
0,0035 |
5,7475 |
0,0045 |
|
LightGBM |
7,4433 |
0,0017 |
-0,6308 |
0,5624 |
|
Глубокая нейронная сеть |
2,6970 |
0,0543 |
-2,6168 |
0,0590 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
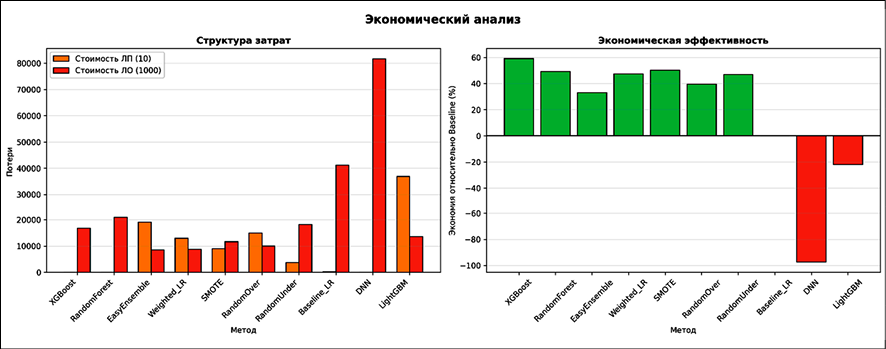
Рис. 5. Экономический анализ: структура затрат и экономия относительно Baseline Примечание: составлен авторами по результатам данного исследования
На столбчатой диаграмме для каждого метода представлена стоимость ложных срабатываний (ЛП), стоимость пропущенных мошеннических операций (ЛО) и итоговая экономическая эффективность. XGBoost обеспечивает наибольшую экономию (60 % снижения потерь), остальные методы (случайный лес (RandomForest), EasyEnsemble, взвешенная логистическая регрессия (Weighted-LR), SMOTE, случайное увеличение выборки (RandomOver), случайное уменьшение выборки (RandomUnder)) показывают экономию в диапазоне от 35 до 55 %, тогда как базовая модель (Baseline-LR), LightGBM и глубокая нейронная сеть (DNN) показывают низкую или отрицательную эффективность.
Оптимизация порога принятия решения для алгоритма XGBoost показала, что оптимальный порог составляет 0,010. При стандартном пороге 0,5 суммарная стоимость ошибок на пяти блоках кросс-валидации равнялась 84 380 у. е. (средняя стоимость 16 876 у. е. на блок). После снижения порога до 0,010 суммарная стоимость уменьшилась до 71 030 у. е., что соответствует экономии 16 %. В пересчете на один блок средняя стоимость снизилась с 16 876 до 14 206 у. е. Таким образом, даже небольшая корректировка порога позволяет дополнительно повысить экономическую эффективность модели за счет более удачного баланса между пропущенными мошенническими операциями и ложными срабатываниями.
Следует отметить, что полученные результаты справедливы для статического среза данных. В реальных условиях мошеннические схемы постоянно эволюционируют, что требует адаптивного переобучения моделей. Для промышленной эксплуатации систем с полнотой 91 % при точности 4–6 % необходимо учитывать операционные ограничения: количество ложных срабатываний не должно превышать пропускную способность подразделений по противодействию мошенничеству. В таких случаях целесообразно использовать каскадные архитектуры, где модели с высокой полнотой работают на этапе приоритизации, а модели с высокой точностью – на этапе автоматической блокировки.
Проведенный анализ выполнен на статическом наборе данных без учета концептуального дрейфа, характерного для реальных систем обнаружения мошенничества. Достигнутое значение площади под кривой точность-полнота, равное 0,863 для алгоритма XGBoost, согласуется с известными в литературе результатами для метода градиентного усиления на данном наборе данных, что подтверждает надежность полученных выводов. Стоимостная модель использует условные коэффициенты (стоимость пропуска мошеннической операции 1000 у. е., стоимость ложного срабатывания 10 у. е.), требующие калибровки под конкретные банковские системы. Обобщаемость результатов ограничена одним публичным набором данных.
Ключевой вывод эксперимента заключается в том, что при экстремальном дисбалансе метрика F1-мера, являясь гармоническим средним точности и полноты, может вводить в заблуждение, создавая иллюзию эффективности модели, которая на практике пропускает значительную долю целевых событий. Более адекватными метриками в таких условиях являются площадь под ROC-кривой и особенно площадь под кривой точность-полнота, которые корректно отражают качество работы модели на миноритарном классе.
Следовательно, в условиях экстремального дисбаланса (менее 0,2 % миноритарного класса) и заданного соотношения издержек (стоимость пропуска мошеннической операции значительно превышает стоимость ложного срабатывания) оптимальным является не метод, максимизирующий F1-меру, а алгоритм XGBoost, допускающий большее число ложных срабатываний, но обеспечивающий минимальные совокупные потери благодаря возможности гибкой настройки порога решения. Предложенная методология позволяет снизить экономические потери на 59 % по сравнению с метрико-ориентированным подходом.
Заключение
Проведенное исследование демонстрирует, что выбор метода обработки несбалансированных данных должен основываться не только на агрегированных метриках, но и на анализе компромисса между точностью и полнотой с учетом специфики решаемой задачи и стоимости ошибок. Для задач, где стоимость ложноположительных ошибок низка, а ложноотрицательных – высока, предпочтительны методы, максимизирующие полноту: EasyEnsemble, или взвешенная логистическая регрессия (обнаружение 91 % целевых событий). В случаях, когда ложные срабатывания обходятся дорого, предпочтительны алгоритмы XGBoost или случайный лес, обеспечивающие высокую точность (92–94 %) при приемлемой полноте (79–83 %). Для практического внедрения рекомендуется регулярное переобучение моделей с учетом концептуального дрейфа и настройка порогов принятия решений под текущие операционные ограничения. XGBoost признан наиболее эффективным методом по комплексу показателей, обеспечивая снижение экономических потерь на 59 % относительно базовой модели.
Конфликт интересов
Финансирование
Библиографическая ссылка
Измайлов Т.Р., Зарипова Р.С. ИССЛЕДОВАНИЕ ЭФФЕКТИВНОСТИ МЕТОДОВ БАЛАНСИРОВКИ КЛАССОВ В ЗАДАЧАХ ОБНАРУЖЕНИЯ ФИНАНСОВОГО МОШЕННИЧЕСТВА: СТОИМОСТНО-ОРИЕНТИРОВАННЫЙ ПОДХОД И ОПТИМИЗАЦИЯ ПОРОГОВ ПРИНЯТИЯ РЕШЕНИЙ // Современные наукоемкие технологии. 2026. № 4. С. 66-75;URL: https://top-technologies.ru/ru/article/view?id=40730 (дата обращения: 25.06.2026).
DOI: https://doi.org/10.17513/snt.40730