



Введение
Стремительное развитие технологий искусственного интеллекта (ИИ) инициирует пересмотр традиционных подходов к проектированию архитектуры вычислительных систем. Классическая централизованная модель, предполагающая обработку всех запросов на мощностях удаленных дата-центров (серверов), в текущее время показывает все больше существенных ограничений при масштабировании [1]. Расширение дата-центров требует дорожающих компьютерных комплектующих, «силовое масштабирование» становится экономически и физически нецелесообразно для многих организаций, в том числе образовательных [2]. Тем не менее конкуренция в области ИИ возрастает, все больше предприятий и вузов планируют внедрение собственных интеллектуальных систем и сервисов. Это в том числе связано с повышающимися сегодня требованиями к безопасности и предотвращению утечки данных. Технически ключевыми проблемами централизованных архитектур являются непредсказуемая сетевая задержка, высокая стоимость передачи больших объемов данных и критическая зависимость от доступности и скорости магистральных каналов связи, что отрицательно влияет на надежность вычислительных систем и может приводить к их неприменимости. Особенно остро данные проблемы проявляются в интеллектуальных системах, где требуется принятие решений в режиме реального времени [3].
В качестве перспективного решения автором рассматривается переход к организации глобально распределенной обработки потоков данных, основанной на концепции туманных вычислений и федеративного машинного обучения [4–6]. Суть данного подхода заключается в переносе части вычислительной нагрузки из центрального облака на промежуточные узлы, расположенные на границе сети, и непосредственно на клиентские устройства, что могло бы обеспечить масштабирование архитектуры путем оптимизации, а не расширения вычислительных характеристик оборудования.
Цель исследования – экспериментальное исследование надежности интеллектуальных систем с применением методов организации глобально распределенной адаптивной обработки потоков данных путем оценки основных показателей обеспечения надежности информационных систем (SRE, Site Reliability Engineering) – задержки адаптивной обработки потоков данных, насыщения и степени разгрузки узлов.
Материалы и методы исследования
Для проведения исследования была спроектирована и программно реализована архитектура распределенной интеллектуальной системы, структурно состоящая из трех функциональных уровней (рис. 1). Верхний уровень иерархии занимает облачный сервер, выполняющий роль глобального координатора и агрегатора. Его основной задачей является поддержание актуальной версии глобальной интеллектуальной модели, которая формируется путем объединения обновлений, поступающих от нижестоящих узлов. В модели облачный сервер реализует алгоритмы федеративного машинного обучения, принимая дифференциальные изменения весов моделей и рассчитывая метрику глобального качества.
Средний уровень образуют туманные («вузовские») узлы, которые располагаются в непосредственной близости к группам пользователей, например, в локальной сети организации или образовательного учреждения, но могут располагаться географически далеко друг от друга. Эти узлы берут на себя основную нагрузку по выполнению инференса – обработки запросов к интеллектуальной модели. Ключевой особенностью туманного узла в разработанной архитектуре является его способность к автономной работе. Узел хранит локальную копию модели и периодически, в асинхронном режиме, синхронизирует ее состояние с облачным сервером. Такой подход позволяет обслуживать запросы пользователей даже при временной недоступности глобальной сети [7, 8].
Туманные узлы включают в себя модель библиотек учебных заведений с коллекцией объемом 1000 документов (~6 ГБ размер файлов .pdf и .docx, размер чистого текста ~763 МБ, ~1,6×108 токенов). Данный текстовый корпус моделирует реальный поток данных для последующей обработки и дообучения интеллектуальной большой языковой модели A-vibe [9], которая также установлена на туманных узлах.
Нижний уровень представлен клиентскими (периферийными) устройствами, под которыми понимаются персональные компьютеры или мобильные терминалы конечных пользователей. В предложенной архитектуре эти устройства не являются пассивными потребителями контента, а участвуют в вычислительном процессе. При высокой загрузке туманного узла часть задач по предварительной обработке данных, например токенизация или извлечение признаков из документов, передается на клиентские устройства. Это позволяет реализовать методы динамической разгрузки (оффлоадинга), который снижает нагрузку на компоненты туманного узла [10, 11].
Научная новизна исследования заключается в экспериментальном выявлении нелинейной зависимости между насыщением туманного узла и интенсивностью разгрузки вычислений, подтверждающей, что адаптивные методы динамической разгрузки могут переводить интеллектуальные системы в квазистационарное состояние со стабилизацией времени отклика при пиковых нагрузках; в определении границ эффективности гибридной обработки данных, обеспечивающих снижение нагрузки на вычислительные узлы за счет динамического перераспределения задач предварительной обработки в исследуемой архитектуре.
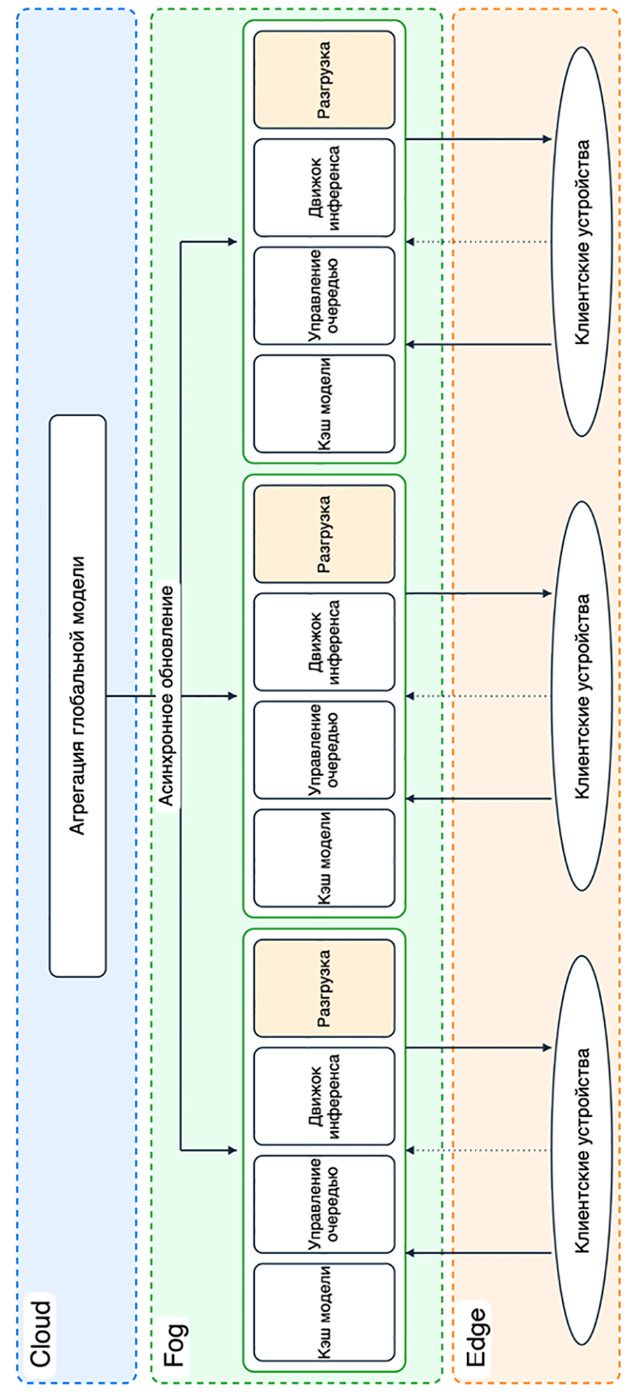
Рис. 1. Предлагаемая архитектура интеллектуальных систем Примечание: составлен автором по результатам данного исследования
В общем виде архитектура и математическая модель системы основаны на концепции многокритериальной оптимизации качества обработки потоковых данных [12]. Для оперативного управления надежностью выполняется задача максимизации вероятности корректного ответа Pok:
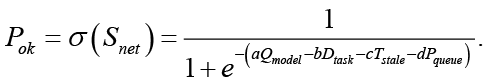 (*)
(*)
Здесь Qmodel отражает качество модели (аналог ФA), Tstale – показатель устаревания данных (Δ), Pqueue характеризует нагрузку и задержки (ФP), а Dtask – ресурсоемкость задачи (ФR). Коэффициенты a, b, c, d задают чувствительность системы к различным видам возмущений и служат эмпирическими аналогами весов w.
Характеристики экспериментального стенда
|
Параметр / Характеристика |
Облачный сервер |
Туманный узел |
Периферийное устройство |
|
Процессор (CPU/vCPU) |
Intel Core i9-12900K (16 ядер / 24 потока) |
Intel Core i7-11700 (8 ядер / 16 потоков) |
Intel Core i5-10400 (6 ядер / 12 потоков) |
|
Оперативная память (RAM) |
64 ГБ |
32 ГБ |
16 ГБ |
|
Графическая подсистема (GPU) |
NVIDIA GeForce RTX 3090 (24 ГБ vRAM) |
NVIDIA GeForce RTX 3060 (12 ГБ vRAM) |
Intel UHD Graphics 630 (Интегрированная) |
|
Накопитель (SSD) |
1 ТБ |
512 ГБ |
256 ГБ |
|
Операционная система (OS) |
Ubuntu Server 24.04 LTS |
Ubuntu Server 24.04 LTS / k3s |
Ubuntu Desktop 24.04 LTS |
Примечание: составлена автором на основе технической конфигурации экспериментального стенда.
Экспериментальный стенд был развернут в среде оркестрации контейнеров Kubernetes (дистрибутив k3s), что позволило максимально приблизить условия тестирования к реальной эксплуатационной среде (таблица). Для генерации синтетической нагрузки использовался инструмент k6, позволяющий моделировать сложное поведение множества виртуальных пользователей. Система мониторинга была построена на базе стека Prometheus и Grafana, обеспечивая сбор метрик с дискретностью в одну секунду [13]. В ходе экспериментов фиксировались стандартные метрики производительности SRE.
Результаты исследования и их обсуждение
Механизм оффлоадинга реализован на Python с использованием NumPy (рис. 2); класс ReliabilityManager (метод calculate_p_ok) напрямую реализует модель (*), по телеметрии узла (очередь Pqueue, рассинхронизация Tstale) вычисляет Pok для каждого запроса и при падении ниже порога надежности (threshold = 0.85) переключает обработку на оффлоадинг задач на клиентские устройства [14, 15].
В рамках нагрузочного тестирования были заданы несколько сценариев эксперимента: базовый сценарий для калибровки и получения эталонных показателей, линейный рост нагрузки для выявления предельной пропускной способности и точки деградации качества, а также стресс-сценарий всплеска нагрузки и отказ связи с облачным сегментом, представляющие основной интерес для анализа надежности.
В ходе эксперимента моделировался резкий восьмикратный рост входящей нагрузки (с 10 до 80 запросов в секунду), имитирующий начало массовой активности пользователей. На графике на рис. 3 зафиксирован момент нарастания пиковой нагрузки (ось Y) в интервале 10–35 тыс. итераций (ось X). Длина очереди ожидающих задач обработки продемонстрировала экспоненциальный рост, достигнув абсолютного максимума в 85 запросов в районе 37 тыс. итераций. Согласно (*) (параметр Pqueue), это состояние соответствует критическому риску отказа в обслуживании.
Однако реализованная на экспериментальном стенде интеллектуальная система продемонстрировала корректную работу механизма адаптивной защиты.

Рис. 2. Программная реализация механизма динамической разгрузки Примечание: составлен автором по результатам данного исследования
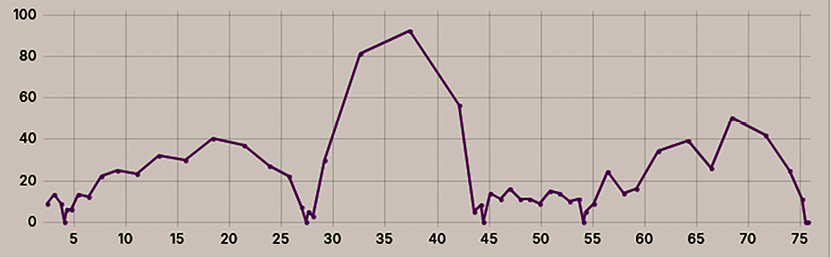
Рис. 3. Насыщение узлов туманного уровня Примечание: составлен автором по результатам данного исследования
Сопоставление данных с графиком (рис. 4) показывает, что в момент роста очереди запросов выше порогового значения заранее произошла активация динамической разгрузки. Доля вычислительных задач предварительной обработки данных (токенизация, векторизация), передаваемых на периферийные устройства, резко возросла с фоновых 30–35 до 78 %.
Эффект от перераспределения нагрузки наблюдается мгновенно: начиная с 40-тысячной итерации длина очереди на туманном узле принудительно снижается и стабилизируется в диапазоне 5–20 запросов, несмотря на продолжающийся поток входящих запросов.
Анализ времени задержки узлов туманного уровня на рис. 5 подтверждает эффективность выбранной стратегии.
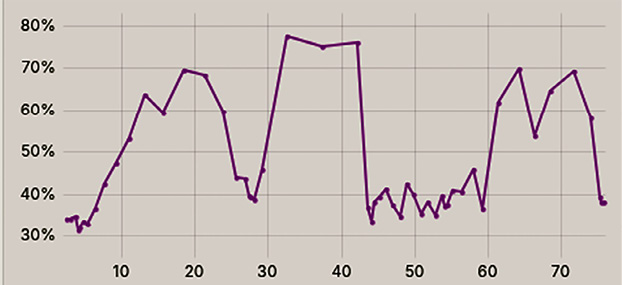
Рис. 4. Степень разгрузки узлов туманного уровня Примечание: составлен автором по результатам данного исследования
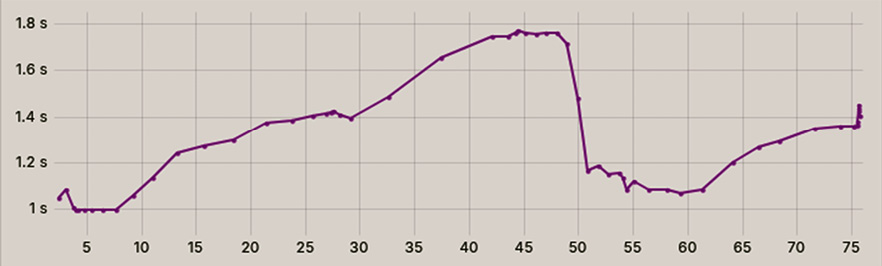
Рис. 5. Средняя задержка узлов туманного уровня Примечание: составлен автором по результатам данного исследования
В фазе насыщения 95-й перцентиль задержки закономерно вырос с 1,0 до 1,78 с. Однако благодаря массовому сбросу задач на клиентские устройства система избежала неконтролируемого роста задержек. После стабилизации очереди задержка вернулась к значению 1,1–1,2 с, что является приемлемым показателем для интерактивных интеллектуальных систем.
Также в эксперименте исследовалась устойчивость системы к потере связи с облачным сервером с 60-тысячной итерации. При потере связи с облаком в традиционных системах сервис останавливается (Pok → 0), в предлагаемой же архитектуре Tstale растет, вызывая мягкую деградацию по (*). Точность снижается плавно и постепенно, сервис работает автономно, сохраняя доступность.
Заключение
В работе выполнено экспериментальное исследование надежности распределенных интеллектуальных систем с трехуровневой архитектурой и адаптивной разгрузкой вычислений на клиентские устройства при сценариях пиковых нагрузок и потери связи с облачным сегментом. Показано, что при восьмикратном росте интенсивности запросов (с 10 до 80 запросов/с) применение методов организации глобально распределенной адаптивной обработки потоков данных, увеличивающих долю внешних вычислений с 30–35 до 78 %, переводит систему в устойчивое квазистационарное состояние: очередь задач стабилизируется в диапазоне 5–20 запросов, а время отклика удерживается на уровне 1,1–1,2 с (после кратковременного роста p95-задержки до 1,78 с). Экспериментально подтвержден эффект «мягкой деградации» при разрыве связи с облаком: туманный узел сохраняет доступность сервиса за счет локальной копии модели, а качество инференса снижается плавно и предсказуемо по мере устаревания данных. Полученные результаты демонстрируют практическую применимость адаптивной разгрузки как механизма повышения надежности (устойчивости к перегрузке и сетевой изоляции) для интеллектуальных систем. В дальнейших исследованиях планируется автоматизировать настройку параметров математической модели для повышения точности и переносимости механизма управления в различных профилях нагрузки и инфраструктурных конфигурациях.
Конфликт интересов
Финансирование
Библиографическая ссылка
Ермаков С.Р. ЭКСПЕРИМЕНТАЛЬНОЕ ИССЛЕДОВАНИЕ НАДЕЖНОСТИ ИНТЕЛЛЕКТУАЛЬНЫХ СИСТЕМ С ПРИМЕНЕНИЕМ МЕТОДОВ ОРГАНИЗАЦИИ ГЛОБАЛЬНО РАСПРЕДЕЛЕННОЙ АДАПТИВНОЙ ОБРАБОТКИ ПОТОКОВ ДАННЫХ // Современные наукоемкие технологии. 2026. № 2. С. 35-41;URL: https://top-technologies.ru/ru/article/view?id=40668 (дата обращения: 29.07.2026).
DOI: https://doi.org/10.17513/snt.40668