



Введение
Геопорталы представляют собой комплексные информационные системы, предоставляющие пользователям доступ к различным сервисам для работы с пространственными данными. На геопортале Института динамики систем и теории управления Сибирского отделения Российской академии наук (ИДСТУ СО РАН) разработан широкий набор веб-сервисов [1], позволяющих выполнять поиск, визуализацию и анализ разнообразных данных. Такое многообразие доступных инструментов, с одной стороны, расширяет возможности пользователя, но с другой – усложняет навигацию и выбор нужного сервиса под конкретную задачу. Возникает необходимость внедрения механизма персонализации, который облегчал бы пользователям поиск релевантных сервисов.
Основными пользователями данного геопортала являются научные сотрудники, применяющие предоставляемые сервисы как по отдельности, так и последовательно (в виде научных процессов, цепочек вызовов сервисов) для решения прикладных исследовательских задач. На практике было отмечено, что обилие доступных сервисов затрудняет быстрый выбор подходящего инструмента, особенно новых (ранее не использованных) сервисов. В этих условиях актуальной задачей становится разработка рекомендательной системы, способной автоматически предлагать каждому пользователю наиболее подходящие сервисы на основе анализа истории взаимодействий (поведения) и предпочтений без необходимости формулирования поискового запроса [2].
Современные рекомендательные системы строятся на различных методах анализа данных. Наиболее распространены подходы на основе контента, знаний, статистики, правил, а также совместной (коллаборативной) фильтрации (Collaborative Filtering, CF). Методы на основе знаний и статистики можно назвать базовыми, так как они не учитывают скрытых закономерностей (предпочтений) о поведении пользователя на геопортале. Методы на основе контента и метаинформации требуют глубокого погружения в систему понятий геопортала, логику работы самого сервиса для описания, требуют дополнительных затрат ресурсов на валидацию описаний [3, 4]. Методы пользовательской CF используют информацию о поведении пользователей на портале (прошлых взаимодействиях с объектами, например оценки сервисов или факты использования) для выявления скрытых закономерностей и формирования персональных рекомендаций [5, 6].
Преимущество совместной фильтрации состоит в том, что она не требует явного описания содержимого сервисов, а опирается на сходство между пользователями или объектами, выявленное из имеющихся данных о предпочтениях [6]. Например, если два пользователя использовали много одинаковых сервисов, то сервис, который впервые вызван первым пользователем и еще не был вызван вторым, может быть рекомендован второму – исходя из предположения, что у пользователей со схожими интересами будут совпадать и другие предпочтения [7].
Учитывая перечисленные преимущества, в качестве основы для рекомендательной системы выбран подход совместной фильтрации. В более ранней работе [8] был представлен прототип рекомендательной системы для геопортала ИДСТУ СО РАН на базе метода ближайших соседей. Это решение продемонстрировало принципиальную возможность улучшения процесса поиска сервисов за счет персонализации с помощью коллаборативной фильтрации.
Формально задача рекомендации сервисов может быть сведена к ранжированию множества сервисов S для каждого пользователя u ∈ U согласно некоторой функции релевантности, при этом |S| = m, |U| = n. Цель – построить функцию представленную в формуле
r : U×S→[0,1],
которая для пары «пользователь – сервис» возвращает степень релевантности сервиса данному пользователю (0 означает полное несоответствие потребностям, 1 – максимальную релевантность).
Цель исследования – разработка и экспериментальная оценка системы рекомендаций веб-сервисов обработки пространственных данных для распространения информации (рекомендации тех сервисов, что пользователь еще не использовал, но использовали другие пользователи со схожим научным интересом) на геопортале.
Материалы и методы исследования
Данные и подготовка. На геопортале организован сбор статистики использования сервисов: регистрируется каждое обращение пользователя к сервису (с указанием времени, идентификаторов и пр.). Эти данные о поведении пользователей трансформируются в матрицу «пользователь – сервис» Q, где элементом qij служит нормированное количество вызовов cij сервиса sj пользователем ui. Таким образом каждый пользователь ui описывается вектором qi = {qi1, …, qim }. Полученная матрица взаимодействий является разреженной, поскольку каждый конкретный пользователь использует лишь небольшой поднабор из множества доступных сервисов. Таким образом, на основе накопленных логов использования формируется датасет, служащий исходной информацией для алгоритмов коллаборативной фильтрации.
В выборке присутствуют взаимодействия 19 (n) пользователей с 199 (m) различными сервисами (всего зафиксировано 11 055 событий обращения к сервисам). Данные были разбиты на обучающую и тестовую части в соотношении 70/30. При разделении использовался временной принцип: отсортированные по времени взаимодействия первых 70 % составили обучающую выборку, а последние 30 % – тестовую.
Обучающая выборка позволила алгоритмам зафиксировать существующие закономерности в поведении пользователей и сформировать прогнозные модели предпочтений, тогда как тестовая часть имитировала появление новых взаимодействий, ранее неизвестных системе. Для каждого пользователя на основе обученной модели формировался список наиболее вероятных к использованию сервисов, с которыми он ранее не взаимодействовал. Сформированный список рекомендаций отражает предполагаемые будущие интересы и служит инструментом персонализированного выбора. Сравнение предсказанных рекомендаций с реальными обращениями пользователей из тестовой выборки дало возможность объективно оценить, насколько корректно каждая модель предсказывает будущее поведение и обеспечивает персонализированный выбор сервисов.
Метрики оценки. Для оценки рекомендаций использовались следующие метрики (вычислялись по топ-k рекомендациям для k = 5,10,15, затем усреднялись).
Точность (Precision@k): доля рекомендованных элементов из топ-k, которые оказались релевантными (то есть действительно использованы пользователем). Высокое значение Precision@k означает, что среди рекомендаций мало нерелевантных элементов.
Полнота (Recall@k): доля релевантных элементов, которые были найдены среди топ-k рекомендаций. Высокое значение Recall@k означает, что рекомендационная модель покрывает значительную часть предпочтений пользователя.
Полезность (NDCG@k): Нормализованный кумулятивный прирост полезности (Normalized Discounted Cumulative Gain) – нормализованный дисконтированный кумулятивный выигрыш, учитывающий позицию релевантных элементов в списке рекомендаций. Высокий NDCG@k означает, что релевантные элементы находятся ближе к началу списка (больший вес у верхних позиций). Значение NDCG нормируется в диапазон [0, 1].
Алгоритмы рекомендации. Всего в рамках исследования реализовано и протестировано 14 алгоритмов рекомендаций – от простых базовых до современных гибридных нейронных моделей. Перечисленные алгоритмы можно сгруппировать по категориям следующим образом:
− Базовые подходы: Popular (рекомендует самые популярные в системе сервисы по общей частоте использования) и Random (случайное ранжирование сервисов для каждого пользователя). Эти неперсонализированные стратегии служат ориентирами: модель Popular отражает максимум возможной полноты (Recall) при минимальной персонализации, а Random показывает нижнюю границу качества («без модели»).
− Memory-based совместная фильтрация: алгоритм на основе k ближайших соседей (user-based KNN) [6, 9]. Для каждого пользователя находятся несколько наиболее похожих по истории предпочтений пользователей, и ему рекомендуются сервисы, которые уже используются этими «соседями» [10]. В реализации использовался k = 4, метрика сходства – евклидово расстояние.
− Матричная факторизация: модели SVD, PCA, ALS, WRMF и NMF. Эти методы разлагают матрицу взаимодействий на матрицы меньшей размерности, выявляя скрытые (латентные) факторы пользователей и сервисов. Каждый пользователь и сервис представляются вектором в пространстве этих факторов, а степень интереса определяется, например, скалярным произведением соответствующих векторов. Классические методы SVD (сингулярное разложение матрицы) и ALS (чередующиеся наименьшие квадраты) оценивают латентные характеристики, оптимизируя приближение исходной матрицы рейтингов [4, 11]. Метод NMF (неотрицательное матричное разложение) накладывает неотрицательные ограничения на факторы, облегчая интерпретацию. Вариант WRMF (Weighted Regularized MF) модифицирует ALS для неявной обратной связи, вводя веса уверенности в наблюдаемых взаимодействиях [12, 13]. В целом модельно-ориентированные методы требуют значительных вычислений для обучения, но обеспечивают быстрое прогнозирование рейтингов после обучения.
− Нейросетевая модель: NCF (Neural Collaborative Filtering). Этот подход использует многослойный перцептрон для моделирования взаимодействий между пользователями и сервисами. Пользователям и сервисам сопоставляются обучаемые эмбеддинги (векторы признаков), которые объединяются и подаются на вход нейронной сети, предсказывающей вероятность взаимодействия [14]. Обучение NCF проводится на неявных данных (факт использования сервисов) с негативным семплированием и функцией потерь в виде бинарной кроссэнтропии. Нелинейная модель NCF теоретически способна выразить сложные зависимости предпочтений, выходя за рамки линейной гипотезы матричной факторизации.
− Глубокая гибридная модель: DeepFM (Deep Factorization Machine). Этот алгоритм сочетает факторизационную модель с глубоким нейронным подходом. Архитектура включает два компонента: FM-часть, которая эффективно моделирует парные взаимодействия признаков (аналогично MF для идентификаторов пользователей и сервисов), и глубокую часть (MLP), выявляющую нелинейные взаимосвязи более высокого порядка. DeepFM способен учитывать разнообразные признаки пользователей и объектов (в данном исследовании явно дополнительные признаки не использовались, модель работала только с ID), объединяя преимущества факторизации и глубокого обучения [15].
− Гибридные методы CF: LightFM и PHCF. Модель LightFM [16] реализует коллаборативный подход, расширяемый содержательными признаками, и оптимизируется по специальной ранжирующей функции потерь (в данной статье использовалась WARP – Weighted Approximate-Rank Pairwise). PHCF (Personalized Hybrid CF) – персонализированный гибридный подход, комбинирующий предсказания user-based и item-based стратегий [17]. Для каждого пользователя агрегируются оценки, полученные на основе схожести с другими пользователями и на основе сходства сервисов с уже понравившимися ему. В реализованном алгоритме PHCF-BPR обучение латентных факторов выполнено через оптимизацию функции потерь BPR (Bayesian Personalized Ranking) [18], направленной на улучшение качества ранжирования рекомендаций.
− Комбинированные ансамбли: методы KNN+LightFM-WARP и KNN+PHCF-BPR объединяют подходы на основе памяти и модели. Окончательный рейтинг рассчитывается как взвешенная сумма скорингов, полученных от KNN и соответствующей модельно-ориентированной алгоритмической части (LightFM или PHCF). Такая комбинация позволяет учесть одновременно «мнение» похожих пользователей и глобальные паттерны предпочтений, полученные моделью, с целью повысить общую точность рекомендаций.
Результаты исследования и их обсуждение
Эксперименты проведены на реальных данных использования геопортала, позволяющих объективно сравнить качество рекомендаций перечисленных алгоритмов. На основе тестовой выборки вычислены средние значения Precision@10, Recall@10 и nDCG@10 для каждой модели (таблица), а также сводный суммарный показатель качества (итоговый скор), рассчитываемый как взвешенная сумма метрик с наибольшим весом у nDCG. Общий скор отражает интегральную эффективность алгоритма, делая основной упор на качество ранжирования рекомендаций.
Итоговый скор складывается по формуле 0.3∙Precision + 0.3∙Recall + 0.4∙NDCG, отражая больший акцент на качестве ранжирования. Фактически NDCG получил наибольший вес, что соответствует ключевой роли порядка рекомендаций. Корреляционный анализ метрик показывает сильную связь между Recall и NDCG (r = 0,894) и умеренную – между Precision и NDCG (r = 0,798). Это означает, что модели с высоким NDCG обычно находят больше релевантных элементов (больший Recall).
Результаты сравнения алгоритмов рекомендательных систем
|
Алгоритм |
Precision |
Recall |
NDCG |
Общий скор |
|
PHCF-BPR |
0,080 |
0,093 |
0,203 |
0,133 |
|
KNN+PHCF-BPR |
0,081 |
0,080 |
0,202 |
0,129 |
|
LightFM-WARP |
0,055 |
0,079 |
0,172 |
0,109 |
|
NCF |
0,054 |
0,059 |
0,163 |
0,099 |
|
KNN |
0,047 |
0,074 |
0,148 |
0,096 |
|
KNN+LightFM-WARP |
0,046 |
0,070 |
0,126 |
0,085 |
|
Popular |
0,066 |
0,038 |
0,114 |
0,077 |
|
WRMF |
0,058 |
0,018 |
0,102 |
0,064 |
|
ALS |
0,027 |
0,018 |
0,081 |
0,046 |
|
NMF |
0,026 |
0,030 |
0,059 |
0,040 |
|
PCA |
0,028 |
0,017 |
0,063 |
0,039 |
|
DeepFM |
0,035 |
0,009 |
0,049 |
0,033 |
|
SVD |
0,022 |
0,010 |
0,042 |
0,026 |
|
Random |
0,029 |
0,006 |
0,036 |
0,025 |
Примечание: составлена авторами на основе полученных данных в ходе исследования.
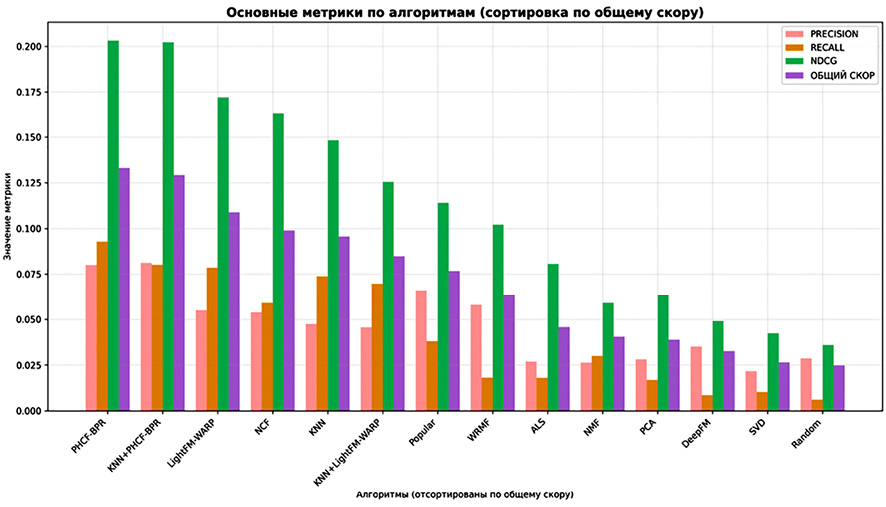
Сравнение 14 алгоритмов по метрикам качества рекомендаций: Precision, Recall и NDCG (усредненные значения) Примечание: составлен авторами по результатам данного исследования
Модель PHCF-BPR обеспечила наивысший суммарный скор (0,1331) за счет сбалансированных значений Precision (0,0801), Recall (0,0929) и особенно высокого NDCG (0,2031). Гибрид KNN+PHCF-BPR занял второе место (0,1293) с наилучшим значением Precision (0,0813) и почти таким же высоким NDCG (0,2021). Третью позицию занял LightFM-WARP (общий скор 0,1089). Напротив, классические методы и нейросетевые модели показали существенно более низкие результаты: так, NCF набрал суммарный скор 0,0990, уступив LightFM-методам и находясь на уровне простого KNN (0,0957), а DeepFM с общим скором 0,0327 продемонстрировал минимальную эффективность. Базовый метод Popular показал умеренную точность (Precision 0,0661) при очень низкой полноте (Recall 0,0380), что указывает на то, что частые сервисы хорошо работают на Precision, но не покрывают все релевантные объекты. Случайная стратегия (Random) дала худшие результаты по всем метрикам, что подтверждает обоснованность использования более сложных методов.
Модель PHCF-BPR выигрывает за счет оптимизации ранжирования: ее функция потерь BPR прямо нацелена на повышение ранговой метрики. В итоге лучшие модели демонстрируют одновременно высокие значения всех трех показателей, тогда как у базовых подходов (например, Popular и KNN) или нейросетевых методов обычно наблюдается перекос в одну из метрик в условиях малого объема данных.
На рисунке представлено сравнение ключевых метрик (Precision, Recall, NDCG) для всех алгоритмов. Видно, что методы семейства PHCF опережают остальные подходы по всем показателям, особенно по Precision и NDCG. Нейронные сети (NCF) демонстрируют хорошие показатели NDCG, но несколько уступают в Precision. KNN и Popular достигают высоких значений Recall и Precision соответственно, что делает их полезными в определенных сценариях. Модели матричной факторизации (SVD, PCA, NMF, ALS, WRMF) расположены в нижней части графиков, существенно уступая более современным методам.
Выявлено явное превосходство гибридных подходов на основе BPR-оптимизации. PHCF-модели эффективно объединяют коллаборативную и содержательную составляющие (в данной работе содержательные признаки не использовались явно, но сама модель имеет регуляризующий эффект и оптимизирует ранжирование). Алгоритм PHCF-BPR достигает высокого NDCG за счет прямой оптимизации этой метрики в функции потерь. Гибрид KNN+PHCF-BPR дает наилучший Precision, поскольку учитывает как близость пользователей, так и глобальные паттерны, что улучшает точность рекомендаций. Нейронные сети (NCF, DeepFM) при столь малом объеме данных (19 пользователей) не смогли полностью реализовать свой потенциал – им, вероятно, требуется больше данных для обучения большого числа параметров. Тем не менее NCF показала себя достойно, что подтверждает эффективность даже относительно простых MLP-архитектур для коллаборативной фильтрации [19].
Выводы
Для рекомендательной системы геопортала были разработаны и протестированы рекомендательные модели для подбора новых (ранее не используемых данным пользователем) сервисов на основе методов коллаборативной фильтрации. Был проведен эксперимент, определены самые эффективные гиперпараметры для каждой модели, внедрен наиболее эффективный алгоритм рекомендации PHCF-BPR.
Разработанная рекомендательная система решает проблему поиска сервисов и распространения информации об их использовании среди специалистов одной предметной области и способна рекомендовать сервисы, которые пользуются популярностью, с учетом области интересов.
Проведенное сравнительное исследование алгоритмов показало, что подходы на основе PHCF с функцией потерь BPR демонстрируют наилучшие результаты по ключевым метрикам рекомендаций, модель значительно превосходит классические методы по точности благодаря оптимизации ранжирования, а ее гибридизация с KNN позволяет дополнительно повысить полноту и качество ранжирования рекомендаций. Нейронные методы (NCF, DeepFM) при небольшом объеме данных не достигли лидирующих позиций, однако NCF заняла достойное место, подтвердив жизнеспособность нейросетевого подхода. Простые алгоритмы (например, KNN, Popular) остаются конкурентоспособными на разреженных данных, обеспечивая относительно высокие показатели для своих классов сложности.
Основные выводы исследования:
1. Алгоритмы PHCF (BPR) превосходят классические методы – за счет прямой оптимизации ранжирования они достигают более высокой точности рекомендаций.
2. Гибридные подходы эффективны для максимизации качества – комбинация моделей (например, KNN+PHCF-BPR) позволяет улучшить одновременно Precision, Recall и NDCG за счет учета разных аспектов предпочтений.
3. Нейросетевые модели требуют больше данных – на ограниченном датасете их потенциал не раскрыт полностью, однако они способны показывать хорошие результаты при достаточном объеме взаимодействий.
4. Простые методы остаются полезными – в условиях дефицита данных или для быстрого прототипирования модели вроде Popular и KNN дают приемлемое качество при минимальной сложности.
Полученные результаты вносят вклад в понимание практической применимости различных подходов к построению рекомендательных систем и предоставляют научно обоснованные рекомендации для выбора алгоритмов в зависимости от специфики задачи и доступных ресурсов. В частности, для промышленного внедрения на рассматриваемом геопортале можно рекомендовать использовать комбинацию лучших моделей (PHCF-BPR в качестве основной, гибридный KNN+PHCF-BPR для усиления ранжирования, а также добавить NCF и KNN в ансамбль для учета разных аспектов). Для быстрых прототипов достаточно ограничиться простыми алгоритмами Popular и KNN, дополнив их моделью PHCF-BPR для повышения точности. В исследовательских целях перспективно включать в рассмотрение более сложные модели (DeepFM) и их модификации, поскольку на больших объемах данных или с добавлением контентных признаков они могут показать себя лучше.
Таким образом, реализованная рекомендательная система показала свою эффективность для поддержки пользователей геопортала ИДСТУ СО РАН, а проведенный анализ алгоритмов предоставляет базу для ее дальнейшего совершенствования.
Конфликт интересов
Финансирование
Библиографическая ссылка
Климонов М.С. ПРИМЕНЕНИЕ МЕТОДОВ СОВМЕСТНОЙ ФИЛЬТРАЦИИ В РЕКОМЕНДАТЕЛЬНОЙ СИСТЕМЕ ГЕОПОРТАЛА // Современные наукоемкие технологии. 2026. № 1. С. 44-50;URL: https://top-technologies.ru/ru/article/view?id=40647 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.40647