



Введение
Сегодня социальное взаимодействие в человеческом сообществе трансформировалось в новую цифровую парадигму, в рамках которой удаленный доступ к различным сайтам, видеохостингам, новостным порталам, социальным сетям, маркетплейсам и другим популярным сервисам стал привычным и обыденным. Характерным и, по-видимому, главным свойством виртуального пространства является большой объем неструктурированной или слабо структурированной естественно-языковой информации, ориентация в котором возможна только по ее смысловому содержанию, т.е. по семантике. В этой связи умение выделять и точно интерпретировать семантику естественно-языковой информации становится главным фактором успеха в виртуальном мире. Реализация таких возможностей предполагает наличие соответствующего инструментария, в связи с чем разработкам моделей и методов интерпретации семантики придается такое важное значение в обработке естественно-языковой информации.
В настоящее время в области естественно-языковой обработки много ожиданий связывают с переживающим ренессанс нейросетевым подходом, в рамках которого в наибольшей степени выделяются технологии глубокого обучения (Deep Learning) и большие языковые модели (LLM – Large Language Models). Знаковым событием, породившим интерес к глубоким языковым моделям, стало появление в 2018 году модели BERT (Bidirectional Encoder Representations from Transformers) от Google, ориентированной на понимание контекста, а ее интеграция в поисковую систему оказала сильнейшее влияние на обработку естественного языка (NLP – Natural Language Processing). Сегодня на базе BERT создается множество NLP-инструментов, и совокупность связанных с ним технологий и исследований получила в профессиональной среде неформальное название «бертология». Наряду с BERT следует отметить модель GPT от OpenAI, направленную на генерацию текстов, открытую модель LLaMA от Meta (Meta – признана экстремистской организацией и запрещена на территории России), а также мультимодальную систему Gemini от Google, способную обрабатывать как тексты, так и изображения. Объединяющей особенностью всех данных моделей является использование трансформерной архитектуры.
Ввиду проявляемого сегодня повышенного интереса к идеям искусственного интеллекта целесообразным представляется сделать краткий обзор ключевых направлений исследований со ссылками на наиболее репрезентативные источники, связанные с бертологией.
Первое направление связано с систематизацией знаний и методологических подходов. Авторы Rogers A. и др. провели всесторонний анализ BERT [1], включая механизмы внимания, особенности лингвистических представлений и методы тонкой настройки. Исследование авторов Pengfei Liu и др. посвящено обзору, классификации и оценке методов промтинга для предобученных нейросетей, а также анализу их преимуществ и ограничений [2]. Под промтингом понимается краткая формулировка задачи или инструкции, существенно влияющая на качество обучения модели.
Второе направление связано с архитектурными усовершенствованиями в рамках трансформерной парадигмы. Так, авторами Devlin J. и др. предложен новый подход к предобучению на основе маскированного языкового моделирования и предсказания следующего предложения, позволяющий формировать глубокие двунаправленные представления [3]. Данная модификация демонстрирует преимущества над базовой архитектурой при решении 11 ключевых задач NLP. Авторы Raffel Colin и др. исследовали унифицированный подход «текст-к-тексту», в котором разнородные задачи преобразуются в единый формат генерации текста [4]. Эксперименты с моделью объёмом 11 миллиардов параметров подтверждают эффективность такой архитектуры для решения различных задач без потери качества при масштабировании. Там же представлен новый датасет C4 объёмом 750 ГБ и проведён детальный анализ архитектурных вариантов.
Третье направление посвящено семантическим аспектам обработки языка и представлено исследованиями векторных моделей. Так, авторами Arora Sanjeev и др. предложен простой, но эффективный метод построения векторных представлений предложений путём взвешенного усреднения векторов слов с использованием формулы a/(a+p(w)), где a – гиперпараметр [5]. Этот подход превосходит традиционные RNN и LSTM на стандартных тестах семантического сходства. Авторами Reimers N. и др. рассмотрена модель Sentence-BERT [6], представляющая модификацию BERT, специально оптимизированную для вычисления семантического сходства предложений с использованием косинусной меры. Авторы Conneau A. и др. исследовали метод обучения универсальных векторных представлений на основе естественного языкового вывода (Natural Language Inference) [7], который демонстрирует универсальность в сравнении с традиционным обучением с учителем.
Четвёртое направление касается интерпретируемости языковых моделей. Представленная авторами Artetxe M. и др. система LASER [8] создает единое векторное пространство для предложений на 93 языках, используя общий трансформерный архитектурный каркас. Исследование авторов Agirre E. и др. представляет результаты масштабного сравнительного анализа 17 систем оценки семантического текстового сходства [9].
Пятое направление объединяет практически ориентированные исследования. Авторы Yin S. и др. представляют семейство специализированных языковых моделей для медицины, прошедших многоэтапное обучение на медицинских текстах [10]. Исследованная авторами Zhu L. и др. нейрогенеративная модель [11] решает задачу тематического моделирования с совместной оптимизацией тем и векторных представлений слов на основе модифицированного вариационного автоэнкодера. Авторами Bender E.M. и др. проанализированы риски масштабирования языковых моделей и ограничения существующих методов оценки [12].
Обзор завершает описание эталонного теста авторов Thakur Nandan и др. для сравнительной оценки эффективности поисковых систем, основанных на нейросетевых архитектурах [13].
Безусловно, приведенная классификация носит весьма субъективный характер и не претендует на исчерпывающую полноту описания быстро развивающейся области больших языковых моделей и глубокого обучения. И тем не менее при всех достоинствах глубоких языковых моделей они весьма уязвимы со стороны высоких требований к вычислительным ресурсам, которые могут обеспечить только крупные корпорации, кроме того, надежность получаемых результатов и доверие к ним также являются весьма условными.
Разработанные авторами Вишняковым Ю.М. и Вишняковым Р.Ю. вычислительная теория семантической интерпретации [14], формальная модель семантического объекта [15] и алгоритмы поиска текстов определенной семантической направленности [16] представляют альтернативу решениям бертологии, в основе они восходят к формально-грамматическому подходу и реализованы в предлагаемом в настоящей работе программном комплексе. Он предназначен для выявления текстов определенной семантической направленности в естественно-языковых потоках. Обсуждаемый программный комплекс в сравнении с глубокими языковыми моделями не требует больших вычислительных ресурсов, предобучения и обучения, а результаты его работы поддаются точной математической оценке.
Цель исследования – практическое обоснование и реализация разработанной авторами новой концептуальной модели выявления в естественно-языковых потоках текстов определенной семантической направленности по формальным описаниям их источников.
Материалы и методы исследования
Рассмотрим кратко основные ключевые элементы и особенности подхода, положенные в основу работы программного комплекса.
Естественно-языковой поток Т = t1t2…tm, представляется последовательностью неделимых по смыслу текстовых элементов (токенов – предложений или их фрагментов). Текстовым потоком можно считать чат мессенджера или социальной сети, который содержит порождаемый человеком, чат-ботом или иным объектом осмысленный текст определенного содержания, направленный на достижение конкретных целей. Лингвистическую модель такого объекта будем называть семантическим объектом.
Формально семантический объект представляется характеристическим множеством Q = {q1,q2,…,qn} и множеством поведенческих сценариев L(Q) = {1,2,…,m}, L(Q)Q*, где 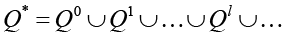 , где Q0={λ} – аксиома, λ – пустая цепочка. Элемент qi множества Q называется характеристикой, представляющей целостный по смыслу фрагмент текста (токен). Семантический объект из характеристик конструирует тексты (сценарии L(Q)). В общем случае множество L(Q) можно представить языком некоторой формальной грамматики G[Z], у которой Z – начальный символ, множество Q – терминальный словарь и сценарий a• редактор семантических объектов;
, где Q0={λ} – аксиома, λ – пустая цепочка. Элемент qi множества Q называется характеристикой, представляющей целостный по смыслу фрагмент текста (токен). Семантический объект из характеристик конструирует тексты (сценарии L(Q)). В общем случае множество L(Q) можно представить языком некоторой формальной грамматики G[Z], у которой Z – начальный символ, множество Q – терминальный словарь и сценарий a• редактор семантических объектов;
• подсистема сравнения текстовых фрагментов на семантическую близость;
• подсистема поиска и выявления семантических следов,
а его структура показана на рисунке 1.
Входными данными для программного комплекса являются текстовый поток и формальное описание семантического объекта, выходными – результат идентификации семантического объекта. Рассмотрим назначение и особенности работы отдельных подсистем.
Подсистема «редактор семантических объектов». Редактор предназначен для конструирования формального описания на основе вербальной информации из образцов потоков о поведении семантического объекта.
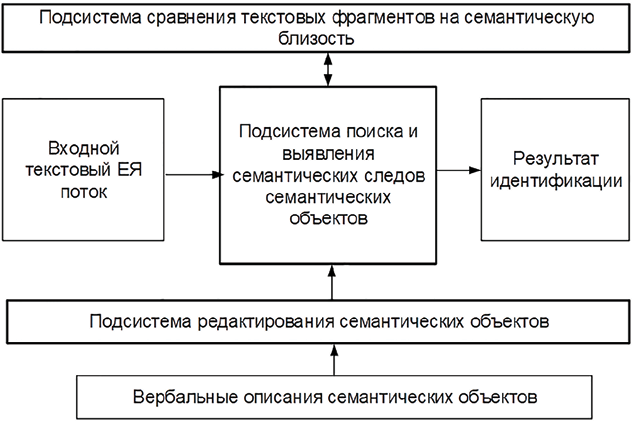
Рис. 1. Состав и структура программного комплекса Источник: составлено авторами

Рис. 2. Фрагменты текстовых потоков T1, T2 и Т3 Источник: составлено авторами
Оператор в диалоговом режиме с помощью редактора конструирует характеристическое множество Q, затем создается регулярное выражение и далее конструируется формальное описание семантического объекта. Последние два этапа выполняются автоматически. Формальное описание семантического объекта в формате файлов JSON заносится в базу данных и может в последующем модифицироваться с учетом новой информации.
Проиллюстрируем процесс редактирования на примере некоего К (семантический объект), участвовавшего в диалогах текстовых потоков Т1, Т2 и Т3, которые фрагментарно представлены на рисунке 2.
Формальная процедура конструирования характеристического множества имеет вид.
Вход: образцы текстовых потоков, вербальная информация о семантическом объекте.
Выход: характеристическое множество семантического объекта.
Алгоритм.
1. Из тестовых потоков выбрать наиболее близкие по смыслу токены и свести их в кластеры по смысловому подобию.
2. Для каждого кластера создать точную по смыслу формулировку характеристики.
3. Построить характеристическое множество.
В случае примера результат алгоритма показан на рисунке 3.
На рисунке 3 в колонке «Кластер» рядом с токеном в скобках указаны потоки, в которые он входит, в следующей колонке находится назначенная характеристика кластера.

Рис. 3. Формирование лингвистических характеристик Источник: составлено авторами
Сформированное характеристическое множество семантического объекта К в формате JSON имеет вид:
“P”: {
“q1”: “Добро пожаловать в игру”,
“q2”: “Чтобы победить, ты должен выполнить все задания”,
…………….,
“q6”: “Выйти из игры можно только, пройдя ее до конца”
}
Конструирование сценариев начинается с создания словаря следования характеристик, в котором каждый элемент представляет характеристику pi и множества характеристик {pi1, pi2 …, pik}, могущих следовать за ней в сценариях. В случае примера словарь следования в формате JSON имеет вид:
“Sequences”: {
“q3”: [“q4 ”],
“q4”: [],
“q6”: [“q3”],
“q5”: [“q3”],
“q1”: [“q5”, “q2”],
“q2”: [“q6”, “q3”]
}
Далее конструируется диаграмма состояний, дуги в которой задают переходы между состояниями и поименованы характеристиками. Такая диаграмма состояний описана авторами Ахо А. и Ульманом Дж. [17, с. 124-162] и Льюис Ф. и др. [18, с. 202-339] и представляет собой систему переходов, которая имеет одно начальное и одно заключительное состояния.
Процедура построения системы переходов.
Вход: словарь следования характеристик.
Выход: система переходов.
Алгоритм.
1. Создать начальное состояние “S0” и конечное состояние “Z”.
2. Найти по словарю следования характеристики, не имеющие родителей, провести соответствующие им дуги из начального состояния в новые состояния. При необходимости поименовать новые состояния.
3. Для каждого вновь полученного состояния построить поименованную характеристикой дугу перехода и создать следующее новое состояние.
Полученная диаграмма состояний в общем случае избыточна и требует упрощения (нормализации) путем удаления в одном и том же переходе одинаковых дуг и объединения эквивалентных состояний. В случае примера нормализованная диаграмма состояний системы переходов и ее представление в формате JSON показана на рисунке 4.
По нормализованной диаграмме состояний собирается регулярное выражение. Тривиальный алгоритм сборки имеет следующий вид.
Вход: нормализованная система переходов.
Выход: регулярное выражение.
Алгоритм.
1 Для каждого пути, ведущего из начального состояния в конечное состояние:
1.1 представить последовательность характеристик дуг, входящих в путь, регулярным выражением;
1.2 если в пути встречается кольцевой подпуть, то соответствующее ему подвыражение заключить в фигурные скобки.
2 Объединить с помощью операций “|” (ИЛИ) в одно регулярное выражение выражения альтернативных путей.
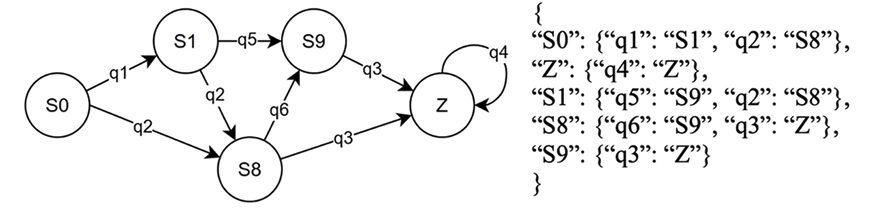
Рис. 4. Нормализованная диаграмма состояний и ее представление в формате JSON Источник: составлено авторами.
Сконструированное регулярное выражение системы переходов примера имеет вид:
q1q5q3{q4}|q1q2q6q3{q4}|q1q2q3{q4}|q2q6q3{q4}|q2q3{q4}.(1)
Оно избыточно и нуждается в нормализации. Для этого используется факторизация (вынос общих частей альтернатив за круглые скобки) и удаление лишних альтернатив. Пошагово процесс нормализации имеет вид:
1 q1q5q3{q4}|q1q2q6q3{q4}|q1q2q3{q4}|q2q6q3{q4}|q2q3{q4};
2 (q1q5q3|q1q2q6q3|q1q2q3|q2q6q3|q2q3){q4};
3 (q1(q5q3|q2q6q3|q2q3))|q2q6q3|q2q3){q4};
4 (q1(q5q3|q2q6q3|q2q3))|q2(q6q3|q3)){q4};
5 (q1(q5q3|q2(q6q3|q3))|q2(q3q6|q3)){q4}.
Здесь выносимое за скобки подвыражение выделено жирным шрифтом.
По завершении редактирования формальное описание принимает вид:
{
“reg_var”: “((q1(q5q3|q2(q6q3|q3))|q2(q6q3|q3)){q4})”,
“props”: {
“q1”: “Добро пожаловать в игру”,
“q2”: “Чтобы победить, ты должен выполнить все задания”,
“q3”: “Игра поможет тебе понять себя”,
“q4”: “Мы поможем тебе пройти игру”,
“q5”: “Покинуть игру уже нельзя”,
“q6”: “Выйти из игры можно только пройдя ее до конца”
}
}
Подсистема сравнения текстовых фрагментов на семантическую близость. Работа подсистемы организуется в два этапа, на первом выполняется построение семантических схем сравниваемых текстовых фрагментов, а на втором – их семантическое сравнение.
На первом этапе на вход последовательно поступают два исходных предложения и для каждого выполняется процедура первичной обработки, токенизации и построения дерева зависимостей. Во время первичной обработки текст очищается от специальных символов и пунктуационных знаков, токенизация разбивает текст на целостные по смыслу фрагменты (токены) и далее для текста создается дерево зависимостей. Токенизацию и построение дерева зависимостей выполняет описанная авторами Qi P. и др. частично обученная нейросеть [19]. Для устранения ошибок и неоднозначности семантических связей предусмотрен ручной режим редактировании дерева зависимостей. По дереву конструируется функционал смысла семантических предложений в нотации, подобной обратной польской записи (ОПЗ), а далее ОПЗ преобразуются в семантическую схему. На втором этапе осуществляется семантическое сравнение предложений с вычислением оценки семантической близости текстовых фрагментов.
Подсистема поиска и выявления семантических следов отыскивает и распознает семантические следы, идентифицирует семантический объект. За установлением семантической близости характеристики и токена подсистема обращается к подсистеме сравнения текстовых фрагментов на семантическую близость.
Работа подсистема начинает с нормализации текстового потока, для чего из потока исключаются токены, заведомо могущие быть семантическими следами характеристик. После нормализации поток представляет собой упорядоченный по номерам токенов список пар, в каждой паре левая часть представляет токен, а правая – список характеристик семантического объекта, для которых токен является семантическим следом. В свою очередь каждая характеристика списка токена также представляется парой, ее левая часть – это характеристика, а правая – значение семантической близости с токеном. Список характеристик упорядочен по убыванию семантической близости. Такой нормализованный поток представляется в виде:
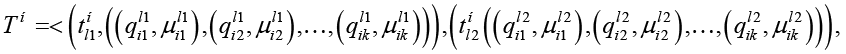
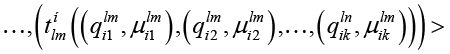 ,(2)
,(2)
где 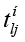 – токен нормализованного потока Tн с номером lj, пара
– токен нормализованного потока Tн с номером lj, пара 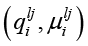 представляет связанную с токеном характеристику
представляет связанную с токеном характеристику 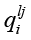 со степенью семантической близости
со степенью семантической близости 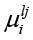 .
.
Процедура нормализации имеет следующий вид.
Вход:
исходный текстовый поток Т = t1t2…tm;
характеристическое множество семантического объекта Q;
порог фильтрации токенов.
Выход: нормализованный текстовый поток Tн.
Алгоритм.
1. Установить значение порога фильтрации.
2. Для каждого токена текстового потока:
2.1. провести его семантическое сравнение со всеми характеристиками семантического объекта;
2.1.1. если значение семантической близости больше порогового значения, то характеристику включить в список характеристик токена со значением семантической близости.
2.2. Список характеристик токена упорядочить по убыванию степени близости.
2.3. Токен включить в нормализованный текстовый поток Tн.
3. Нормализованный текстовый поток Tн сформирован.
Сборка и распознавание сценария семантического объекта осуществляется одновременно по нормализованному потоку, при этом сценарий должен представлять либо путь из начального состояния в конечное, либо его фрагменты в системе переходов. В процедуре для каждого токена из списка характеристик последовательно выбирается новая характеристика, проверяется наличие одноименной дуги в системе переходов и при положительном исходе эта характеристика добавляется к собираемому сценарию, а система переходов переходит в следующее состояние. Далее процесс повторятся для нового токена. Если дуга не найдена, то характеристика отбрасывается и выбирается в списке токена следующая за ней. По исчерпании списка характеристик токена осуществляется возврат к предыдущему токену, в нем отбрасывается выбранная характеристика и выбирается следующая по списку, далее процесс повторяется, реализуя процесс направленного поиска характеристик собираемого сценария механизмом бэктрекинга. Параллельно процессу сборки и распознавания сценария формируется функция подобия из семантических близостей его характеристик, представляющая значение результата идентификации.
Тестирование и эксперименты. Полноценное планирование и обработка результатов экспериментов является трудоемким и комплексным мероприятием, которое предполагает разработку оценочных метрик, согласованных схем и пространства экспериментов, правдоподобных датасетов, а также получение полноценных репрезентативных статистических данных. В настоящее время такое исследование еще продолжается, однако для формирования целостного представления о работе авторы посчитали возможным привести результаты одного из экспериментов.
Эксперимент проводится для изучения влияния полноты формального описания семантического объекта на точность его идентификации. Он построен по следующей правдоподобной схеме: семантический объект К ведет в чатах игровые диалоги и предлагает собеседнику выполнить определенные действия. Объект К адаптирует диалог к конкретной ситуации и может конструировать различные поведенческие сценарии. Результаты идентификации объекта программным комплексом сопоставляются с оценками трех независимых экспертов. Ход эксперимента. В редакторе на основе предварительно подготовленных образцов текстовых потоков Т1, Т2 и Т3 созданы три формальных описания объекта К с возрастающей степенью полноты. Каждое последующее описание включало характеристическое множество предыдущего описания с добавлением новых элементов поведения. Вариант 1 (22 характеристики) построен на основе потока Т1, вариант 2 (43 характеристики) использует данные из Т1 и Т2, вариант 3 (68 характеристик) построен на данных Т1, Т2 и Т3. Все три варианта формальных описаний представлены на рисунке 5, где для упрощения во 2-м и 3-м вариантах показаны только вновь добавленные характеристики.
В качестве датасета сгенерировано пять правдоподобных диалоговых потоков объемом 250-300 предложений, что примерно соответствует часовой беседе в чате. При этом Тд1 не содержит семантического объект К, а в Тд2 – Тд5 объект К включен различными поведенческими сценариями.
Процедура экспертной оценки включала изучение объекта К по исходным образцам потоков Т1, Т2 и Т3 и анализ потоков Тд1 – Тд5 на присутствие К. Оценка выполнялась по лингвистической шкале: [«отсутствует», «слабо выражено» «выражено средне», «выражено выше среднего», «выражено сильно»] и представляет разработанную автором Заде Люфти А. лингвистическую переменную, значениями которой являются нечеткие переменные [20, с. 90-112]. Для нечетких переменных эксперты оценили интервалы и наиболее вероятные значения. Усредненные экспертные данные приведены в таблице 1.

Рис. 5. Варианты формального описания семантического объекта К Источник: составлено авторами.
Таблица 1
Экспертные оценки
|
Лингвистическая шкала |
Числовой интервал |
Усредненная оценка |
Текстовый поток |
|
«отсутствует» |
[0,00-0,15] |
0,08 |
Тд1 |
|
«слабо выражено» |
(0,15-0,35] |
0,3 |
Тд2 |
|
«выражено средне» |
(0,35-0,60] |
0,5 |
Тд3 |
|
«выражено выше среднего» |
(0,60-0,85] |
0,7 |
Тд4 |
|
«выражено сильно» |
(0,85-1,00] |
0,95 |
Тд5 |
Источник: составлено авторами на основе полученных данных в ходе исследования.
Таблица 2
Сводные результаты программного комплекса
|
Варианты описания |
Тд1 |
Тд2 |
Тд3 |
Тд4 |
Тд5 |
|
Вариант 1 |
0,00 |
0,2 |
0,56 |
0,68 |
0,80 |
|
Вариант 2 |
0,062 |
0,29 |
0.81 |
0,87 |
0,92 |
|
Вариант 3 |
0,035 |
0,32 |
0,83 |
0,91 |
0,92 |
Источник: составлено авторами на основе полученных данных в ходе исследования.
В таблице 2 приводятся результаты идентификации объекта К программным комплексом с нулевым порогом идентификации для учета минимальных значений.
Интерпретация результатов. В целом между оценками экспертов и результатами программного комплекса наблюдается высокая согласованность в пределах 10%. Различия оценок идентификации варианта 2 и варианта 3 статистически не значимы и объясняются погрешностями в построении семантических деревьев и семантических схем. В ходе эксперимента выявлено, что для каждого варианта описания существует пороговый диалог, начиная с которого идентификация становится устойчивой; для варианта 1 это Тд4, для вариантов 2 и 3 – Тд3. Кроме того, имеет место эффект, когда после достижения определенной полноты описания (вариант 2) дальнейшее увеличение полноты не приводит к существенному росту точности идентификации. По-видимому, данные закономерности имеют место для всех идентифицируемых семантических объектов, и их учет при конструировании формальных описаний семантических объектов позволит выбрать в каждом конкретном случае приемлемую полноту формального описания.
Заключение
В работе представлен программный комплекс, в котором впервые реализован новый авторский подход по выявлению текстов определенной семантической направленности по формальному описанию их источников в естественно-языковых текстовых потоках. Рассмотрены состав программного комплекса и его функционалитет, подсистемы и их назначение, основные структуры данных, алгоритмы обработки и результаты тестовых экспериментов. На конкретных примерах проиллюстрирована и разобрана работа основных подсистем. Тестовыми испытаниями установлено и подтверждено, что точность идентификации семантических объектов фактически определяется вычисленной степенью семантической близости между поведенческими сценариями и найденными семантическими следами в текстовых потоках. Результаты проведенных тестовых испытаний и экспериментов подтвердили работоспособность программного комплекса, а также продемонстрировали соответствие полученных данных основным теоретическим положениям и выводам, лежащим в основе его функционирования.
Важными преимуществами и отличительными особенностями программного комплекса являются быстрая настройка на решаемую задачу путем конструирования по исходным вербальным данным формальной модели семантического объекта, отсутствие предобучения и обучения, что свойственно нейросетевым решениям, и точная математическая оценка результата работы.
Проведённое исследование и его результаты направлены на практическое развитие математического моделирования и создание эффективных программных систем в области обработки естественно-языковой информации на основе развиваемой авторами вычислительной теории семантической интерпретации.
На программные решения, использованные при создании программного комплекса, получены охранные документы в виде свидетельств на программы.
Конфликт интересов
Библиографическая ссылка
Вишняков Ю.М., Вишняков Р.Ю. ПРОГРАММНЫЙ КОМПЛЕКС ИДЕНТИФИКАЦИИ ТЕКСТОВ ОПРЕДЕЛЕННОЙ СЕМАНТИЧЕСКОЙ НАПРАВЛЕННОСТИ В ЕСТЕСТВЕННО-ЯЗЫКОВЫХ ПОТОКАХ // Современные наукоемкие технологии. 2025. № 9. С. 29-38;URL: https://top-technologies.ru/ru/article/view?id=40482 (дата обращения: 23.07.2026).
DOI: https://doi.org/10.17513/snt.40482