



Введение
В настоящее время в обработке естественно-языковой информации больших объемов возникла потребность выявления текстов определенной семантической направленности и определения их источников, что зачастую необходимо в анализе новостных потоков, чатов мессенджеров, социальных сетей, проверке документов на плагиат, установлении авторства и других подобных задачах. Однако, несмотря на наличие современного инструментария [1, с. 79–181] и его специальные приложения [2, с. 130–190], позволяющие достаточно быстро и эффективно разрабатывать программы, проблема нуждается в хорошей теоретической проработке и создании собственного формального подхода для ее решения.
Анализ показывает, что в области естественно-языковой обработки существует большое число различных исследований, которые находят отражение во многих публикациях. Если попытаться условно классифицировать их по направлениям, то, наверное, в первую группу следует включить работы фундаментального характера по всему спектру естественно-языковой обработки, например [3, с. 60–93]. Вторую группу можно составить из работ, направленных на поиск универсальных решений на основе нейросетевых технологий [4]. В третью группу сводятся работы по методам извлечения информации из текстов [5; 6]. Четвертую группу можно образовать по семантической кластеризации областей знаний и их классификации [7]. Группа исследований в нетрадиционной постановке также многочисленна, например обработка естественно-языковых запросов для точных областей знаний [8]. В нее можно добавить области обучения [9; 10] и мультимедиа [11]. Отдельную группу образуют работы по семантическим моделям конкретных частных задач [12–14]. Безусловно, вышеперечисленным не исчерпывается все многообразие исследований, однако анализ показывает, что все они только частично в той или иной мере касаются проблемы поиска естественно-языковых потоков текстов определенной семантической направленности, само решение проблемы видится в создании собственных теоретические наработок.
Следует также обратить внимание на точность естественно-языковой обработки. Она зависит от множества факторов, ключевые из которых представляют используемая модель семантики и затраты на ее реализацию. На сегодня наиболее распространена и изучена частотная модель семантики, ее суть выражает сентенция – текст тем релевантнее запросу, чем чаще его слова входят в этот текст. Типичные частотные методы – «мешок слов», алгоритмы TF-IDF, векторные модели, нейросетевые и пр. Однако частотная модель заранее должна быть настроена на статистические характеристики обрабатываемых текстов. Процесс требует большого объема тщательно составленных обучающих выборок, но и после этого доверие к точности результатов обработки может быть подвергнуто сомнению. В контексте повышения точности обработки естественно-языковых данных на многочисленных научных форумах и в публикациях уже давно дискутируется вопрос о переходе на иные модели семантики, поскольку затраты на улучшение частотной модели зачастую не приводят к ожидаемым результатам. В этом ключе авторы развивают вычислительную модель представления семантики [15], положенную в основу предлагаемого исследования. Непосредственно сама предлагаемая работа направлена на решение проблемы поиска и выявления текстов определенной семантической направленности в естественно-языковых потоках.
Цель исследования – обоснование концептуальной модели выявления в естественно-языковых потоках текстов определенной семантической направленности по формальным описаниям их источников.
Материалы и методы исследования
Трудности решения проблемы состоят в том, что понятие «определенная семантическая направленность» имеет вербальную формулировку и соотнесение с ней смыслового содержания текста понятно в человеческом контексте. Однако формальное решение предполагает отображение проблемы в точные формальные модели, процедуры и алгоритмы, которые могут быть программно реализованы. Для этого в исследовании предлагается использовать вычислительную теорию семантической интерпретации и теорию формальных языков и грамматик. Обсудим прежде несколько формальных понятий.
Под естественно-языковым потоком будем понимать последовательность неделимых по смыслу текстовых элементов (токенов – предложений или их фрагментов) вида T = t1t2…tm, где ti – токен.
Семантическим объектом будем считать некий гипотетический объект, который, исходя из своих внутренних целей и задач, из токенов множества P = {p1, p2,…, pn} По определенным правилам может сконструировать осмысленный текст αi из множества текстовых последовательностей L(P) = {α1, α2, … αm}, L(P) ⊂ P* и 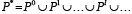 , где P0 = {λ} – аксиома и λ – пустая цепочка. Совместно множество P и правила (способы) конструирования последовательностей L(P) назовем семантическим описанием объекта.
, где P0 = {λ} – аксиома и λ – пустая цепочка. Совместно множество P и правила (способы) конструирования последовательностей L(P) назовем семантическим описанием объекта.
Для семантического объекта множество P играет роль смыслового лексикона, из элементов которого конструируются текстовые последовательности (тексты) определенного смыслового содержания. Элементы pi∈P назовем характеристиками семантического объекта, само P – характеристическим множеством и сконструированный текст αi ∈ L(P) – сценарием [6].
С учетом данных понятий формальная постановка задачи выглядит следующим образом. Пусть имеется некоторый текстовый поток T и заданный характеристическим множеством P и множеством сценариев L(P) семантический объект. Требуется проверить присутствие в текстовом потоке текста, семантически подобного сценарию αi ∈ L(P), и вычислить степень такого подобия.
1. Семантическое подобие текстовых элементов
Обсудим семантическое подобие двух текстовых элементов (токенов) в вычислительной модели семантики [15]. Будем считать, что и токены из Т, и элементы из P целостны по смыслу и представляют предложения или их фрагменты. Например, пусть имеются два текстовых элемента p = «международное признание образовательных программ российских вузов» и t = «образовательные программы российских вузов нуждаются в международном признании». Обозначим множества их смысловых значений через S(p) и S(t) соответственно и для наглядности сопоставим в порядке следования в текстовом элементе р словам малые буквы латинского алфавита:
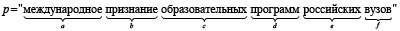 . (1)
. (1)
Тогда формульное представление функционала смысла S(р) в нотации обратной польской записи [15] имеет вид
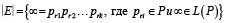 , (2)
, (2)
где 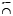 – операция контекстного уточнения смысла, а k – арность операции.
– операция контекстного уточнения смысла, а k – арность операции.
Вычислительную процедуру функционала смысла S(p) представляет семантическая схема (рис. 1).
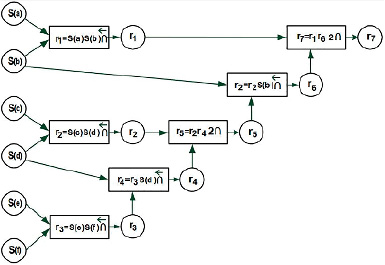
Рис. 1. Семантическая схема текстового элемента p Источник: составлено авторами по [15]
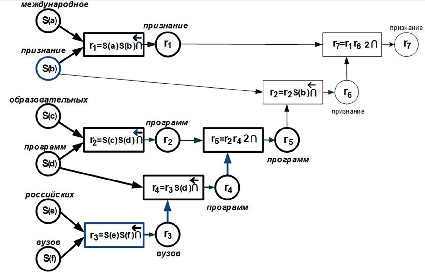
Рис. 2. Семантическая схема текстового элемента t Источник: составлено авторами по [15]
На семантической схеме самые левые круглые вершины соответствуют ее входам, прямоугольные (элементы смысла) – операциям, результаты вписаны в круглые вершины на выходах элементов смысла. Подобное формульное представление смыслового функционала можно сконструировать для текстового элемента t, оно показано на рис. 2.
В качестве меры подобия (сходства, близости) семантических значений S(p) и S(t) выбирается критерий вида
0 ≤ Сprox(S(p),S(t)) ≤ 1.
Если Сprox = 0, то семантическая близость между p и t отсутствует, при Сprox = 1 имеет место полное семантическое сходство, в иных случаях семантическая близость частичная. В силу несимметричности операции контекстного уточнения смысла имеет место утверждение
Сprox(S(p),S(t)) ≠ Сprox(S(t),S(p)).
Непосредственно критерий Сprox представляется выражением
Сprox(S(p),S(t)) = q / m, (3)
где q – число элементов смысла семантической схемы элемента p, совпадающих с элементами смысла семантической схемы элемента t, и m – общее число элементов смысла семантической схемы p. В рассматриваемом случае семантическая схема p содержит 6 слов и 7 элементов смысла (прямоугольных вершин), то есть m = 7.
На семантической схеме элемента t (рис. 2) жирными линиями выделены элементы смысла, совпадающие с элементами смысла семантической схемы элемента р (рис. 1), и число таких совпадений q = 5.
Таким образом, значение семантического подобия текстовых элементов p и t Сprox(S(p),S(t)) = 5/7 = 0,71 и достаточно высоко. Если близость определять на основе частотной модели, то она равнялась бы единице, поскольку все слова элемента p входят в элемент t. В действительности утверждение о полной семантической близости является не в полной мере истинным.
2. Семантическое подобие текстовых последовательностей, функция подобия
Пусть текстовый поток представлен последовательностью токенов T = t1t2…tm. Обозначим множество токенов, входящих в последовательность Т, через Tʹ = {t1,t2,…,tm}, и построим отображение Q = P→T таким образом, чтобы элементами отображения были пары (pi,tj), где 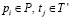 . Для каждой пары определим меру близости как Сprox(pi,tj) = w и дополним ею пару в отображении. После этого модифицированное отображение принимает вид
. Для каждой пары определим меру близости как Сprox(pi,tj) = w и дополним ею пару в отображении. После этого модифицированное отображение принимает вид
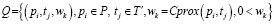 (4)
(4)
Придадим мере близости wk следующую трактовку, будем считать ее мерой присутствия характеристики pi в текстовом потоке, а токен tj = (pi,wk), являющийся ее образом в отображении, будем считать семантическим следом характеристики pi в текстовом потоке.
Пусть в языке сценариев L(P) семантического объекта имеется некоторый сценарий 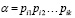 , α∈P и существует его отображение в текстовый поток вида
, α∈P и существует его отображение в текстовый поток вида 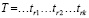 …. Если из потока Т удалить незначащие токены, обладающие нулевой степенью подобия с характеристиками, то получится некоторая последовательность токенов
…. Если из потока Т удалить незначащие токены, обладающие нулевой степенью подобия с характеристиками, то получится некоторая последовательность токенов 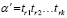 , которая представляет собой отображение сценария α на текстовый поток, будем ее считать семантическим следом данного сценария α в текстовом потоке. В дальнейшем подобное удаление незначащих токенов из текстового потока назовем его нормализацией.
, которая представляет собой отображение сценария α на текстовый поток, будем ее считать семантическим следом данного сценария α в текстовом потоке. В дальнейшем подобное удаление незначащих токенов из текстового потока назовем его нормализацией.
Для оценки семантического подобия сценария α и семантического следа αʹ сконструируем функцию подобия 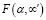 . Значения функции нормализуем на интервале
. Значения функции нормализуем на интервале 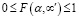 , а ее аргументами будем считать значения критериев близости характеристик и токенов, входящих в последовательности α и αʹ. С учетом данного обстоятельства функция подобия принимает вид
, а ее аргументами будем считать значения критериев близости характеристик и токенов, входящих в последовательности α и αʹ. С учетом данного обстоятельства функция подобия принимает вид
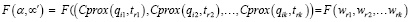 (5)
(5)
Исходя из практических целей, для F можно выбирать различные виды аппроксимаций, например учитывать значимость характеристик, их роли и места в сценарии, обеспечивая тем самым тонкую настройку функции на различные ситуации. Для общего понимания можно F принять как средневзвешенную величину вида
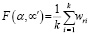 . (6)
. (6)
Как показывает практика, этого вполне достаточно во многих ситуациях. Очевидно, что значение функции подобия 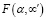 также можно считать мерой присутствия сценария α семантического объекта в текстовом потоке.
также можно считать мерой присутствия сценария α семантического объекта в текстовом потоке.
3. Поиск семантических следов в текстовом потоке
Пусть своим характеристическим множеством P и множеством сценариев L(P) задан семантический объект и имеется некоторый текстовый поток Т. Требуется установить, присутствует ли сценарий α семантического объекта в текстовом потоке Т, и оценить меру такого присутствия.
Подход к решению сводится к подбору из множества L(P) такого сценария α, семантическим следом которого в потоке T является последовательность токенов αʹ с максимальной функцией подобия 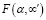 . Трудность состоит в том, что ни сценарий α, ни его семантический след αʹ заранее не известны, их требуется найти.
. Трудность состоит в том, что ни сценарий α, ни его семантический след αʹ заранее не известны, их требуется найти.
При конечном множестве сценариев L(P) решение задачи можно свести к тривиальному методу перебора, но случай бесконечного множества требует иных подходов. Первый из них лежит на поверхности и представляет собой нейросетевой подход. Однако с ним не все просто – качественное обучение нуждается в тщательно подобранных статистических данных большого объема, которых зачастую нет, само обучение также нуждается в немалом времени, и, самое главное, никакой уверенности в точности результатов на реальных входных данных нет.
Более оптимистичен и точен формально-грамматический поход. В нем множество сценариев L(P) рассматривается как язык некоей формальной грамматики G[Z], в которой Z – начальный символ, множество Р – терминальный словарь и сценарий α – предложение. Тогда процесс распознавания сценария αi сводится к построению вывода Z⇒+αi из начального символа грамматики по типу синтаксического анализа с одновременным вычислением функции подобия. Здесь под выводом ⇒+ понимается транзитивное замыкание отношения простого вывода на множестве цепочек грамматики, но для понимания вполне достаточно под ним понимать возможность вывода сценария αI из начального символа грамматики.
Сконструируем для данного подхода укрупненный алгоритм выявления семантического следа объекта. Пусть текстовый поток нормализован и представлен последовательностью токенов T = t1t2…tl и P = {p1, p2,…, pn} – характеристическое множество семантического объекта, а L(P) – множество его сценариев, являющееся языком грамматики G[Z]. Для реализации алгоритма введем вспомогательную текстовую переменную alpha, в которой будем собирать искомый сценарий семантического объекта α, начальным значением переменной положим пустую цепочку λ. Если характеристика рi использовалась при составлении сценария (катенирована с переменной alpha+рi), то она помечается меткой использования. Также введем вспомогательную переменную s, в которой будем накапливать значение близостей отдельных следов характеристик из alpha и ее начальным значением положим ноль.
Алгоритм:
1. Установить начальные значения
alpha = λ и s = 0.
2. Последовательно для каждого токена ti, i = 1, 2, …l текстового потока T = t1t2…tl:
2.1. Снять метки использования с характеристик множества P = {p1, p2,…, pn}.
2.2. Выбрать из непомеченных характеристик множества P характеристику с максимальным ненулевым значением wj = Cprox(pj,ti).
2.3. Выполнить катенацию переменной alpha с характеристикой pj вида alpha: = alpha+ pj, пометить характеристику pj как использованную.
2.4. Если вывод Z⇒+alpha существует, то переменную s увеличить s: = s+wj , иначе характеристику откатенировать alpha: = alpha – pj, перейти к п. 2.2 алгоритма.
3. Если |alpha|≠0, то вычислить функцию подобия F = s/|alpha|, где |alpha| – длина собранного в переменной alpha сценария.
В результате выполнения алгоритма в переменной alpha будет собран сценарий семантического объекта и вычислена степень его присутствия в текстовом потоке.
Следует отметить, что п. 2.4 алгоритма задает так называемый бектрекинг– откат на шаг назад, когда не найден вывод части сценария, собранного в переменной alpha. В этом случае выбранная характеристика отбрасывается и выполняется выбор новой из непомеченных характеристик множества P.
Формально-грамматический подход обладает хорошими точностными характеристиками и не требует обучения. Для его реализации необходима только формальная модель семантического объекта, которая при необходимости может быть уточнена. Однако трудоемкость алгоритма сильно зависит от вида выбранной формальной грамматики, которая задает процедуру вывода Z⇒+alpha [16, с. 202–339]. Вопрос подбора формальной грамматики для поиска быстрых решений требует отдельного обсуждения.
Формально-грамматический подход существенно упрощается и ускоряется, когда множество L(P) является регулярным. Тогда грамматику можно представить регулярным выражением, значением которого будет множество L(P), а вывод Z⇒+alpha свести к последовательному разбору сценариев конечным распознавателем. Анализ естественно-языковых потоков показывает, что этот случай типичен на практике. Рассмотрим его.
Регулярное выражение представляет собой формулу алгебры, которая определяется аксиоматически через операции “|” – ИЛИ, “*” – катенации и “{}” – итерации следующим образом:
1. ∅ (пустое множество), λ (пустая цепочка) и имена лингвистических характеристик p1, p2,…, pn – регулярные выражения по определению (аксиома, основание).
2. Если e1 и e2 – регулярные выражения, то e1 | e2 и e1 * e2 – также регулярные выражения. Обычно в регулярных выражениях знак операции * опускают и не используют.
3. Если e – регулярное выражение, то {e} – также регулярное выражение.
4. Других регулярных выражений нет.
Значением регулярного выражения E является множество последовательностей символов (характеристик) из P, обозначаемое как |E|:
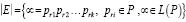 .(7)
.(7)
Конечный распознаватель для последовательностей |E| представляется системой переходов. Ее диаграмма состояний имеет одно начальное состояние S, одно заключительное состояние Z, которые соединены обобщенной дугой Е. Дуге E придается следующий смысл – любая цепочка αi ∈ L(P) переводит распознаватель из состояния S в состояние Z. При конструировании распознавателя систему переходов путем декомпозиции (разложения формулы Е на подформулы) приводят к виду, когда дуги представляются характеристиками pi и пустой цепочкой λ, такую систему переходов называют приведенной. Разбор сценария αi ∈ L(P) приведенной системой переходов происходит последовательно по образующим его характеристикам, что эквивалентно поиску пути из начального состояния S в конечное состояние Z. В работе [17, с. 124–162] рассмотрены теоретические основы конструирования конечных автоматов подобного рода.
Модифицируем описанный выше алгоритм выявления семантического объекта с учетом регулярности языка сценариев L(P). Пусть нормализованный текстовый поток представлен последовательностью токенов T = t1t2…tl, P = {p1, p2,…, pn} – характеристическое множество семантического объекта, L(P) – множество его сценариев и распознаватель сценариев представлен приведенной системой переходов, для которой множество Q – множество состояний распознавателя. Функции текстовой переменной alpha и переменной s остаются без изменений. Введем дополнительно стек состояний St, в котором будут накапливаться состояния распознавателя из Q, входящие в найденный путь, и определим для него операции ← (втолкнуть) и → (вытолкнуть). Для распознавателя также определим функцию переходов вида qt = М(q,pi), которая по текущему состоянию qj, и характеристике pi системы переходов определяет новое состояние qt. Текущее состояние распознавателя будем сохранять во вспомогательной переменной q.
Алгоритм:
1. Положить начальные значения
alpha = λ, s = 0, St = St ← S.
2. Выполнять последовательно для каждого токена ti, i = 1, 2, …l текстового потока T = t1t2…tl пока Sk ≠ Z:
2.1. Снять метки использования с характеристик множества P = {p1, p2,…, pn}.
2.2. Выбрать из непомеченных характеристик множества P характеристику pj с максимальным и ненулевым значением wj = Cprox(pj,ti) и пометить характеристику pj как использованную.
2.3. IF переход q = M(St, pj) существует
THEN
begin
2.3.1. St : = St ← q;
2.3.2. Выполнить катенацию переменной alpha с характеристикой pj вида alpha: = alpha+pj ;
2.3.3. увеличить переменную s: = s+wi;
2.3.4. 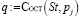
end
ELSE перейти к п. 2.2.
Вычислить функцию подобия F = s/|alpha|.
Отметим, что данный алгоритм работает намного быстрее, поскольку разбор сценария сводится к вычислению функции переходов. Основную трудоемкость алгоритма определяет только трудоемкость вычисления семантических близостей характеристик и токенов.
Предложенный формальный подход реализован в разработанном программном комплексе, включающем подсистему подготовки текстовых потоков, обеспечивающую их форматирование и токенизацию, подсистему создания и редактирования семантических объектов, подсистему поиска и выявления семантических следов объектов и подсистему сравнения токенов на семантическую близость.
Подсистема подготовки обеспечивает приведение к единому формату текстовых потоков от различных источников и их токенизацию. Подсистема создания и редактирования семантических объектов в полуавтоматическом режиме позволяет анализировать представленные внешние неформализованные исходные данные о семантическом объекте, в которых отражены характерные черты и особенности поведения семантических объектов, и создавать по ним их формальные описания (характеристические множества, регулярные выражения и системы переходов). Формальные описания заносятся в базу данных семантических объектов, из которой передаются в другие подсистемы в формате JSON файлов. Подсистемы семантического сравнения токенов и выявления семантических следов семантических объектов реализуют основной функционал комплекса и обеспечивают поиск и идентификацию семантических следов в текстовых потоках, включая определение степени доверия к результатам.
Для тестирования программного комплекса и проведения экспериментов была разработана следующая реалистично подобная схема. Некий субъект К, обладая информацией о нерешенных проблемах некоего Ж и преследуя собственную цель, вступил с ним в чат-диалог. В процессе диалога К завоевывал доверие Ж, проявляя сочувствие к его проблемам, вовлекал в игровой тренинг, предлагая помощь, и на завершающем этапе требовал неукоснительного выполнения всех указаний. Диалог адаптировался под конкретную ситуацию и мог происходить по различным сценариям.
В данной схеме К моделировался семантическим объектом, чат соответствовал текстовому потоку. Программный комплекс по семантическим следам идентифицировал объект и оценивал степень его присутствия в потоке. В ходе экспериментов изучалось влияние точности описания семантического объекта на качество распознавания: описание уточнялось за счет добавления новых характеристик и расширения языка сценариев. Результаты показали, что точность идентификации росла с повышением детализации описания, однако после достижения определенного порога дальнейшее уточнение не приводило к значимому улучшению. Для повышения достоверности результатов генерировались разнородные диалоговые потоки, и исследования подтвердили, что точность идентификации не зависела ни от размера потока, ни от его вида. Дополнительно результаты идентификации и исходные данные оценивались экспертной группой, чьи выводы согласовывались с полученными данными. Результаты тестовых испытаний показали работоспособность программного комплекса и подтвердили основные теоретические положения исследования.
Результаты исследования и их обсуждение
Основной результат исследования состоит в разработке нового формального подхода к выявлению текстов определенной семантической направленности по описаниям их источников. Для этого вербальное понятие «определенная семантическая направленность» моделируется множеством сценариев языка формальной грамматики некоторого гипотетического семантического объекта, сценарии представляются последовательностями характеристик семантического словаря, а направленность текста определяет семантическая близость сценарию. Трудность реализации подхода кроется в бесконечной множественности сценариев, а также в отсутствии информации о семантической направленности исходного текста. В таких условиях простой перебор невозможен и предложено предполагаемый сценарий конструировать.
Процесс конструирования организуется последовательным определением семантического сходства токенов текста характеристикам и их сборкой в последовательность, которая путем построения вывода в формальной грамматике, называемым разбором, проверяется на принадлежность языку сценариев. При положительном исходе разбора сценарий построен.
Степень семантического сходства текста и сценария определяется значением специально сконструированной функции семантического подобия.
Для реализации подхода разработаны общий и частный алгоритмы выявления текстов определенной семантической направленности. В общем алгоритме разбор сводится к построению вывода в формальной грамматике, для регулярных грамматик разбор выполняется системой переходов. Ускорение процесса достигается путем совмещения сборки сценария с грамматическим разбором, а также использованием механизма бэк-трекинга. Отличительная особенность состоит в том, что точность алгоритмов определяется только фактической близостью текстов сценариев.
Заключение
Новые задачи, поставленные практикой естественно-языковой обработки, в основе которых лежит выявление текстов определенной семантической направленности по формальному описанию их источников, потребовали разработки нового теоретического инструментария – методов, моделей и эффективных алгоритмов и программных реализаций. В предлагаемой работе такой подход разработан на основе положений вычислительной теории семантической интерпретации и теории формальных грамматик. В нем использованы понятия вычислительной теории семантической интерпретации – семантическое сравнение, критерий семантической близости. Отличительная черта предлагаемого подхода состоит в том, что его точность определяется вычисляемой степенью фактической семантической близости сценариев и текстов. Поход не требует процедур обучения, как это имеет место в нейросетевом подходе. Следует отметить, что особенности разработки программ и результаты экспериментов в работе упомянуты кратко, поскольку данный вопрос требует отдельного обсуждения.
Работа направлена на развитие фундаментальных основ математического моделирования фундаментальных и прикладных проблем естественно-языковой обработки для создания эффективных вычислительных алгоритмов виде комплексов проблемно-ориентированных программ на основе современного компьютерного инструментария.
Финансирование
Библиографическая ссылка
Вишняков Ю.М., Вишняков Р.Ю. ПОИСК И ИДЕНТИФИКАЦИЯ ТЕКСТОВ ОПРЕДЕЛЕННОЙ СЕМАНТИЧЕСКОЙ НАПРАВЛЕННОСТИ В ЕСТЕСТВЕННО-ЯЗЫКОВЫХ ПОТОКАХ // Современные наукоемкие технологии. 2025. № 5. С. 32-40;URL: https://top-technologies.ru/ru/article/view?id=40387 (дата обращения: 21.06.2026).
DOI: https://doi.org/10.17513/snt.40387