



Введение
Бурное развитие технологий обработки данных и широкое распространение облачных вычислений привели к активному внедрению систем искусственного интеллекта в различные сферы деятельности от промышленного производства до образования и медицины. Интеллектуальные модули, реализующие функции классификации, распознавания образов, прогнозирования, становятся неотъемлемой частью современных программных систем. Однако их практическое использование требует эффективной интеграции с другими компонентами программной архитектуры, включая хранилища данных, интерфейсы прикладного программирования и модули принятия решений. На сегодняшний день отсутствует единый общепринятый подход к интеграции систем искусственного интеллекта в распределённые программные комплексы, особенно в условиях гетерогенной программной среды и высокой степени распределённости компонентов. Это приводит к необходимости разработки собственных промежуточных решений, обеспечивающих связность между интеллектуальными подсистемами и остальной инфраструктурой.
Интеграция систем искусственного интеллекта (ИИ) в существующие архитектуры программного обеспечения представляет собой ряд технических проблем, особенно при работе с распределёнными средами и разнообразными компонентами системы. Например, типичным сценарием, при котором возникает необходимость в интеграции интеллектуальных моделей, является добавление ранее разработанной функциональности, основанной на модели искусственного интеллекта, в новую функциональность, написанную совершенно на другом стеке технологий. На практике, примером такой задачи может быть такая ситуация, когда модель рекомендаций, обученная в PyTorch, должна быть интегрирована в платформу электронной коммерции на базе Java с использованием REST API и последовательной сериализации данных. Поэтому одним из основных препятствий в этой области является проблема совместимости данных между гетерогенными системами. Существующая инфраструктура часто использует разные форматы данных, структуры и методологии хранения, которые должны быть согласованы с моделями искусственного интеллекта, что подтверждается рядом работ. Так авторами S. Sinha и Y.M. Lee подчёркивается проблематика интеграции искусственного интеллекта в существующую инфраструктуру, включая необходимость гармонизации различных форматов данных и структур хранения [1]. В работе P.M.A. van Ooijen и соавторов рассмотрены технические аспекты построения ИИ-пайплайнов, включая вопросы хранения данных, использования облачных инфраструктур и структурирования процессов обработки [2]. Авторы подчёркивают важность чёткого проектирования ИИ-конвейеров и отмечают, что в распределённых условиях высокая степень связности между компонентами может стать узким местом при масштабировании. Однако представленный ими подход ориентирован преимущественно на линейные сценарии исполнения и не предусматривает явного механизма абстрагирования задач от конкретных моделей.
Проблема интеграции становится особенно острой, когда организациям необходимо подключить несколько источников данных. Так в последних исследованиях и опросах, проведённых компанией Tray.ai показано, что примерно около 42% предприятий нуждаются в доступе к восьми или более источникам данных для успешного развёртывания агентов искусственного интеллекта. В работе M. Zhao и соавторов рассмотрен вопрос реализации конвейера хранения и обработки данных, состоящего из центрального хранилища данных, построенного на распределенном хранении, который позволяет сотням моделям обучаться совместно через территориально-распределённые дата-центры [3]. В рамках необходимости соблюдения стандартов представления данных, возникают сложности с тем, что многие организации работают с устаревшими системами, построенными на устаревших технологических стеках, языках программирования или операционных системах, которые несовместимы с современными фреймворками и инструментами в области искусственного интеллекта. Это несоответствие между устоявшейся инфраструктурой и передовыми приложениями систем искусственного интеллекта добавляет значительную сложность интеграции
Но помимо проблемы совместимости данных между системами, существенным препятствием к интеграции является также качество самих данных. Как известно, модели искусственного интеллекта в значительной степени зависят от высококачественных данных для процессов обучения и формирования вывода и основными сложностями в данной части являются несоответствия, неточности и пропущенные значения в наборах данных, что может существенно снизить производительность систем, основанных на искусственном интеллекте [4,5]. Поэтому при решении проблемы интеграции должны быть учтены и разработаны соответствующие политики управления данными и реализованы общие протоколы очистки данных, для того чтобы гарантировать целостность информации, поступающей в системы [6].
Таким образом, можно констатировать, что существенным препятствием для интеграции систем искусственного интеллекта является отсутствие общепринятых стандартов интеграции, что приводит к непоследовательным подходам в организациях, даже даже в пределах одного предприятия или даже проекта. Без общих стандартов организации должны разрабатывать собственные подходы, что часто приводит к потенциальным пробелам в реализации, что говорит об актуальности данной задачи.
Цель исследования – разработка контекстно-ориентированной архитектуры интеграции систем искусственного интеллекта, направленной на снижение сложности сопряжения интеллектуальных модулей с прикладной логикой распределённых программных систем. В основе предлагаемого подхода лежит использование промежуточного слоя абстрактных операторов и стандартизированных механизмов отображения задач на модели, независимых от конкретных поставщиков решений.
Материалы и методы исследования
Исследование выполнено в форме теоретико-прикладного анализа существующих подходов к интеграции систем искусственного интеллекта. В качестве материала использованы архитектурные схемы микросервисных систем, документы форматов YAML/JSON, описания моделей различной природы (языковые, визуальные и др.). Методологической основой послужили принципы декомпозиции, архитектурного моделирования и абстракции, а также положения, изложенные в работах из списка литературы.
Архитектуру и механизмы отображения задач в модели планируется реализуются в рамках модульного фреймворка, использующего стек технологий REST/gRPC, а также унифицированные контракты взаимодействия на основе JSON Schema и Protocol Buffers. В качестве целевой платформы рассматривается реализация на языке Python с использованием библиотек FastAPI, Pydantic и Docker-контейнеризации для изоляции моделей. Особое внимание уделяется возможности масштабирования и повторного использования операторных блоков при формировании задач в виде графов обработки.
Результаты исследования и их обсуждение
Прежде чем перейдём к рассмотрению решения обозначенной выше проблемы, сформулируем и формализуем задачу интеграции систем искусственного интеллекта. Пусть имеется множество моделей искусственного интеллекта, которые могут описаны как 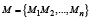 , а также множество типов задач (или прикладных целей использования моделей)
, а также множество типов задач (или прикладных целей использования моделей) 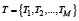 . Каждая модель из множества М реализует отображение вида
. Каждая модель из множества М реализует отображение вида
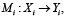 (1)
(1)
где Xᵢ – множество допустимых входных данных (изображения, текст, аудио),
Yᵢ – множество возможных выходных данных (текст, классы, эмбеддинги и т.д.).
А каждая задача из множества T, в свою очередь, требует выполнения некоторого преобразования вида
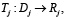 (2)
(2)
где Dj – множество исходных данных задачи,
Rj – множество желаемых результатов.
Следовательно, для того чтобы модель Mᵢ могла участвовать в решении задачи Tj, необходимо определить связку между моделью и задачей. Это связь и будет являться интеграцией модели в новую задачу. Все возможные такие связки (пары Mᵢ и Tj) можно представить как отношение интеграции, которое можно записать в виде
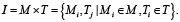 (3)
(3)
Каждая модель Mi представляется как расширенный конечный автомат, который может быть описан кортежем
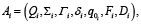 (4)
(4)
где Qi – множество состояний
Σi – входной алфавит (события, запросы)
Гi – выходной алфавит
δi – функция перехода в зависимости от входа Di
q0i – начальное состояние автомата (выполнение модели)
Fi – множество конечных состояний
Di – набор внутренних переменных (память, флаги, контекст и т.д.).
Тогда для каждой задачи Tj и модели Mᵢ, логика перехода δi должна включать индивидуальные правила, определённые как
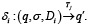
Таким образом модель должна иметь в своей логике переходов δi отдельные правила для каждой задачи Tⱼ. В свою очередь, для каждой пары отображения (Mᵢ,Tj), чтобы осуществить взаимодействие, также необходимо определить композицию преобразований вида
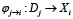 , (5)
, (5)
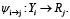 (6)
(6)
Таким образом, полная интеграция пары требует создания отображения
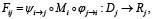 (7)
(7)
Формула (7) описывает, как задача из пространства Dj (данные задачи j) преобразуется в результат Rj (ожидаемый формат результата для задачи j) с помощью модели Mᵢ, предназначенной для решения задач другого типа. Так как модель Mi напрямую не совместима с форматом задачи j, то используются два дополнительных преобразования, а именно транслятор φ и интерпретатор ψ. Иными словами, сначала к данным d ∈ Dj применяется транслятор φ, с целью преобразования входа задачи в формат, понятный модели, далее результат подаётся на вход модели Mi , после чего результат модели интерпретируется соответствующим интерпретатором, то есть происходит преобразование результата модели в формат, ожидаемый задачей. Таким образом, одна универсальная модель может применяться к задачам разных типов с помощью обёрток-преобразователей, тем самым определена прямая интеграция каждой модели с каждой задачей. Однако такая прямая интеграция модели Mi с задачей Tj требует, чтобы либо сама модель изначально была обучена на задаче данного типа, либо чтобы внешние преобразования ψi→j и φj→i были достаточно сложны, чтобы компенсировать отсутствие у модели знаний о специфике задачи. Это означает, что в случае, если модель Mi не была заранее обучена учитывать особенности задачи, то все требования к адаптации полностью ложатся на внешнюю инфраструктуру интеграции, что в обязательном порядке требуется учитывать при реализации систем и протоколов интеграции систем искусственного интеллекта. Особенно это критично при повторном использовании одной и той же модели Mi в новой задаче Tj+1, с которой она ранее не взаимодействовала. Здесь же стоит отметить, что в данной работе, по умолчанию предполагается, что интеграция всегда требует явных адаптационных преобразований. В частном случае, если модель Mi изначально была обучена на задаче Tj , и входные и выходные форматы полностью совпадают с требованиями задачи, отображения 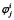 и
и 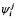 могут быть реализованы как тождественные функции. В этом случае интеграция упрощается до прямого вызова модели, то есть Fij = Mi.
могут быть реализованы как тождественные функции. В этом случае интеграция упрощается до прямого вызова модели, то есть Fij = Mi.
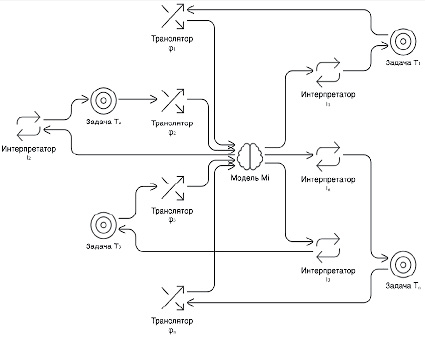
Рис. 1. Интеграция универсальной модели ИИ с множеством задач через индивидуальные преобразователи Источник: составлен автором
На рисунке 1 показана схема использования модели Mi для новых классов задач при описанном выше подходе к интеграции.
Даже если сама модель остаётся неизменной, для корректного включения её в новую прикладную цель, фактически, необходимо спроектировать новую пару транслятор-интерпретатор, что при большом количестве используемых моделей усложняет систему. Таким образом, возникает необходимость в архитектурных подходах и протоколах, которые могли бы централизованно управлять взаимодействием моделей.
В последние годы разработано множество таких решений. Одним из наиболее распространённых подходов к интеграции компонентов в системах искусственного интеллекта является использование микросервисной архитектуры, в которой каждая модель развёртывается как отдельный сервис с внешним API, а задачи реализуются как отдельные оркестраторы, направляющие данные в нужные компоненты, посредством использования таких протоколов и архитектурных стилей, как, например, REST (HTTP/JSON) или gRPC (Protocol Buffers). В самой простой реализации такого подхода каждая модель Mi обёрнута в микросервис с endpoint POST /predict, который на вход принимает сериализованные данные, а каждая задача Tj реализует собственный клиент, который формирует запросы к нужным микросервисам. Каждый клиент реализует прикладную логику задачи Tj , связанную со сбором и преобразованием исходных данных, а также выбором нужных моделей и дальнейшей агрегацией результатов в единое решение, таким образом, обеспечивается оркестрация и выполнение прикладного сценария. Благодаря такому подходу, в рамках одного вызова задача может последовательно активировать несколько моделей. Типичный цикл обработки прикладной задачи с поступления HTTP запроса на вход оркестратора, который анализирует полученные данные и определяет необходимую последовательность действий, вызывая соответствующую модель. Если для выполнения текущего шага требуется дополнительная модель, то задача формирует запрос к сервису модели Mi. После получения запроса сервис модели выполняет преобразование данных во внутренний формат, запускает выполнение и получает ответ, содержащий результат выполнения и дополнительную информацию. Данный ответ возвращается задаче в виде JSON формата или protobuf-сообщения. Важно отметить, что здесь могут использоваться дополнительные промежуточные слои, отвечающие за трансформацию входных и выходных данных, а также согласования форматов между задачей и моделью. Эти компоненты являются реализацией адаптационных отображений ψi→j и φj→i, которые были описаны выше. После всех этих действий, оркестратор задачи принимает результат, выполняет его постобработку и решает, завершена ли задача или требуются дополнительные шаги. На рисунке 2 показана возможная схема реализации данного подхода.
Несмотря на то, что архитектура, показанная на рисунке 2, является модульной и обладает требуемым уровнем прозрачности, такое решение остаётся жёстко связанным, нарушая принцип низкой связанности и высокого зацепления (англ. low coupling – high cohesion) [7]. Это проявляется в том, что для каждой задачи необходимо явно указывать, какие модели вызывать, в каком порядке, с какими параметрами, и как обрабатывать результат, а чтобы интегрировать все возможные взаимодействия между Mi и Tj, необходимо реализовать S = M × N уникальных интерфейсов, сохраняя при этом локальные контексты внутри каждой модели. Тогда трудоёмкость одной интеграции модели может быть определена как
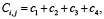 (8)
(8)
где c1 – реализация маршрута вызова,
c2 – преобразование входа (φj→i),
c3 – интерпретация выхода (ψi→j),
c4 – логика ошибок, логгирование, тестирование и прочее.
А общая трудоёмкость для всей системы может быть рассчитана, как
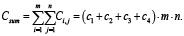 (9)
(9)
На рисунке 3 показана тепловая карта роста сложности системы (количество точек интеграции) по формуле второго порядка S(m,n) = O(mn), полученная с использованием языка Python и Jupyter Notebook.
Как видно из рисунка 3 уже при, например, 5 моделях и 4 задачах необходимо реализовать 20 связей, что на практике будет приводить к возникновению дублированного кода в реализации, а при 20 моделях и 15 задачах необходимо реализовать 300 связей, что приводит к значительной сложности такого решения, которое проявляется в том, что необходимо реализовать и поддерживать большое количество маршрутов, адаптеров, обработчиков ошибок и прочей функциональности, а при попытке добавления новой модели или задачи нужно модифицировать десятки компонентов.
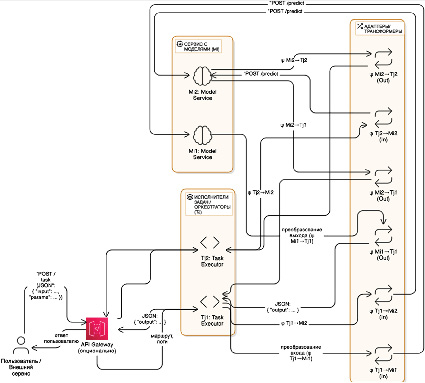
Рис. 2. Микросервисная архитектура с RPC-интеграцией моделей искусственного интеллекта с задачами Источник: составлен автором
Для решения данной проблемы можно в существующую архитектуру добавить дополнительный слой операторов, по некоторой аналогии, как предложено в работах [8-10], которые будут поддерживать стандартные операции. То есть, вместо прямой интеграции вида «модель – задача», можно разделить взаимодействие на уровень реализации базовых операций [11], которые реализуют модели и уровень описания задачи, как последовательность операторов. Для этого необходимо усложнить описанную выше модель путём определения множества абстрактных операторов 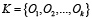 , реализующих набор стандартных операций вида «генерация текста», «эмоциональный анализ», «извлечение сущностей», «поиск», «ответ на вопрос», «перевод» и т.д. Тогда каждая модель Mi реализует один или несколько операторов из K, то есть
, реализующих набор стандартных операций вида «генерация текста», «эмоциональный анализ», «извлечение сущностей», «поиск», «ответ на вопрос», «перевод» и т.д. Тогда каждая модель Mi реализует один или несколько операторов из K, то есть 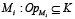 . Тогда задача Tj может быть определена как композиция операторов
. Тогда задача Tj может быть определена как композиция операторов
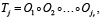 (10)
(10)
где 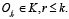
При таком подходе любая задача становится простым потоком исполнения операторов, не привязанных к конкретным моделям. Для каждого оператора 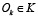 существует отображение
существует отображение 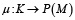 такое, что
такое, что 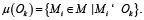 Это множество моделей, реализующих соответствующую операцию. В таком случае для исполнения задачи необходимо выбрать конкретную модель (
Это множество моделей, реализующих соответствующую операцию. В таком случае для исполнения задачи необходимо выбрать конкретную модель (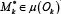 ) , которая будет вызвана при выполнении соответствующего шага пайплайна. Чтобы формализовать этот выбор, вводится функция σ, сопоставляющая паре (оператор, контекст задачи) конкретную модель
) , которая будет вызвана при выполнении соответствующего шага пайплайна. Чтобы формализовать этот выбор, вводится функция σ, сопоставляющая паре (оператор, контекст задачи) конкретную модель
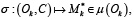 (11)
(11)
где C – это контекст исполнения задачи.
Полная интеграция задачи Tj теперь выглядит как композиция
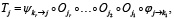 (12)
(12)
где 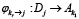 – преобразование входа задачи в формат первого оператора,
– преобразование входа задачи в формат первого оператора,
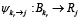 – интерпретация результата последнего оператора под формат задачи.
– интерпретация результата последнего оператора под формат задачи.
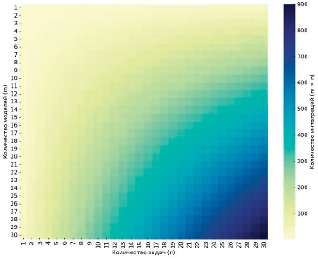
Рис. 3. Рост количества интеграций при фиксированном числе задач Источник: составлен автором
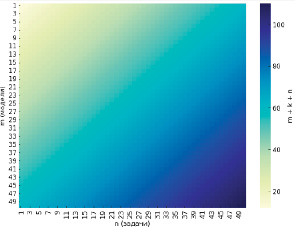
Рис. 4. Сложность интеграции при использовании операторного слоя Источник: составлен автором
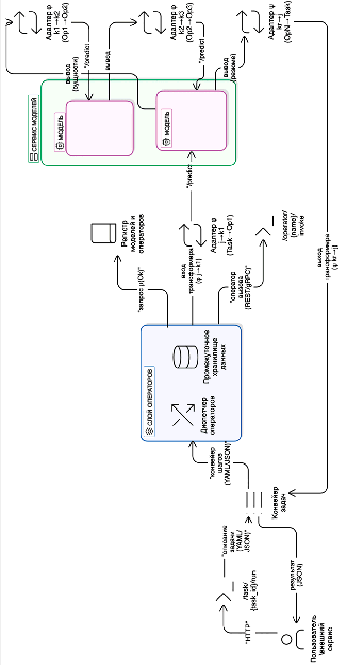
Рис. 5. Архитектура системы интеграции моделей ИИ с промежуточным слоем абстрактных операторов (составлен автором)
Тогда итоговая сложность для способа интеграции моделей искусственного интеллекта с использованием микросервисной архитектуры и дополнительного слоя операторов определяется как O(m+k+n) где 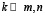 , что приводит к тому, что количество необходимых интеграций в системе растёт линейно по числу моделей, задач и операторов, так как множество операторов относительно стабильно и компактно. То есть, если даже количество моделей m=200, а задач n=300, набор таких базовых операций останется равным (примерно) 10-20. На рисунке 4 показана сложность интеграции при использовании операторного слоя, полученная с использованием языка Python и Jupyter Notebook.
, что приводит к тому, что количество необходимых интеграций в системе растёт линейно по числу моделей, задач и операторов, так как множество операторов относительно стабильно и компактно. То есть, если даже количество моделей m=200, а задач n=300, набор таких базовых операций останется равным (примерно) 10-20. На рисунке 4 показана сложность интеграции при использовании операторного слоя, полученная с использованием языка Python и Jupyter Notebook.
С технической стороны вопроса, реализация такого подхода может быть произведена за счёт введения дополнительных архитектурных компонентов, как показано на рисунке 5.
Как видно из рисунка 5, пользователь или внешняя система инициирует выполнение задачи через HTTP-запрос к API системы (/task/{task_id}/run). В запросе передаётся описание задачи в виде сценария обработки (pipeline), выраженного, например, в формате YAML или JSON. На рисунке 6 показан возможный формат задачи на языке yaml.
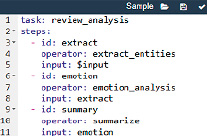
Рис. 6. Декларативное описание задачи Источник: составлен автором
Хотя в декларативном описании задачи отображения 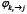 и
и 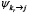 не указываются явно, они реализуются в интеграционном слое системы. Система выполняет проверку согласования типов вида
не указываются явно, они реализуются в интеграционном слое системы. Система выполняет проверку согласования типов вида 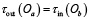 и если типы не согласуются, пайплайн считается некорректным. Такой формат превращает задачу в граф исполнения операторов, а не в просто в набор шагов, что позволяет системе динамически подставить модели, реализующие каждый оператор и как видно из рисунка 6 пайплайн не содержит указаний на конкретные модели. Тогда направленный ациклический граф операторов может быть представлен, как
и если типы не согласуются, пайплайн считается некорректным. Такой формат превращает задачу в граф исполнения операторов, а не в просто в набор шагов, что позволяет системе динамически подставить модели, реализующие каждый оператор и как видно из рисунка 6 пайплайн не содержит указаний на конкретные модели. Тогда направленный ациклический граф операторов может быть представлен, как
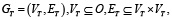 (13)
(13)
в котором узлы будут являться операторами, а рёбра графа задают порядок исполнения операций. При этом формальное условие согласования типов, для любого корректного графа GT, будет представлено как
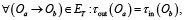 (14)
(14)
что позволяет реализовать механизм валидации декларативного описания задачи.
Далее задача поступает на вход центрального исполнительного компонента системы, в котором реализован компонент «Диспетчер операторов», который отвечает за управление выполнением задач и распределением вызовов операторов, и временное хранилище данных между шагами пайплайна. То есть, он анализирует пайплайн и вызывает нужные модели по операторам, используя адаптеры. Именно компонент «Диспетчер операторов» отвечает за формирование функционального графа исполнения GM по описанному задачей операторному графу GT. Каждому оператору Oi ∈ VT диспетчер сопоставляет множество допустимых моделей 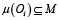 , где каждая модель реализует соответствующий оператор. Из этого множества выбирается конкретная модель
, где каждая модель реализует соответствующий оператор. Из этого множества выбирается конкретная модель 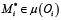 , исходя из требуемого контекста, как описано в (11) и дополнительных эвристик, например производительности модели на текущей момент времени, в случае дублирования моделей. Таким образом, формируется граф исполнения моделей (механизм роутинга)
, исходя из требуемого контекста, как описано в (11) и дополнительных эвристик, например производительности модели на текущей момент времени, в случае дублирования моделей. Таким образом, формируется граф исполнения моделей (механизм роутинга)
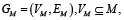 такое что
такое что
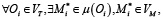 (15)
(15)
а структура рёбер графа согласована с операторным графом
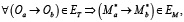 (16)
(16)
что позволяет выбирать конкретные реализации операторов на этапе исполнения.
Формат возможного запроса к модели, на примере автоматического мультимодального анализ пользовательского фотоотзыва, показан на рисунке 7.
Данный слой также связан с реестром моделей.
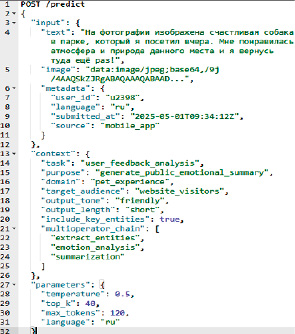
Рис. 7. Пример запроса к модели Источник: составлен автором
На основании запроса вида μ(Ok), диспетчер получает список всех моделей, реализующих указанный оператор, что позволяет динамически маршрутизировать вызовы моделей без жёсткой привязки задач к моделям. Далее слой адаптеров обеспечивают преобразование входа задачи к формату всех операторов из пайплайна задачи, а результат последнего оператора интерпретируют в формат, пригодный для возврата пользователю.
Данная архитектура обеспечивает слабую связность за счёт того, что благодаря введению абстрактного слоя операторов, новые задачи могут быть собраны как сценарии без модификации существующих моделей, а новые модели, в свою очередь, могут подключаться без пересборки задач.
Подход к интеграции моделей искусственного интеллекта с использованием дополнительных слоёв абстракции или схожих механизмов, набирает всё большую популярность на практике. Так, GitLab, в рамках проекта AI Abstraction Layer, ведёт работы по созданию унифицированной архитектуры для интеграции и управления AI/ML-функциями для своей платформы. Согласно официальной документации проекта, абстрактный слой функционирует как промежуточный слой между интерфейсами GitLab (веб-интерфейс, IDE, API) и различными AI-провайдерами. Для этого взаимодействия предлагается использовать расширяемый GraphQL API. Однако данное решение находится ещё на стадии концепции и конечный вид данной технологии ещё не определён. Возможно, что данное решение, пока что, опирается на более технически фиксированный маршрут вызова AI-функций (через aiAction), по сравнению с предложенным выше решением. Помимо этого, уже появились инструменты, такие как TensorFlow Serving, TorchServe и т.д., которые представляют собой системы сервинга моделей [12]. Данные инструменты обеспечивают интеграцию на уровне вынесения модели в отдельный сервис, что позволяет вызывать конкретную модель по её API-эндпоинту [13]. Каждая задача знает, какую именно модель (или сервис) ей вызвать для получения результата, и формирует запросы под требования этой модели. Однако данное решение обладает существенным недостатком, а именно, чтобы переключить задачу на другую модель, нужно изменить её конфигурацию или код вызова. Появились и более сложные системы инструменты оркестровки для моделей искусственного интеллекта [14], такие как Seldon, KServe, BentoML и т.д., которые позволяют выстраивать более сложные пайплайны обработки. Все эти инструменты упрощают процесс развёртывания и позволяют разворачивать модели как Kubernetes-сервисы, автоматически предоставляя им соответствующие endpoint, но проблема маршрутизации между множеством моделей и задач этими средствами не решается в полном объёме. В предложенном же решении контекстно-ориентированность и динамический выбор модели позволяют устранить данный недостаток.
В современных публикациях подчёркивается, что микросервисный подход хорошо сочетается с требованиями ИИ-систем к масштабированию и обновляемости моделей. Однако одной лишь декомпозиции на сервисы будет недостаточно для решения всех проблем интеграции, поэтому необходимы дополнительные уровни абстракции или стандарты взаимодействия. Предложенный в работе подход по реализации контекстно-ориентированного шлюза с абстрактным слоем операторов позволяет решить эти задачи и уйти от жёсткой привязанности когда, например, путь /vision/modelA вызывает модель A, а путь /nlp/modelB вызывает модель B. Предложенный в работе способ описывать задачу в виде графа операций (операторного графа), а не привязывать её жёстко к одной модели, позволяет в дальнейшем использовать контекстно-ориентированную маршрутизацию, чтобы при выборе того, как обработать запрос, система учитывала дополнительный контекст поставленной задачи. Но для успешной работы модели контекстно-ориентированной маршрутизации необходимо, чтобы множество операторов, составляющих абстрактный слой, было достаточно стабильным и стандартизированным. В предложенной текущей итерации реализации отсутствует единый словарь операций, общепринятый протокол или какой-то иной механизм описывающий допустимые типы входов, выходов и контекстов. Это может приводить к тому, что при росте числа задач и моделей система может столкнуться с тем, что каждая новая задача требует уникального набора операторов. На практике это означает, что мощность множества операторов К может увеличиваться до размеров сопоставимых с количеством задач и моделей, а сама сложность интеграции при использовании операторного слоя при таких условиях уже не будет демонстрировать умеренный линейный рост сложности.
В связи с этим, в дальнейших работах планируется разработать механизм стандартизации описания операторов, включая формальную спецификацию типов, контекстов и семантики операций. Для этих целей предполагается использовать открытый стандарт Model Context Protocol (протокол контекста модели) [15], разработанный в декабре 2024 года компанией Anthropic и поддержанный многими крупными технологическими компаниями. Использование данного решения позволит стандартизировать интерфейс взаимодействия с моделями таким образом, чтобы контекст задачи передавался модели, позволяя ей адаптировать своё поведение. В текущей итерации это уже частично реализуется через отображение μ и абстрактные операторы, но в случае использования протокола MCP все модели будут объединены под единым интерфейсом, что должно также понизить сложность интеграции.
Заключение
Проведённое исследование позволило разработать контекстно-ориентированную архитектуру интеграции систем искусственного интеллекта с использованием промежуточного слоя абстрактных операторов, ориентированную на снижение сложности сопряжения интеллектуальных модулей с прикладной логикой распределённых программных систем. В рамках работы разработана также архитектура программного шлюза, поддерживающего контекстно-ориентированное взаимодействие и декомпозицию задач на абстрактные операторы, что обеспечило отделение описания задачи от конкретных реализаций моделей. Показано, что использование операционного слоя позволяет перейти от жёсткой маршрутизации запросов к более гибкой модели динамического связывания, в которой выбор модели осуществляется с учётом контекста задачи и текущих условий исполнения. Предложенное решение ориентировано на микросервисную среду и применимо для решения задачи интеграции разрозненных систем искусственного интеллекта. Также в работе выявлены ограничения, связанные с отсутствием стандартизации операторного слоя, что в перспективе может повлиять на масштабируемость подхода, а именно повышение уровня сложности интеграции. Для решения данной задачи предполагается формализировать операционные онтологии, что можно реализовать за счёт использования нового перспективного протокола Model Context Protocol.
Библиографическая ссылка
Алпатов А.Н. Контекстно-ориентированная архитектура интеграции систем искусственного интеллекта на основе слоя абстрактных операторов // Современные наукоемкие технологии. 2025. № 5. С. 10-21;URL: https://top-technologies.ru/ru/article/view?id=40384 (дата обращения: 21.06.2026).
DOI: https://doi.org/10.17513/snt.40384