



Введение
Подход предиктивного технического обслуживания и ремонта (ТОиР) использует данные и аналитические методы для прогнозирования работоспособности, отказов оборудования и планирования профилактических работ. Данные, необходимые для ТОиР, непрерывно поступают из различных источников, включая датчики, системы управления и мониторинга, базы данных и журналы событий, отчеты и т.д. Управление значительными по объему разнородными данными и моделями машинного обучения для анализа этих данных является ключевым фактором для успешного внедрения предиктивного ТОиР.
Актуальность данной темы обусловлена возрастающей потребностью в автоматизации и оптимизации технического обслуживания производственного оборудования. Разработка методов управления разнородными данными позволяет получить наиболее полную картину состояния производственного оборудования, учитывая факторы, которые традиционные методы анализа не могли бы учесть [1]. Применение машинного обучения к накопленным наборам данных позволяет создавать точные модели, эффективно предсказывающие отказы оборудования, и, что особенно важно, минимизировать количество ложных срабатываний. Корректно обработанные, проанализированные и представленные в удобном для понимания виде данные повышают эффективность технического обслуживания, что влечет сокращение затрат на избыточно запланированные работы [2].
Целью данной работы является исследование подхода к формированию информационного обеспечения по управлению моделями интеллектуального анализа данных для предиктивного обслуживания, включающего в себя использование методов оценки меры сходства исторических данных о производственном процессе и методов оценки точности выбранных для анализа моделей с целью повышения эффективности принятия управленческих решений технического обслуживания промышленного оборудования (на примере промышленных роботов) на основе анализа обобщенных показателей его работы.
Для достижения поставленной цели были определены следующие задачи.
1. Анализ методов обнаружения аномалий и применение к собранным данным (на примере задачи классификации нагрузки на ось промышленного манипулятора).
2. Анализ подходов управления моделями анализа данных и апробация алгоритма подбора модели на собранных данных (на примере задачи прогнозирования температуры электропривода промышленных манипуляторов).
3. Разработка имитационной модели для оценки экономической эффективности информационного обеспечения процесса принятия решений на основе данных.
Материалы и методы исследования
Для решения поставленных задач использованы следующие методы:
1) методы детектирования аномальных значений (Наивный Байес, Дерево решений, Метод опорных векторов) для задачи № 1;
2) методы прогнозирования целевого параметра (регрессия, рекуррентная нейронная сеть) и оценки точности прогнозных значений для задачи № 2;
3) методы имитационного моделирования с использованием программного пакета Arena Simulation для задачи № 3.
Процесс создания информационного обеспечения для ТОиР на основе данных в рамках предиктивной аналитики включает в себя следующие основные шаги:
1) сбор данных – агрегирование данных с разных источников: датчиков, контроллеров, журналов событий, систем мониторинга, расписания и регламентов ТОиР;
2) конструирование моделей анализа данных – создание и обучение моделей для решения задач прогнозирования работоспособности, остаточного срока службы или раннего отказа оборудования;
3) анализ данных – нахождение и валидация решения с использованием модели анализа данных;
4) разработка альтернатив стратегий ТОиР – оценка целесообразности внедрения плана ТОиР на основе анализа данных в рамках имеющихся ресурсов;
5) оценка рисков – реализация комплексных мер для оценки основных областей риска на основе выявленной проблемы, ранжирование рисков и разработка вариантов работы с рисками;
6) оценка экономической эффективности – выявление проблем на ранней стадии для предотвращения отказов и связанных с ними расходов;
7) назначение процедур ТОиР – оптимизация расписания технического обслуживания и разработка наиболее эффективных стратегий обслуживания на основе данных, параметров работы оборудования и его состояния.
Для автоматизации процесса управлением техническим обслуживанием на основе данных используются подходы с применением методов управления моделями анализа данных, в том числе: оркестрация, цифровой двойник. В рамках настоящей работы предложен подход к формированию информационного обеспечения для процесса принятия решений ТОиР с использованием методов анализа данных и оркестрации моделей машинного обучения, обеспечивающий информационную поддержку, модульность и масштабируемость на всех этапах процесса управления техническим обслуживанием промышленных роботов (рис. 1).
Предложенный подход к автоматизации процесса управлением техническим обслуживанием на базе конвейера обработки данных и конструирования моделей анализа данных содержит следующие компоненты.
1. Инициация процесса управления моделями анализа данных – компонент выполняет следующий набор функций: анализ бизнес-проблемы, постановка целей и формализация критериев достижения, выделение конкретного подхода машинного обучения и определение необходимых данных для решения проблемы.
2. Конвейер атрибутов данных – компонент выполняет следующий набор функций: сбор данных, определение правил для преобразования и очистки данных, определение правил выделения атрибутов, преобразование и очистка данных, выявление аномальных значений.
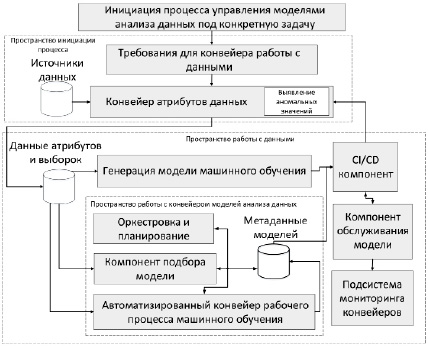
Рис. 1. Процесс автоматизации подготовки данных и построения моделей машинного обучения
3. Генерация модели машинного обучения – компонент выполняет следующий набор функций: предварительный анализ данных, подготовка и валидация данных, выбор алгоритма, обучение и тестирование модели с оптимизацией гиперпараметров, экспорт модели.
4. Оркестровка и планирование – компонент выполняет следующий набор функций: планирование задач, оркестровка рабочего процесса, обработка метаданных модели.
5. Подбор модели – компонент выполняет следующий набор функций: оценка сходства датасетов, выбор и оценка модели.
6. Автоматизированный конвейер рабочего процесса машинного обучения – компонент выполняет следующий набор функций: извлечение и подготовка данных, выбор алгоритма, обучение модели, тестирование и экспорт модели.
7. Обслуживание модели – компонент выполняет следующий набор функций: выполнение оценки на основе новых пакетных или потоковых данных, настройка и дообучение модели.
8. Подсистема мониторинга конвейеров – основная функция компонента: непрерывный мониторинг производительности обслуживания модели анализа данных.
9. CI/CD – основная функция компонента: непрерывная интеграция, доставка и развертывание экспортированной модели.
В настоящей работе проведена апробация комплекса алгоритмов по выявлению аномальных значений (для компонента конвейера атрибутов данных) и подбору и оценке модели анализа данных (для компонента подбора модели). Аномальные значения при анализе больших данных представляют собой отклонения от общего тренда или нормы в наборе данных. Они могут быть вызваны ошибками в сборе данных, случайными факторами или наличием некорректных значений [3]. Для обнаружения аномалий используются статистические методы, машинное обучение или визуализация данных [4, 5].
Результаты исследования и их обсуждение
Для апробации алгоритмов выявления аномальных значений был проведен сбор данных с промышленного манипулятора при выполнении рабочей операции по перемещению палет с различной категорией весовой нагрузки. На собранных данных рассмотрена задача классификации весовой нагрузки на промышленном манипуляторе с целью обнаружения аномальных значений. Под аномальными значениями понимаются отклонения анализируемых параметров (таких как: момент силы, ток, температура привода) за пределы референтных значений (определенных при наладке рабочей программы манипулятора) и результатов классификации, которые определяют корректность весовой нагрузки на осях манипулятора [6]. Для определения референтных значений был использован подход по определению крайних значений относительно номера операции [7]. Рабочая программа состоит из перечня команд, которые выполняются последовательно. Классификация нагрузки проводится на основе анализа параметра тока в процессе работы электроприводов манипулятора.
Параметры датасета:
1. Размер выборки – 53910 строк.
2. Дискретность данных – 0,2 секунды.
3. Атрибуты выборки – угловая скорость, значение тока, температура, момент силы электродвигателей, положение осей манипулятора.
4. Категория нагрузки: 1 – корректная весовая нагрузка, 0 – некорректная весовая нагрузка.
5. Процесс сбора данных – перемещение палеты с различной нагрузкой промышленным манипулятором KUKA 40 PA в течение 320 минут.
Для классификации категории нагрузки на ось манипулятора были использованы методы: Наивный Байес, дерево решений, метод опорных векторов, линейная модель. Было построено несколько базовых моделей классификации, которые обучалась на основе предоставленных данных (табл. 1). Использованы модели с бинарной классификацией – метрика точности показывает процент правильно классифицируемой категории весовой нагрузки.
Обученные модели показали относительно хорошие результаты для решения задачи классификации нагрузки на промышленном манипуляторе. Была достигнута высокая точность классификации (до 93%), что позволяет сделать вывод о способности модели правильно определять нагрузку на основе агрегированных параметров манипулятора. Обученные модели могут быть применены для определения оптимальной нагрузки для каждого промышленного манипулятора или для обнаружения проблем в процессе выполнения рабочей программы, что классифицируется как аномальное значение.
На примере собранных данных с четырех разных промышленных роботов была рассмотрена задача по управлению моделями анализа данных, в частности подбора обученных моделей для анализа тестовых датасетов, имеющих наибольшее сходство с обучающей выборкой. Конструирование и обучение моделей производились с целью прогнозирования температуры электропривода на оси промышленного робота.
Параметры датасетов:
1. Размер выборки – 279570 строк.
2. Дискретность данных – 1 секунда.
3. Атрибуты выборки – угловая скорость, значение тока, температура, момент силы электродвигателей.
4. Процесс сбора данных – перемещение пластиковых кубов внутри роботизированной ячейки (Робот 1), фрезерование фигурного изделия из дерева (Робот 2), перемещение коробок с конвейера на палету (Робот 3), сварочные работы (Робот 4).
Сходство датасетов оценивалось методом косинусного расстояния [8]. Метод оценивает сходство в интервале [0; 1] (то есть, чем ближе значение к единице, тем более схожи сравниваемые наборы данных). Оценка сходства датасетов используется для трансферного обучения, доменной адаптации, оценки обобщающей способности модели, поиска паттернов во временных рядах [9].
Таблица 1
Результаты тестирования моделей для задачи классификации нагрузки на осях промышленного манипулятора
|
Выборка 1 |
Выборка 2 |
Выборка 3 |
|
|
Модель |
точность, % |
точность, % |
точность, % |
|
Наивный Байес |
87 |
85 |
91 |
|
Дерево решений |
74 |
36 |
73 |
|
Метод опорных векторов |
89 |
84 |
93 |
|
Линейная модель |
81 |
75 |
77 |
Таблица 2
Коэффициенты сходства данных
|
Оценка сходства датасетов |
||||
|
Выборка |
Робот 1 |
Робот 2 |
Робот 3 |
Робот 4 |
|
Робот 1 |
1 |
0,89 |
0,87 |
0,90 |
|
Робот 2 |
0,89 |
1 |
0,89 |
0,91 |
|
Робот 3 |
0,87 |
0,89 |
1 |
0,90 |
|
Робот 4 |
0,90 |
0,91 |
0,90 |
1 |
Таблица 3
Результаты тестирования моделей для задачи прогнозирования температуры привода
|
Обучающая |
Робот 1 |
Робот 2 |
Робот 3 |
Робот 4 |
||||
|
Тестовая |
t, сек |
p, % |
t, сек |
p, % |
t, сек |
p, % |
t, сек |
p, % |
|
Линейная модель (Linear) |
||||||||
|
Робот 1 |
8,67 |
70,83 |
2,01 |
47,79 |
2,17 |
51,87 |
2,03 |
59,37 |
|
Робот 2 |
2,01 |
44,79 |
16,43 |
51,04 |
2,57 |
44,79 |
2,12 |
43,75 |
|
Робот 3 |
1,99 |
51,87 |
2,00 |
30,20 |
14,25 |
78,12 |
2,29 |
26,04 |
|
Робот 4 |
2,31 |
28,12 |
2,61 |
43,75 |
2,12 |
37,5 |
14,57 |
42,71 |
|
Многослойный перцептрон (MLP) |
||||||||
|
Робот 1 |
4,03 |
83,01 |
2,10 |
80,51 |
2,10 |
74,50 |
2,10 |
79,83 |
|
Робот 2 |
2,10 |
75,74 |
4,52 |
80,75 |
2,10 |
72,96 |
2,10 |
72,57 |
|
Робот 3 |
2,10 |
77,32 |
2,10 |
81,71 |
3,31 |
73,28 |
2,10 |
73,91 |
|
Робот 4 |
2,10 |
73,16 |
2,10 |
80,43 |
2,10 |
75,37 |
4,86 |
71,73 |
|
Рекуррентная нейронная сеть (RNN) |
||||||||
|
Робот 1 |
11,46 |
83,95 |
2,10 |
81,23 |
2,10 |
74,27 |
2,23 |
76,32 |
|
Робот 2 |
2,10 |
79,21 |
11,90 |
82,78 |
2,10 |
77,15 |
2,10 |
70,81 |
|
Робот 3 |
2,10 |
71,83 |
2,10 |
79,51 |
12,09 |
80,14 |
2,10 |
72,84 |
|
Робот 4 |
2,10 |
80,45 |
2,10 |
72,11 |
2,10 |
79,32 |
9,60 |
74,54 |
|
Регрессор случайного леса (RFR) |
||||||||
|
Робот 1 |
7,00 |
98,10 |
2,32 |
88,26 |
2,42 |
88,19 |
2,11 |
84,45 |
|
Робот 2 |
2,23 |
19,00 |
5,00 |
89,87 |
2,41 |
29,18 |
1,9 |
89,80 |
|
Робот 3 |
1,92 |
14,74 |
2,76 |
87,78 |
5,00 |
93,43 |
2,10 |
86,78 |
|
Робот 4 |
2,22 |
16,09 |
1,98 |
87,53 |
2,22 |
36,59 |
9,00 |
90,29 |
|
Регрессор гауссовского процесса (GPR) |
||||||||
|
Робот 1 |
40 |
97,90 |
12,11 |
87,53 |
22,99 |
84,87 |
32,58 |
82,20 |
|
Робот 2 |
12,84 |
40,64 |
215 |
91,31 |
12,16 |
62,50 |
13,40 |
71,46 |
|
Робот 3 |
11,91 |
45,22 |
12,72 |
55,69 |
152 |
95,51 |
22,45 |
76,07 |
|
Робот 4 |
12,01 |
31,43 |
12,13 |
41,53 |
22,15 |
35,54 |
188 |
93,11 |
В рамках данной работы метод оценки сходства датасетов применен с целью оценки обобщающей способности моделей машинного обучения для анализа данных, собранных с разных промышленных роботов. Данная оценка необходима для оптимизации вычислительных и временных ресурсов на использование моделей анализа данных. Результаты оценки сходства представлены в таблице 2.
На основе полученных результатов сходства датасетов с разных роботов можно сделать вывод о высокой доле сходства данных, собранных в процессе рабочего цикла.
Результаты тестирования моделей анализа данных на примере задачи прогнозирования температуры привода на осях промышленных роботов представлены в таблице 3 [10]. Для тестирования использованы следующие метрики: суммарное время обучения и тестирования модели (t, сек), точность прогнозирования значения целевого параметра в заданном интервале ±0,5 градусов (p, %).
Описание тестируемых моделей
1. Линейная модель – модель с одним слоем (реализуется через программную библиотеку «Keras»; функция потерь – среднеквадратичная ошибка; оптимизатор – «Adam»; количество эпох – 20).
2. Многослойный перцептрон – модель с двумя скрытыми слоями по 64 нейрона и одним выходным нейроном (реализуется через программную библиотеку «Keras»; функция потерь – среднеквадратичная ошибка; оптимизатор – «Adam»; активатор слоя – «relu»; количество эпох – 20).
3. Рекуррентная нейронная сеть – модель с одним скрытым слоем долговременной краткосрочной памяти (LSTM) размером в 32 нейрона (реализуется через программную библиотеку «Keras»; функция потерь – среднеквадратичная ошибка; оптимизатор – «Adam»; количество эпох – 20).
4. Регрессор случайного леса – модель регрессии с максимальной глубиной леса 5 и количеством деревьев решений 10 (реализуется через программную библиотеку «Scikit-learn»).
5. Регрессор гауссовского процесса – модель регрессии с дисперсией дополнительного гауссовского шума измерений 1е-12 и количеством перезапуска оптимизаторов 1 (реализуется через программную библиотеку «Scikit-learn»).
В таблице 3 представлены результаты обучения перечисленных пяти моделей анализа данных на обучающих выборках (название промышленного робота, с которого сформирована обучающая выборка, указано в столбце) и результаты тестирования моделей на тестовых выборках (название промышленного робота, с которого сформирована тестовая выборка, указано в строке).
Из результатов тестирования различных моделей машинного обучения на датасетах, сформированных с разных промышленных роботов, видно, что часть обученных моделей (MLP, RNN, RFR) показывают высокую точность при тестировании, что позволяет сделать вывод о хорошей обобщающей способности получившихся моделей для анализа данных с разных единиц оборудования. Использование уже обученных моделей анализа данных позволяет сократить временные ресурсы на конструирование новых моделей.
Результаты имитационного моделирования
Согласно полученным результатам, подход, реализующий алгоритм подбора моделей, позволяет сократить временные ресурсы для их обучения, что даст возможность уменьшить экономические издержки (на этапе конструирования и тестирования модели) при процессе принятия решений на основе данных. В программной среде моделирования Arena Simulation разработана модель для сравнения затраченного времени. Данная модель производит расчет экономии временных ресурсов на конструирование новых моделей в зависимости от наличия достаточного количества схожих датасетов (приемлемых для анализа) и процента потери точности прогнозирования модели. Из результатов работы имитационной модели следует, что ситуация с наибольшей экономией временных ресурсов (до 18,6%) на конструирование новых моделей машинного обучения возникает при достаточном количестве датасетов (от 70%), имеющих схожий набор данных, и наименьшей потери точности прогнозирования (до 15%).
Для оценки экономических издержек была использована следующая модель [11, 12], адаптированная под процесс принятия решений по предиктивному ТОиР для промышленных роботов с учетом алгоритма подбора моделей анализа данных. Модель основана на следующих ключевых параметрах:
1) расходы на правильно спрогнозированный отказ;
2) расходы на обслуживание, включающие расходы на регулярное техническое обслуживание оборудования;
3) расходы на конструирование и обучение моделей анализа данных;
4) суммарная экономия от применения предиктивного технического обслуживания.
Для парка промышленных роботов разработана следующая экономическая модель принятия решений № 1 (формулы 1, 2):
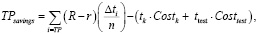 (1)
(1)
где R – стоимость замены комплектующих;
r – стоимость ремонта оборудования;
n – количество дней для прогнозирования потенциального отказа;
Δti – временной промежуток для анализа выборки;
TP – истинные прогнозы отказов оборудования в рамках временного промежутка.
TPsavings – оценка экономии на основе обнаруженных сбоев. Если сбой обнаружен в нужное время, но в неправильной единице оборудования или подсистеме, это засчитывается как ложноположительный результат. Истинные положительные стороны выражаются в экономии, которая представляет собой разницу между затратами на замену и ремонт;
tk – временные затраты на конструирование модели интеллектуального анализа данных;
Costk – оценка расходов в условных единицах, необходимых для процесса конструирования модели интеллектуального анализа данных;
ttest – временные затраты на тестирование и валидацию модели интеллектуального анализа данных;
Costtest – оценка расходов в условных единицах, необходимых для процесса тестирования и валидации модели интеллектуального анализа данных.
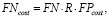 (2)
(2)
где FN – прогнозы отказов оборудования, не обнаруженные в рамках временного промежутка;
FNcost – оценка расходов стоимости замены оборудования на основе невыявленных сбоев. Данная категория показаний представляет реальные сбои в работе оборудования и подсистемы, которые не были обнаружены в течение определенного временного промежутка. Ложноотрицательные результаты переводятся в стоимость замены;
FPcost – оценка расходов стоимости проверки оборудования на основе ложных данных анализа. Данная категория показаний определяет выданные предупреждения в оборудовании и подсистеме, в которых в течение определенного временного промежутка в будущем не происходит сбоев. Ложные срабатывания переводятся в стоимость проверки.
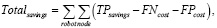 (3)
(3)
где Totalsavings – итоговая оценка в условных единицах расходов стоимости технического обслуживания на основе анализа данных.
С учетом расходов не только на оценку прогнозных моделей, но и на ресурсы, необходимые для конструирования и обучения, получается следующая экономическая модель № 2 (формулы 4, 5):
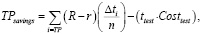 (4)
(4)
 (5)
(5)
где kaccuracy – коэффициент потери точности модели интеллектуального анализа данных;
tselection – временные затраты на подбор и рекомендацию модели интеллектуального анализа данных;
Costselection – оценка расходов, необходимых для процесса подбора и рекомендации модели интеллектуального анализа данных.
Для оценки экономической целесообразности внедрения алгоритма подбора предиктивных моделей на основе расчета сходства датасетов был применен метод имитационного моделирования. В программной среде Arena Simulation разработана имитационная модель, позволяющая оценить эффект от внедрения алгоритма подбора модели анализа данных (рис. 2). Имитационная модель состоит из следующего набора блоков:
1) блок «создание сущности» – под сущностью подразумевается модель анализа данных, на основе прогнозов которой производятся экономические расчеты для принятия дальнейших решений по инспекции, ремонту и обслуживанию оборудования;
2) блок для хранения переменных, в котором производится первичная инициализация расчетных значений, которые включают в себя: время конструирования и тестирования модели (40–215 и 12–32 секунд соответственно), условные стоимости конструирования и тестирования (9–11 у.е. и 7–10 у.е. соответственно), условную экономию за счет корректно спрогнозированных отказов (10000–20000 у.е.);
3) блоки подготовки данных, конструирования и тестирования модели, использующие значения из ранее инициализированных переменных;
4) блоки расчетов расходов на основе данных, учитывающие время и стоимость работы с моделями анализа данных, расходы по инспектированию оборудования (4000 у.е.) и по ремонту оборудования (8000 у.е.);
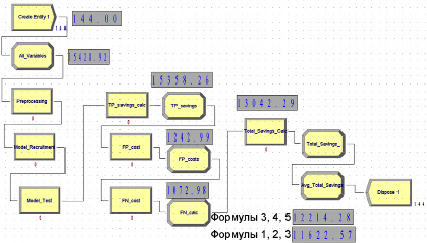
Рис. 2. Имитационная модель для подсчета и сравнения параметра Totalsavings для двух экономических моделей
5) блок итогового расчета полученной условной выгоды от принятия решений на основе данных;
6) блок калькуляции среднего значения итогового расчета в течение всего времени работы имитационной модели.
Результаты имитационного моделирования, наглядно демонстрирующие экономию временных ресурсов на конструирование моделей анализа данных за счет внедрения алгоритма подбора модели: итоговая средняя экономия (Totalsavings) модели № 1 равняется 11622 у.е. (моделирование 24 часа, обработано 144 сущности), а итоговая средняя экономия модели № 2 равняется 12214 у.е.
Исходя из результатов сравнения двух имитационных моделей (основанных на экономических моделях принятия решений № 1 и № 2), при заданных параметрах моделирования в условных единицах вторая модель (спроектированная с учетом разработанной алгоритмической модели по подбору моделей интеллектуального анализа на основе оценки сходства данных) позволяет сократить расходы на использование моделей анализа для принятия решений на основе данных для ТОиР на 5,10%. Получаемые в результате прогнозирования данные о состоянии оборудования и экономические оценки расходов используются в системах информационного обеспечения принятия решений [13] для следующих целей.
1. Оптимизация планового обслуживания – минимизация простоев и рисков за счет более точного планирования технических работ на основе данных о состоянии оборудования.
2. Диагностика состояния – выявление компонентов, наиболее подверженных износу или отказу, за счет прогнозирования состояния и остаточного срока службы.
3. Управление складскими запасами – оптимизация использования и хранения комплектующих и расходников.
Заключение
В настоящей работе были исследованы методы и алгоритмы управления моделями машинного обучения для предиктивного технического обслуживания на основе анализа данных. Для оценки применимости методов анализа данных было сконструировано восемь моделей (три модели для задачи классификации нагрузки на ось промышленного робота и пять моделей для задачи прогнозирования температуры электропривода на оси промышленного робота), показавших приемлемую точность.
В рамках подхода по формированию информационного обеспечения для принятия решений по предиктивному техническому обслуживанию был разработан алгоритм подбора оптимальной модели анализа на основе сходства датасетов, сформированных с разных единиц промышленного оборудования. Основной целью использования данного алгоритма является сокращение временных ресурсов на конструирование новых моделей анализа данных. Для оценки экономической целесообразности применения данного алгоритма были разработаны три имитационные модели: одна для оценки экономии временных ресурсов (до 18,6%) в зависимости от наличия датасетов, имеющих наибольшую степень сходства, и сравнение двух моделей для оценки средней экономии материальных ресурсов на конструирование новых моделей анализа данных (до 5,1%).
Управление большим объемом разнородных данных и моделями анализа данных является одним из ключевых факторов для успешного внедрения предиктивного ТОиР. Управление моделями анализа данных и оптимизация ресурсов для их использования позволяют быстро переобучать модели на новых данных, что делает их более гибкими и адаптивными к изменениям. В дальнейшей работе планируется исследовать способность федеративного и трансферного машинного обучения для возможности адаптации уже обученных моделей в целях решения нового кейса, при условии значительного или незначительного отличия от того кейса, на котором модель была первоначально обучена.
Библиографическая ссылка
Гончаров А.С. ПОДХОД К ФОРМИРОВАНИЮ ИНФОРМАЦИОННОГО ОБЕСПЕЧЕНИЯ ДЛЯ ПРОЦЕССА ПРИНЯТИЯ РЕШЕНИЙ ПО ПРЕДИКТИВНОМУ ТЕХНИЧЕСКОМУ ОБСЛУЖИВАНИЮ // Современные наукоемкие технологии. 2024. № 11. С. 17-25;URL: https://top-technologies.ru/ru/article/view?id=40205 (дата обращения: 01.08.2026).
DOI: https://doi.org/10.17513/snt.40205