



Введение
В настоящее время развитие нефтехимической отрасли невозможно представить без газофракционирующих установок, которые входят в состав газоперерабатывающих, нефтеперерабатывающих, нефтехимических и химических заводов. Данные установки позволяют разделять сырую нефть и газ на различные углеводородные фракции, которые в дальнейшем становятся сырьем для производства различных нефтехимических продуктов. Разделение сырья на отдельные фракции позволяет не только эффективно управлять производственными процессами, улучшая качество конечного продукта и снижая затраты на переработку, но и повышать степень извлечения ценных компонентов из сырья, что способствует увеличению прибыли предприятия.
Для разделения смеси на индивидуальные компоненты, с последующим выделением товарных продуктов, на газофракционирующей установке применяются такие методы, как ректификация, абсорбция, конденсация и адсорбция. Состав газофракционирующей установки обычно включает в себя блок очистки газов, блок ректификации и абсорбции, блок охлаждения и компрессии.
В ходе моделирования технологических процессов установки газофракционирования возможно решение проблем действующих производств, увеличение выхода продуктов и совершенствование технологических процессов установки. Данные результаты достигаются с помощью разработки оптимизационных сценариев, расчетов эффективности оборудования при изменении технологических параметров и компонентного состава сырья [1–3].
В качестве среды для моделирования химико-технологических процессов используются различные симуляторы, которые способны отражать работу реальных установок в виде математического описания протекающих процессов. Самыми популярными моделирующим программными обеспечениями, используемыми в нефте-газохимической отрасли, являются Aspen Hysys, Petro-SIM, GIBBS, «Аэросим» и др. [4–6]. Такой подход обеспечивает возможность изучать моделируемый объект, проводить различные исследования, проведение которых в реальных условиях было бы затруднительно или по ряду причин небезопасно.
Также в качестве инструмента для математического описания химико-технологических процессов используются методы модели машинного обучения [7–9]. Модель машинного обучения – это математический алгоритм или статистическая модель, которая используется для выявления закономерностей и принятия решений в процессе обучения на основе входных данных. Таким образом в результате работы модели машинного обучения возможно получение выходных данных без проведения технологических расчетов, а основываясь только на полученных коэффициентах, вычисленных в ходе обучения модели.
Новым актуальным подходом в моделировании химико-технологических процессов является комплексное использование методов, рассмотренных ранее [10–12]. Первым этапом такого способа является расчет процесса в моделирующей среде, а полученные данные далее используются для разработки модели машинного обучения. Такой подход обеспечивает более точный и подробный анализ химико-технологического процесса без значительных временных затрат.
Цель исследования – совершенствование процессов переработки углеводородного и химического сырья при изменении параметров технологического режима или компонентного состава сырья.
Материалы и методы исследования
Для моделирования химико-технологических систем применяется универсальная моделирующая программа Aspen Hysys V12, которая является одним из популярных симуляторов для моделирования процессов благодаря своей высокой точности, обширной базе данных, которая включает в себя основные модули химико-технологических процессов, интеграции с другими продуктам AspenTech и интуитивно понятному интерфейсу. Программа также обладает высокой производительностью и масштабируемостью, что позволяет использовать его как для небольших задач, так и для крупных проектов с высокими требованиями к вычислительным ресурсам.
Процесс расчета можно разделить на несколько этапов:
1) анализ исследуемого процесса и последующее его разделение на последовательные подпроцессы, связанные друг с другом материальными и энергетическими потоками;
2) установка модулей, описывающих подпроцессы из базы универсальной моделирующей программы, подключение установленных модулей с материальными и энергетическими потоками, определение спецификаций модулей для обеспечения сводимости;
3) расчет установки, в ходе которого был получен материальный и тепловой баланс;
4) проверка адекватности, в ходе которой сравниваются полученные в ходе расчетов и рабочие результаты установки.
Модель машинного обучения разрабатывалась в облачном сервисе Google Colaboratory (Google Colab) на основе Jupyter Notebook. Этот облачный сервис позволяет работать на языке Python с большими объемами данных (Big Data) без необходимости установки дополнительного программного обеспечения. Благодаря встроенным библиотекам, таким как Sklearn, TensorFlow и PyTorch, Google Colab является удобным и эффективным инструментом для разработки и тестирования моделей машинного обучения. Сервис предоставляет бесплатный доступ к мощным графическим процессорам (GPU) и тензорным процессорам (TPU), что значительно ускоряет процесс обучения сложных моделей.
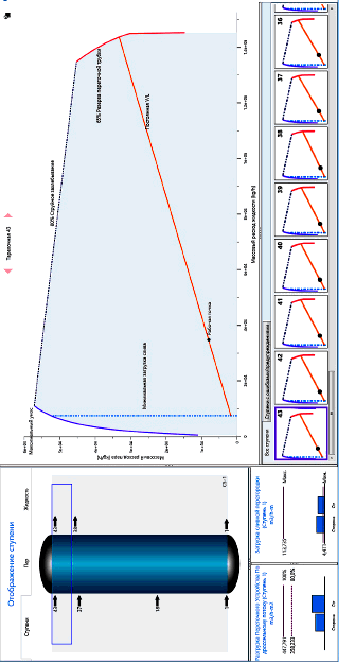
Рис. 1. Гидравлическая диаграмма колонны
Результаты исследования и их обсуждение
Газофракционирующая установка включает в себя 5 блоков, а именно: абсорбции пирогаза, выделения этан-этиленовой фракции, очистки газа, деметанизации этан-этиленовой фракции и выделения этилена.
Для обеспечения сходимости расчетов требуется специфицировать технологические параметры работы оборудования. Для колонного оборудования необходимо задаться температурными профилями колонны, то есть температурой низа и верха колонны или отдельных ее секций, что позволит регулировать переход целевого компонента из одного агрегатного состояния в другое. Согласно уравнению Клапейрона – Клаузиуса при изменении давления системы температура кипения компонента смещается в ту же сторону, следовательно, давление внутри колонного оборудования используется в качестве спецификации в ходе расчетов такими параметрами, как давление верха и низа колонны.
В ходе моделирования колонного оборудования был проведен гидравлический расчет. Для этого были заданы такие геометрические параметры, как диаметр колонного оборудования, тип контактных устройств и расстояние между ними, диаметр колпачков и высота их юбки, количество ходов по тарелке, количество колпачков на тарелке и толщину тарелки. В качестве проектных параметров задаются такие параметры, как процент затопления тарелки, минимальная площадь сливного устройства к общей площади тарелки, максимальный процент струйного затопления, максимальный процент затопления переливного устройства, коэффициент вспенивания жидкости, коэффициент аэрации, фактор избыточной концентрации. В процессе гидравлического анализа исследуемой абсорбционно-отпарной колонны газофракционирующей установки была выявлена возможность увеличения производительности колонного оборудования на 20 % с учетом нормальной работы контактных устройств. Гидравлическая диаграмма исследуемой колонны на рис. 1.
Для расчета реактора гидрирования ацетилена требуется задаться сведениями о стехиометрии, указать компоненты и протекающие в реакторе реакции, перепад давления и геометрические параметры. Расчет реактора приведен на рис. 2.
Расчет теплообменного оборудования сводится к определению параметров температур, давлений и расходов входных и выходных материальных потоков, а также определения геометрии и типа «TEMA» оборудования. Расчет теплообменного оборудования в среде Aspen Hysys приведен на рис. 3.
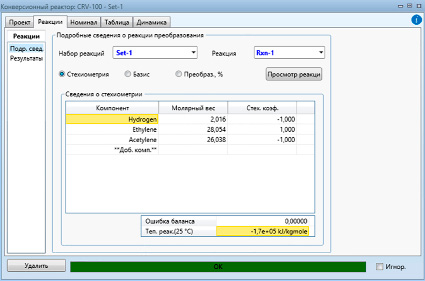
Рис. 2. Расчет реактора гидрирования ацетилена
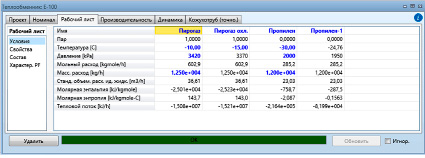
Рис. 3. Расчет теплообменного оборудования
Полученная в ходе расчетов схема цифровой модели установки газофракционирования представлена на рис. 4 и 5.
Благодаря результатам, полученным в ходе моделирования установки в среде Aspen Hysys, была разработана модель машинного обучения, способная предсказывать массовую долю этилена в составе насыщенного абсорбента при изменении технологических параметров абсорбционно-отпарной колонны и компонентного состава сырья. База данных, используемая для обучения и тестирования модели, была составлена из экспериментальных данных, полученных в ходе расчетов установки в среде Aspen Hysys, а также производственных данных, полученных с действующего предприятия. Таким образом, входными параметрами модели являются массовые расходы сырья и абсорбента, компонентный состав сырья. В качестве выходных параметров представляется массовая доля этилена в составе насыщенного абсорбента, а также его массовый расход.
Работу модели машинного обучения можно разделить на 6 этапов: структуризация входных данных; обучение модели; проведение тестирования; вычисление ошибки; ввод новой обстановки; проведение предсказания для новой обстановки.
Этап структуризации данных включает использование библиотек Pandas и scikitlearn. Библиотека Pandas, предназначенная для обработки и анализа входных данных, преобразует полученные данные из среды Aspen Hysys в структурированный массив данных. Библиотека scikitlearn, содержащая функции и алгоритмы машинного обучения, разбивки данных на группы и прогнозирования, разбивает полученный массив данных с собранными рабочими параметрами абсорбционно-отпарной колонны на входные и выходные данные «Х» и «У». Вводятся переменные тестирования и тренировки x_test,y_test и x_train,y_train, объем которых определяется функцией train_test_split, которая разбивает тестовые и тренировочные данные на 20 и 80 % соответственно, а также псевдорандомизирует последовательность строк на данное отношение.
Полученные предсказания и процесс обучения модели основываются на использовании метода линейной регрессии, уравнение которой представлено в формуле
у = β0 + β1x1 + β2x2 + … + βnxn + ϶, (1)
где y – зависимая переменная, включающая в себя выходные данные массовой доли этилена в насыщенном абсорбенте и его расход,
β0 – константа, определяющая смещение линии регрессии вдоль оси y, то есть начальное значение в случае, когда все независимые переменные равны нулю. В данном случае константа равна нулю,
x1…xn – независимые переменные, включающие в себя входные данные,
β1… βn – коэффициенты при независимых переменных, определяющиеся по сумме квадратов разности фактических и предсказанных значениях. В начале обучения задаются случайным образом для предсказания и последующего обновления,
ϵ – ошибка модели, равная разнице между фактическими и предсказанными значениями выходных данных.
Для анализа обученной модели вызывается модуль scikitlearn. metrics, включающий в себя метрику оценки производительности. Таким образом, погрешность модели можно вычислить с помощью метода средней абсолютной ошибки. В качестве фактических и предсказанных значений используются параметры расхода насыщенного абсорбента и доли целевого компонента в составе насыщенного абсорбента.
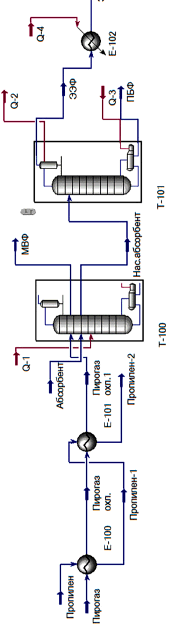
Рис. 4. Расчетная схема процесса в пакете Aspen Hysys, лист 1
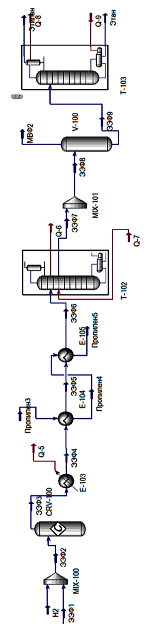
Рис. 5. Расчетная схема процесса в пакете Aspen Hysys, лист 2
Результаты предсказания для новой обстановки
|
Предсказанные значения |
||
|
Доля этилена в насыщенном абсорбенте, % мас. |
Расход насыщенного абсорбента, кг/ч |
Расход этилена в насыщенном абсорбенте, кг/ч |
|
0,1482 |
34530 |
5117 |
|
Актуальные значения |
||
|
Доля этилена в насыщенном абсорбенте, % мас. |
Расход насыщенного абсорбента, кг/ч |
Расход этилена в насыщенном абсорбенте, кг/ч |
|
0,1486 |
34230 |
5085 |
Уравнение средней абсолютной ошибки представлено в формуле
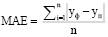 , (2)
, (2)
где yф – фактическое значение переменной,
yп – предсказанное значение переменной,
n – количество переменных.
Для предсказания новых рабочих параметров абсорбционно-отпарной колонны предусматривается создание нового наблюдения. На основе обученной модели производится предсказание выходных данных, которые после выводятся. Для удобства использования модели производится расчет этилена в насыщенном абсорбенте в килограммах в час. Результаты предсказания для новой обстановки представлены в виде таблицы, где предсказанные значения – значения, полученные в ходе работы обученной модели, актуальные значения – экспериментальные значения, полученные в результате моделирования установки в среде Aspen Hysys V12.
Заключение
В результате технологического моделирования построена цифровая модель установки газофракционирования в пакете Aspen Hysys V12. В ходе анализа результатов работы модели проведено исследование, включающее регулирование расхода абсорбента на абсорбционно-отпарную колонну с учетом изменения компонентного состава сырья. Более точное определение уставки расхода абсорбента позволило улавливать целевой компонент смеси в абсорбтиве, а также влиять на температурные профили оборудования.
Результаты цифровой модели установки были использованы для разработки модели машинного обучения блока абсорбции, которая способна предсказывать массовую долю этилена в составе насыщенного абсорбента, а также расход насыщенного абсорбента с точностью 99,4 %. Полученные результаты могут быть использованы для повышения эффективности процесса абсорбции на газофракционирующих установках предприятий.
Библиографическая ссылка
Бронская В.В., Зиннурова О.В., Фирсин А.А., Шипин А.В. ЦИФРОВОЕ МОДЕЛИРОВАНИЕ УСТАНОВКИ ГАЗОФРАКЦИОНИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ // Современные наукоемкие технологии. 2024. № 11. С. 10-16;URL: https://top-technologies.ru/ru/article/view?id=40204 (дата обращения: 01.08.2026).
DOI: https://doi.org/10.17513/snt.40204