



Введение
Глубокое обучение продемонстрировало огромный потенциал в различных реальных приложениях, включая обнаружение объектов. Эта технология привела к многообещающим результатам в обнаружении объектов на изображениях, особенно в области строительства и безопасности трудах [1]. Обнаружение защитных строительных масок по-прежнему имеет решающее значение для обеспечения безопасности труда на строительных площадках, соблюдения гигиенических норм в строительных учреждениях и поддержания безопасности в различных отраслях промышленности. Кроме того, достижения в области моделей глубокого обучения для обнаружения масок расширяют область компьютерного зрения, предлагая потенциальные возможности для обнаружения других видов средств индивидуальной защиты (СИЗ).
Целью исследования является анализ эффективности аннотирования и локализации объектов защитных строительных масок на лице работника в видеопотоке, на основе метрик точности для двух реализаций архитектуры MobileNet. Для решения поставленной цели необходимо решить следующие задачи:
Для достижения цели потребуется решить следующие задачи:
− выбор актуального набора данных для машинного обучения;
− предварительная обработка данных;
− обучение модели на основе аннотированного набора данных;
− определение оценочных показателей для измерения точности модели и расчет этих показателей для обеих реализаций архитектуры MobileNet;
− сравнение производительности этих реализаций архитектуры MobileNet с использованием оценочных показателей.
Материалы и методы исследования
Для обнаружения масок была использована сверточная нейронная сеть (CNN) с архитектурой MobileNet [2]. Скрипт был разработан с использованием библиотек Python, Tensorflow/Keras и OpenCV [3, 4]. Работа алгоритма обнаружения в потоковом видео основана на захвате кадров в виде входных изображений с заданными границами объектов. Метод прогнозирования объектов на изображении основан на известных режимах свертки. Для каждого пикселя на данном изображении оценивается набор ограничивающих рамок (обычно 4) разных размеров и соотношений сторон. Кроме того, для каждого пикселя вычисляется степень достоверности для всех возможных объектов, включая метку «Маски нет». Этот процесс повторяется для нескольких карт объектов. Для извлечения карт объектов используются предварительно обученные методы (базовые модели). Эти методы используются для решения задач классификации с высокой точностью. В качестве базовой модели для Single-Shot Multi Box (SSD) была использована сеть MobilNet версии 3. А, соответственно, ImageNet – это база данных изображений, которая была предварительно обработана на сотнях тысяч изображений, что отлично подходит для классификации изображений [5, 6]. Во время обучения предполагаемые границы сравниваются с фактическими. При обратном распространении параметры корректируются в соответствии с требованиями. Перед слоем классификации в модели MobilNet V3 добавляются слои объектов. Размер этих слоев постепенно уменьшается [7]. Каждое пространственное пространство объектов имеет ядро, которое выдает результаты, показывающие, существует объект или нет. Так же определяются размеры ограничивающей рамки. Из-за небольшого размера фильтров, применяемых к изображению, существует множество весовых параметров, которые в конечном итоге могут привести к повышению производительности. Последняя версия OpenCV включает модуль Deep Neural Network (DNN), который содержит предварительно обученную нейронную сеть (kCNN) для распознавания лиц [8, 9].
Набор данных был создан на основе общедоступного набора данных изображений со строительными защитными масками и без них Construction Mask Dataset [10, 11]. Для эксперимента было отобрано 8020 изображений, в том числе 4408 изображений с масками и 3612 изображений без масок. Эти изображения были использованы для обучения и тестирования модели с использованием мультисенсорного потока и современных методов распознавания объектов в CNN [12]. Набор данных был предварительно обработан с помощью функции preprocess_input в MobileNet V2. Базовая сеть была модифицирована путем добавления слоев: среднего объединяющего слоя, выравнивающего слоя, плотного слоя (128 единиц, активация ReLU), слоя с отсевом половины и последнего плотного слоя (2 единицы, активация сигмовидной кишки) [13, 14]. Общий процесс проиллюстрирован ниже.
Проект распознавания лиц по маскам разделен на две части. Обучение модели с помощью свертки или любой предварительно обученной модели для обнаружения масок на изображениях, что решает проблему бинарной классификации. Распознавание лиц на видео или изображениях и прогнозирование ношения масок с помощью обученной модели. Применялось обучение переносу с использованием предварительно обученных моделей MobileNet. Сеть использует разделяемые по глубине свертки, ее основной структурный блок показан на рис. 1. Этот блок включает в себя три сверточных слоя, последние два из которых являются глубинными свертками, фильтрующими входные данные, за которыми следует слой поточечной свертки размером 1x1. В отличие от V1, V3 уменьшает количество каналов в поточечной свертке 1x1, известной как проекционный слой, уменьшая размерность. Например, слой по глубине может обрабатывать тензор со 144 каналами, которые проекционный слой уменьшает до 24 (рис. 2). Этот уровень также называется уровнем узких мест, поскольку он уменьшает объем данных, проходящих через сеть. Свертка по глубине применяет свои фильтры к тензору. Наконец, проекционный слой преобразует 144 отфильтрованных канала в меньшее число, например в 24. Входные и выходные данные блока представляют собой тензоры низкой размерности, в то время как фильтрация выполняется по тензору высокой размерности. Остаточные соединения, аналогичные ResNet, помогают управлять градиентным потоком в сети, при этом каждый слой имеет пакетную нормализацию и активацию ReLU6. Однако выходные данные проекционного слоя не имеют функции активации, что приводит к получению данных малой размерности.
F-Measure объединяет точность и отзывчивость в единую метрику, отражающую оба свойства. В качестве альтернативы точности классификации обычно используют показатели прецизионности и отзыва (табл. 1).
Для анализа регрессионной модели на соответствие набору данных используется среднеквадратичная ошибка (RMSE):
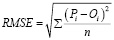 ,
,
где Pi – это прогнозируемое значение в наборе данных с n фото, Oi – наблюдаемое значение для i-го наблюдения в наборе данных.
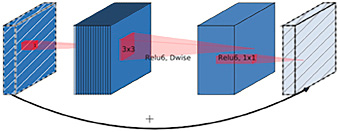
Рис. 1. Слои и свертки MobileNet V2
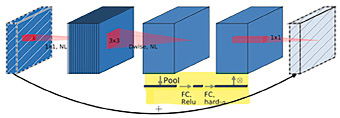
Рис. 2. Слои и свертки MobileNet V3
Таблица 1
Формулы оценки
|
Accuracy |
Precision |
Recall |
F1 |
|
|
Формула |
|
|
|
|
|
Python sklearn.metrics |
accuracy_score |
precision_score |
recall_score |
f1_score |
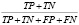
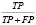
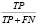

Результаты исследования и их обсуждение
Архитектура MobileNet V2 представлена инвертированными остаточными блоками (IRB), которые заменяют традиционные остаточные блоки более эффективной структурой. MobileNet V3 еще больше повысил эффективность благодаря модифицированной архитектуре инвертированного остаточного блока (MIRB), которая добавляет блок сжатия и возбуждения (SE) для повторной калибровки откликов функций в зависимости от канала (табл. 2).
Помимо извлечения объектов модель может быть расширена для обнаружения объектов и сегментации. Простой мерой оценки модели является точность классификации (общее количество правильных прогнозов, деленное на общее количество прогнозов), но она не подходит для задач несбалансированной классификации, подобных текущей. Чтобы оценить производительность классификатора, для измерения производительности моделей классификации, целью которых является предсказание категориальной метки для каждого входного экземпляра, необходимо изучить матрицы производительности (табл. 3).
Загрузка весов модели и создание объекта MobileNet V3 выполняется с использованием tf.keras.applications.mobilenet_v3. В результате тест показал высокий результат:
93s 465ms/step – loss: 0.0085 – accuracy: 0.9958 – lr: 1.0000e-04
Таблица 2
Сети MobileNet V2 и MobileNet V3
|
Архитектура MobileNet V2 |
Архитектура MobileNet V3 |
||||||
|
Тип / Этап |
Входной размер |
c |
s |
Тип / Этап |
Входной размер |
c |
s |
|
Conv d2 |
224 × 224 × 3 |
32 |
2 |
Conv d2 |
224 × 224 × 224 × 3 |
16 |
2 |
|
Bneck |
112 × 112 × 32 |
16 |
1 |
Bneck, 3 × 3 |
112 × 112 × 16 |
16 |
1 |
|
Bneck |
112 × 112 × 16 |
24 |
2 |
Bneck, 3 × 3 |
112 × 112 × 16 |
64 |
2 |
|
Bneck |
56 × 56 × 24 |
32 |
2 |
… |
… |
||
|
Bneck |
28 × 28 × 32 |
64 |
2 |
Bneck, 5 × 5 |
14 × 14 × 112 |
160 |
2 |
|
Bneck |
14 × 14 × 64 |
96 |
1 |
Bneck, 5 × 5 |
7 × 7 × 160 |
160 |
1 |
|
Bneck |
14 × 14 × 96 |
160 |
2 |
Bneck, 5 × 5 |
7 × 7 × 160 |
160 |
1 |
|
Bneck |
7 × 7 × 160 |
320 |
1 |
Conv d2, 1 × 1 |
7 × 7 × 160 |
960 |
1 |
|
Conv d2 |
7 × 7 × 320 |
1280 |
1 |
Conv / s1 |
7 × 7 × 960 |
- |
1 |
|
Avg Pool 7 × 7 |
7 × 7 × 1280 |
- |
- |
Conv d2, 1 × 1, NBN |
1 × 1 × 960 |
1280 |
1 |
|
Conv d2 1 × 1 |
1 × 1 × 1280 |
k |
Conv d2, 1 × 1, NBN |
1 × 1 × 1280 |
k |
1 |
|
Примечание: S определяет, на сколько пикселей сдвигается окно свертки (фильтр), c – коэффициент, указывает, во сколько раз увеличивается количество каналов в первом слое блока.
Таблица 3
Матрица путаницы
|
Позитивный прогноз |
Отрицательный прогноз |
|
|
Положительный класс |
Истинно положительный (TP) |
Ложноотрицательный (FN) |
|
Отрицательный класс |
Ложноположительный (FP) |
Истинно отрицательный (TN) |
Таблица 4
Сравнение оптимизаторов SGM и ADAM
|
Оптими-затор |
Эпoхи |
Итерации |
Прошедшее время |
Мини-пакет (RMSE) |
Валидация (RMSE) |
Потери мини-пакетов |
Потери на тесте |
|
SGM |
25 |
100 |
0:16:03 |
0,88 |
0,87 |
0,8025 |
0,7917 |
|
50 |
200 |
0:44:21 |
0,73 |
0,82 |
0,5420 |
0,6484 |
|
|
Adam |
25 |
100 |
0:23:55 |
0,59 |
0,69 |
0,3561 |
0,4956 |
|
50 |
200 |
0:46:01 |
0,52 |
0/70 |
0,2656 |
0,4936 |
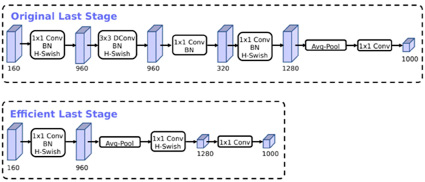
Рис. 3. Нейросеть MobileNet V3
Набор данных разделен на 80 % обучающих, 10 % валидационных и 10 % тестовых изображений. Начальная скорость обучения составляет 0,001, количество эпох – 50. В качестве методов оптимизации использованы ADAM и градиентный спуск (SGM) для сравнения производительности (табл. 4).
Проверка модели в реальном времени проводилась на изображениях двух классов (маска и отсутствие маски). Результаты показали, что SGM достигает меньших затрат времени на обучение по сравнению с ADAM. Первый сверточный слой модели включает слой BN и слой активации h-переключателя. Средняя часть содержит сверточные слои (MB) с узкими местами и SE-структуры сжатия и возбуждения, что уменьшает общий объем вычислений. MobileNet V3 использует больше параметров из-за модуля SE, однако это компенсируется улучшенной точностью и скоростью. SE и h-swish слегка замедляют работу сети, добавляя некоторые задержки, однако это приемлемо ввиду повышения точности. H-swish используются на более глубоких уровнях, где тензоры меньше, что снижает задержку. Использование стандартного SSDLite-MobileNet V2 расширяет последнюю свертку 1x1 с глубины 320 до 1280, что неактуально для текущей задачи с двумя классами (рис. 3).
Сравнение метрик эффективности архитектур MobileNet V2 и V3
Для оценки эффективности архитектур MobileNet V2 и V3 в распознавании медицинских масок использованы данные, показывающие улучшения в производительности MobileNet V3 (табл. 5).
Использование HardSwish и модуля SE улучшает точность и полноту, общий F1-Score также высок. MobileNet V3 демонстрирует значительное увеличение скорости распознавания благодаря новым разделяемым по глубине сверткам и уменьшению числа параметров.
На устройстве Google Pixel MobileNet V3 обеспечивает 1,5-кратное ускорение задач классификации изображений по сравнению с MobileNet V2. На Samsung Galaxy S10 MobileNet V3 ускоряет задачи обнаружения объектов в 2,5 раза.
Таблицы путаницы для MobileNet V3 показывают точность ~99 % на тестовом наборе данных.
Таблица 5
Метрики производительности моделей
|
Модель |
Категории |
precision |
recall |
f1-score |
Support |
|
MobileNet V2 |
С маской |
0,96 |
0,98 |
0,98 |
882 |
|
Без маски |
0,98 |
0,99 |
0,99 |
722 |
|
|
MobileNet V3 |
С маской |
0,97 |
0,99 |
0,98 |
882 |
|
Без маски |
0,99 |
0,99 |
0,99 |
722 |
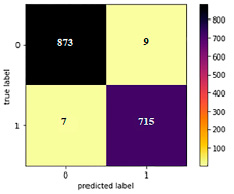
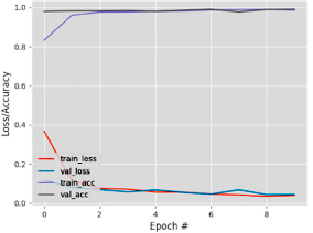
Рис. 4. Матрица путаницы и график модели потерь
Если точность высока, а потери невелики, то модель допускает небольшие ошибки только в некоторых данных (рис. 4), но при этом наблюдаются признаки переобучения: потери при проверке ниже, чем при обучении.
Для обнаружения защитных строительных масок в потоковом видео была использована архитектура OpenCV DNN вместе с предварительно обученной моделью MobileNet SSD V3 на основе каскадного классификатора для получения высокопроизводительных результатов. Оценку f1 используют в тех случаях, когда нужно иметь как хорошую точность, так и хорошую отзывчивость. Это указывает на то, что использование оценки f1 существенно, когда есть заинтересованность в получении наибольшего количества истинных положительных результатов, и при этом мы хотим быть более уверенными, что текущий прогноз верен.
Заключение
Целью исследования был анализ эффективности по распознаванию защитных строительных масок на лице работника в потоковом видео. В процессе обучения и проверки детектора в контролируемом состоянии был использован набор данных на основе общедоступного набора данных с лицами в масках и без них. Кроме того, в экспериментах были изучены такие показатели производительности, как средняя оценка частоты промахов по логарифму. На тестовом наборе получена точность ~99 %, при этом можно наблюдать, что есть небольшие признаки переобучения, при этом оптимизатор Adam показал потери при проверке ниже (0,3113), чем у SGM (0,3847). При этом полученные результаты показывают, что предлагаемая модельная схема OpenCV DNN + MobileNet SSD V3 с предварительно обученной конволюционной нейронной сетью (kCNN) для обнаружения лица в защитной строительной маске является эффективной моделью для обнаружения лица в защитной строительной маске. MobileNet V3 представляет собой значительное улучшение по сравнению с MobileNet V2, предлагая лучшую точность и скорость благодаря новым архитектурным решениям и оптимизациям. Эти улучшения делают MobileNet V3 предпочтительным выбором для мобильных и встроенных приложений, требующих высокой производительности и эффективности. Объединение в единую пространственную пирамиду (LR-ASP) позволяет достичь новых результатов в области мобильной классификации, обнаружения и сегментации. MobileNet V3-Large на 3,2 % точнее в классификации ImageNet при одновременном снижении задержки на 20 % по сравнению с MobileNet V2 и работает на 25 % быстрее, чем MobileNet V2 R-ASPP, при аналогичной точности сегментации.
В целом задачи исследования решены, полученные результаты подтверждают эффективность предлагаемой модели для обнаружения защитных строительных масок в потоковом видео, и можно надеяться, что она будет полезна для различных приложений в области строительства и безопасности труда.
Библиографическая ссылка
Эвиев В.А., Лиджи-Гаряев В.В., Бадрудинова А.Н., Гермашева Ю.С., Абушинов О.А. Детектирование защитных масок в промышленности в потоковом видео на модели MobileNet V3 SSD // Современные наукоемкие технологии. 2024. № 9. С. 62-68;URL: https://top-technologies.ru/ru/article/view?id=40149 (дата обращения: 15.06.2026).
DOI: https://doi.org/10.17513/snt.40149