



Задача оценки конспектов (изложений) является важной в учебном процессе, так как позволяет оценить способность обучающегося обобщать и структурировать полученную информацию. Такая форма контроля применяется повсеместно как в российских школах, так и в зарубежных. Однако процесс оценивания сложен в силу его трудоемкости, а также субъективности и наличия человеческого фактора. Поэтому возникает задача автоматизации процесса оценки конспекта с помощью современных технологий анализа данных с целью снижения нагрузки на преподавателей, а также улучшения процедуры оценивания работ обучающихся.
В статье отражены результаты анализа современного состояния проблемы автоматического анализа текста и его оценивания; вопросы подготовки обучающего набора данных к анализу, непосредственно анализа, выбора моделей для обучения, сравнительного анализа итоговых результатов и их интерпретации.
Русскоязычных исследований по данному вопросу немного, что связано с проблематичностью сбора обучающего набора данных для поставленной задачи. Следует отметить публикацию Э.В. Некрасовой, П.Ю. Гусева [1], в которой используется логистическая регрессия для оценки курсовых проектов по пояснительной записке. Среди работ зарубежных авторов также мало статей, посвященных данному вопросу, однако в 2023 году проводилось соревнование, на основании данных которого проводится исследование [2].
Обзорную статью с опросом относительно применения методов машинного обучения и обработки естественного языка (на английском Natural Language Processing, сокращенно NLP) в задачах оценки текстов опубликовали зарубежные авторы [3]. В частности, они рассматривают применяющиеся в данный момент архитектуры нейронных сетей для данной задачи, а также мнение преподавателей по данному вопросу. Также задачу автоматической оценки текстов изучали Димитриос Аликаниотис, Хелен Яннакудакис, Марек Рей [4]. В их работе делался упор на повышение интерпретируемости результатов с использованием сети Long short-term memory (LSTM), при этом результат работы модели визуализировался, и модель выводила список слов, за которые модель повышала или понижала оценку. Китайские авторы [5] также применяли LSTM для решения данной задачи, однако они использовали иерархическую модель нейронной сети, так как с помощью такого подхода можно более точно оценить работу за счет оценки вклада каждого отдельного предложения в итоговую оценку.
Анализ современного состояния проблемы позволил выявить отсутствие комплексных решений по оценке работ обучающихся на английском языке. Предлагаемое авторами решение на основе методов NLP поможет снизить нагрузку на преподавателя и добавить большей объективности при оценивании текстов.
Постановка задачи для данного исследования может быть сформулирована следующим образом: разработать модель для автоматической оценки конспектов учеников. На вход подаются исходный текст и конспект ученика. На выходе модель выдает две оценки: за содержание и за формулировку. Решение должно быть выполнено с использованием методов машинного обучения.
Целью данного исследования является разработка модели, которая способна оценивать конспекты/изложения на основе имеющегося изначально текста.
Для достижения поставленной цели необходимо поэтапно решить следующие задачи: сбор обучающего набора данных; анализ и предобработка данных; выбор моделей для обучения; сравнение итоговых результатов и их интерпретация. При решении задач обучения моделей и анализа данных будут использованы язык программирования Python, а также его библиотеки.
Материалы и методы исследования
Набор данных. В качестве данных для решения использовался датасет открытого соревнования по машинному обучению на платформе Kaggle, а именно CommonLit – Evaluate Student Summaries [2]. Датасет включает 24 000 изложений, написанных учениками 3–12-х классов на английском языке на 4 различные темы. Для обучения использованы таблицы summaries_train.csv (7165 строк и 5 столбцов) и prompts_train.csv (4 строки и 4 столбца), параметры которых описаны в таблицах 1 и 2 соответственно.
Используемые модели и методы. Для решения задачи оценки изложений было принято решение использовать линейную регрессию и градиентный бустинг. Выбор моделей обусловлен простотой их применения, а также высокой точностью (в частности, градиентный бустинг) в задачах регрессии. Линейная регрессия выбрана в качестве базового варианта решения задачи. Выбор обусловлен простотой обучения с возможностью аппроксимировать линейные зависимости.
Анализ исходных данных позволил представить результаты в виде круговых диаграмм и диаграмм размаха (рис. 1-4). Тексты по тематике (рис. 1) распределены относительно равномерно. Диаграммы размаха с оценками за содержание (рис. 2) и формулировку (рис. 3) демонстрируют схожесть распределения оценок в текстах.
Таблица 1
Описание входных и выходных данных таблицы summaries_train.csv
|
Параметр |
Обозначение |
|
Входные данные |
|
|
student_id |
Id ученика; целое число |
|
prompt_id |
Id задания; целое число |
|
text |
Текст конспекта ученика; строка |
|
Выходные данные |
|
|
content |
Оценка за содержание; вещ. число |
|
wording |
Оценка за формулировку; вещ. число |
Таблица 2
Описание входных и выходных данных таблицы prompts_train.csv
|
Параметр |
Обозначение |
|
Входные данные |
|
|
prompt_id |
Id задания; целое число |
|
prompt_question |
Текст вопроса, данного ученику; строка |
|
prompt_title |
Название текста, по которому ученик должен сделать конспект; строка |
|
prompt_text |
Текст, по которому ученик должен сделать конспект; строка |
Рис. 1. Распределение количества конспектов по заданиям
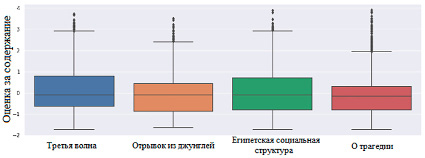
Рис. 2. Распределение оценки за содержание по каждому заданию
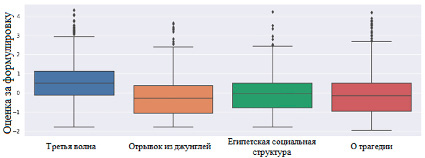
Рис. 3. Распределение оценки за формулировку по каждому заданию
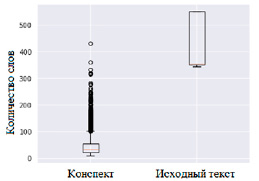
Рис. 4. Распределение количества слов в тексте у конспектов и исходного текста
На рисунке 4 представлены диаграммы распределения количества слов в сокращении и изначальном тексте. Результаты анализа, представленные визуально, показывают, что исходные данные пригодны для дальнейшего использования.
Предобработка данных. Перед обучением моделей необходимо представить текст в числовом формате, а также извлечь признаки. Для представления текста в виде числового вектора будут использоваться методы feature-engineering [6], TF-IDF [7], а также языковые модели, основанные на архитектуре BERT (RoBERTa [8], DeBERTa [9]).
В качестве дополнительных признаков будут извлекаться количество слов в конспекте и исходном тексте, количество стоп-слов в конспекте, а также количество биграм и триграм (последовательность двух/трех смежных элементов из строки), которые присутствуют как в конспекте, так и в исходном тексте. Для извлечения признаков из текста использована библиотека nltk [10]. Также к данным применяются стандартные техники обработки естественного языка: очистка от стоп-слов, лемматизация.
Во избежание утечки данных выборка будет разделяться по id задания: на первой итерации модели обучаются на конспектах по первым трем заданиям и проверяются на конспектах четвертого задания, и т.д.
Проведены эксперименты с использованием трех способов векторизации текста, а также двух методов регрессии. Для каждой целевой переменной обучены отдельные модели регрессии.
При оценке качества регрессии для каждого целевого признака рассчитываются метрика RMSE (среднеквадратическая ошибка), а также MCRMSE (средняя среднеквадратическая ошибка по столбцам) – среднее значение метрик RMSE для каждого целевого признака. Оценка модели производится с помощью кросс-валидации.
Результаты исследования и их обсуждение
Обучение моделей осуществлялось на признаках, полученных с помощью feature engineering. В результате обучения модель градиентного бустинга показала результат 0,63 MCRMSE, который превышает результаты модели линейной регрессии в 2,26 раза. Результаты экспериментального исследования с использованием векторизации TF-IDF показали, что значения MCRMSE для моделей значительно выросли (в 6 раз для линейной регрессии и в 4 раза для градиентного бустинга). Данный факт обусловлен тем, что при помощи создания новых признаков на основе имеющихся получилось добиться большей информативности по сравнению с использованием обычного TF-IDF.
На следующем шаге рассмотрены признаки, полученные с помощью языковых моделей. Использование признаков (модель RoBERTa) привело к снижению значения MCRMSE для модели линейной регрессии по сравнению с использованием вручную извлеченных признаков. Причем модель линейной регрессии показала себя лучше, чем градиентный бустинг на метриках MCRMSE и ContentRMSE.
На основе признаков модели DeBERTa полученные для моделей линейной регрессии и градиентного бустинга метрики снизились по сравнению с результатами, полученными на признаках модели RoBERTa. При этом итоговые метрики обеих моделей стали сопоставимы.
Таблица 3
Результаты экспериментальных исследований
|
Способ векторизации |
Модель |
Content RMSE, баллов |
Wording RMSE, баллов |
MCRMSE, баллов |
|
Feature engineering |
linreg |
1,02 |
3,49 |
2,26 |
|
catboost |
0,535 |
0,73 |
0,63 |
|
|
TF-IDF |
linreg |
11,8 |
14,36 |
13,08 |
|
catboost |
1,07 |
0,96 |
2,03 |
|
|
RoBERTa |
linreg |
0,71 |
0,85 |
0,78 |
|
catboost |
0,89 |
0,84 |
0,87 |
|
|
DeBERTa |
linreg |
0,58 |
0,72 |
0,65 |
|
catboost |
0,54 |
0,76 |
0,65 |
|
|
DeBERTa + feature engineering |
linreg |
0,58 |
0,72 |
0,65 |
|
catboost |
0,51 |
0,69 |
0,6 |
Объединение признаков, полученных с использованием модели DeBERTa, с признаками, извлеченными вручную, показало следующие результаты: для модели линейной регрессии (linreg) значение метрики не изменилось, а для градиентного бустинга значение метрик снизилось – MCRMSE на 7,7%, WordingRMSE на 9,2%, а ContentRMSE на 5,6%.
По результатам проведения кросс-валидации лучшее значение метрики MCRMSE было получено на модели градиентного бустинга (catboost), обученной на признаках из DeBERTa и признаках, которые были вручную извлечены из текста. Приведенные результаты отражены в таблице 3.
Результаты экспериментальных исследований показали, что применение заявленных методов возможно на практике. Однако для оценки формулировки можно рассмотреть и другие варианты моделей, для оценки смысловой схожести текстов модели позволили адекватно оценить работу учащегося.
Заключение
Экспериментальные исследования показали возможность применения технологий машинного обучения на практике, что может привести к снижению нагрузки на преподавательский состав и улучшить процесс оценивания работ. При этом необходимо провести ряд дополнительных исследований и экспериментов для повышения эффективности оценки конспектов/изложений учащихся.
Для развития темы можно добавить распознавание рукописного текста и уже на его основе производить оценку, так как в большинстве школ контроль такого рода проводится в рукописном формате, а не в электронном. Также можно собрать аналогичный набор данных на русском языке и сравнить влияние языка на итоговую оценку модели.
Библиографическая ссылка
Колотов М.А., Косачев И.С., Сметанина О.Н. МОДЕЛИ И МЕТОДЫ АНАЛИЗА ТЕКСТА В ЗАДАЧЕ ОЦЕНКИ КОНСПЕКТОВ ОБУЧАЮЩИХСЯ // Современные наукоемкие технологии. 2024. № 6. С. 25-29;URL: https://top-technologies.ru/ru/article/view?id=40059 (дата обращения: 14.06.2026).
DOI: https://doi.org/10.17513/snt.40059