



В настоящее время получение и анализ данных с веб-страниц являются неотъемлемой частью многих задач в области информационных технологий и бизнеса: финансовая аналитика (изучение котировок акций, новостей о компаниях, данных отчетности), академические исследования (получение данных опубликованных исследований, связанных с определенной тематикой), социальные медиа (изучение новостей, блогов, интернет-рекламы) [1–4].
Однако стандартные методы парсинга, например использование регулярных выражений или HTML-верстки кода страниц [5], могут быть недостаточно эффективными для решения следующих задач:
− получение данных с динамических веб-страниц. Большинство веб-страниц меняют свое содержимое с течением времени или в результате действий пользователя. При изменении содержимого страницы меняется и ее код. Это приводит к тому, что парсер «не видит» изменения и пропускает новые данные;
− классификация полученных данных. Классические парсеры работают на основе определенных форматов данных, что приводит к ограничениям в извлечении информации и последующем структурировании данных.
Технология парсинга с использованием нейросети и веб-драйвера позволит:
− повысить точность сбора данных за счет анализа динамически загружаемых элементов. Веб-драйвер способен эмулировать действия пользователя на веб-страницах (заполнение форм, щелчки по элементам, прокрутка страницы), тем самым предоставляя доступ к данным, не доступным через обычный HTTP-запрос;
− выполнить обработку данных сложной структуры. Парсинг, сочетаемый с возможностями нейросетей [6], может быть использован для поиска изображений, глубокого анализа текстов, записанных на естественном языке. Нейросеть способна помочь в извлечении значимых признаков собранных данных.
Цель исследования – создание десктопного приложения, осуществляющего парсинг данных с применением нейросети и алгоритма web-драйвера.
Задачи работы:
1) разработка алгоритма работы парсера;
2) проектирование архитектуры приложения;
3) реализация парсера на платформе .NET;
4) интеграция веб-драйвера в программный алгоритм парсера;
5) интеграция нейросети в программный алгоритм парсера;
6) разработка модуля фильтрации данных;
7) проектирование пользовательского интерфейса;
8) тестирование и внедрение приложения в риелторскую организацию.
Материал и методы исследования
Для реализации технологии были выбраны язык программирования C#, набор библиотек Selenium WebDriver и модель нейросети OpenAI ChatGPT 3.5 Turbo (табл. 1).
Selenium WebDriver – набор программных библиотек для автоматизации действий браузера, включающий:
− функции для работы с динамическими сайтами с технологиями AJAX, JavaScript;
− поддержку браузеров: Google Chrome, Firefox, Safari, Microsoft Edge, Opera и др.;
− простой и понятный API для автоматизации действий браузера;
− поддержку современных языков программирования, таких как Java, C#, Python, JavaScript.
Выбор ChatGPT 3.5 Turbo обусловлен следующими причинами:
− модель является одной из последних версий GPT от OpenAI, способной генерировать качественные и связные тексты. Все это позволяет использовать ее для обработки и генерации текстовых данных, полученных парсером [7];
− модель основана на непрерывном обучении от OpenAI, то есть продолжает улучшаться и получать обновления [8].
В качестве языка программирования выбран объектно-ориентированный язык C# платформы .NET, включающий:
− интеграцию с .NET Framework и .NET Core;
− набор библиотек, которые обеспечивают работу с веб-сервисами, обработку JSON, работу с базами данных.
Результаты исследования и их обсуждении
Технология парсинга данных с использованием нейросети и веб-драйвера была успешно использована при создании парсера для агентства недвижимости. Основные возможности парсера:
− поиск информации в объявлениях, размещенных в группах социальных сетей, по ключевым словам («продам», «сдам», «аренда», «квартира», «комната», «дом», «участок», «дача», «гараж»), по теме объявления (недвижимость);
− сохранение найденной информации в виде текстовых файлов следующей структуры: описание объявления, прикрепленные к объявлению изображения;
− определение ключевых характеристик объявления: тип жилья, количество комнат, наличие изображений;
− группировка файлов по ключевым характеристикам объявления.
Таблица 1
Инструменты, используемые для реализации технологии
|
Наименование инструмента |
Тип программного обеспечения |
Возможности |
|
Selenium WebDriver |
Бесплатный |
Широкая поддержка браузеров и языков программирования |
|
OpenAI ChatGPT 3.5 Turbo |
Условно бесплатный |
Генерация и классификация текста |
|
C# |
Бесплатный |
Широкий набор библиотек по работе с веб-сервисами и обработке данных |
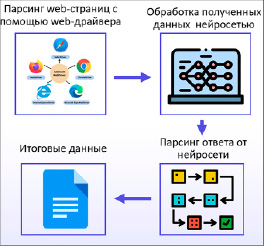
Рис. 1. Алгоритм работы парсера с веб-драйвером и нейросетью
На рисунке 1 представлен алгоритм работы парсера.
На первом этапе веб-драйвер открывает целевую веб-страницу, эмулирует действия пользователя, загружает все данные с веб-страницы, включая изображения и текстовое описание. Кроме того, веб-драйвер позволяет получать данные, обращаясь к HTML-элементам с помощью CSS-селекторов, XPath-запросов или названий классов HTML-элементов (рис. 2). За счет этого происходит возникновение событий в коде страницы (рис. 3), предоставляющих доступ к данным, недоступным при классическом парсинге.
Далее, на основе полученных данных, формируются запросы к нейросети, которая анализирует и классифицирует их по ключевым характеристикам – типу жилья, количеству комнат. Запросы представляют собой наборы данных, состоящих из следующих пар: «входные данные HTML-кода» и «ожидаемый результат» или «полученные данные из первичного HTML-парсинга» и «ожидаемый результат». Модель анализирует загруженный HTML-код или результат первичного парсинга и находит соответствующие элементы, которые нужно извлечь (рис. 4).
Заключительным этапом является процесс вторичного парсинга. На данном этапе происходят обращение к нейросети и извлечение данных, которые она смогла сконфигурировать. Извлечение происходит в более удобном формате, так как в данном случае парсер обращается к специальным тегам (классификаторам), заданным нейросетью, и получает структурированные данные (рис. 5). Результаты вторичного парсинга позволяют организовать хранение объявлений с группировкой по ключевым признакам.

Рис. 2. Фрагмент кода с извлечением текстового содержания объявления

Рис. 3. Метод, содержащий логику работы веб-драйвера при листинге страницы
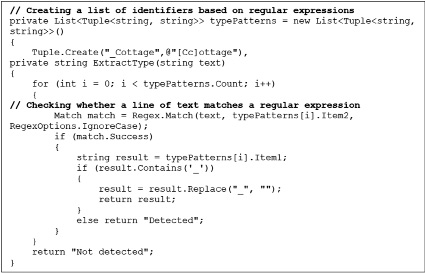
Рис. 4. Фрагмент кода для определения типа жилья в объявлении
Созданный парсер способен эффективно работать с фильтрами, извлекать и классифицировать данные из веб-страниц, в которых не предусмотрена строгая организация информации: блоги, социальные сети, чаты, сайты с объявлениями. Помимо агентств недвижимости, парсер может быть адаптирован к решению задач и в других областях, например в службах занятости населения, приемных комиссиях вузов.
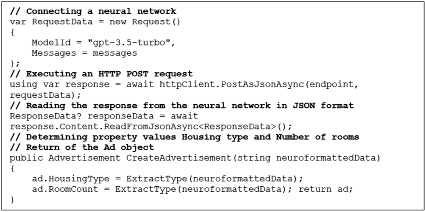
Рис. 5. Вторичный парсинг данных
Заключение
Описанный метод парсинга имеет ряд преимуществ:
− улучшенная обработка и анализ данных: обращение парсера к нейросети позволит распознавать и классифицировать текстовую и визуальную информацию, более точно анализировать и обрабатывать данные;
− расширенная функциональность: использование нейросети даст возможность расширить функциональность парсера, например выполнять семантический анализ текстов;
− повышение точности и надежности парсера: использование нейросети позволит улучшить точность извлечения данных из нерегулярных и сложных страниц, таких как веб-форумы или блоги, где структура данных менее предсказуема;
− работа с динамическими сайтами: если страница содержит динамические элементы, то использование веб-драйвера позволит более корректно обращаться с такими элементами и получать актуальные данные после их загрузки. Это особенно важно при парсинге страниц, при работе с которыми нужно ожидать загрузки элементов или выполнения определенных действий.
Работа выполнена при поддержке Краевого государственного автономного учреждения «Красноярский краевой фонд поддержки научной и научно-технической деятельности».
Библиографическая ссылка
Егармин П.А., Панов Р.Е., Ахматшин Ф.Г., Егармина А.П., Золотухина И.Т. ТЕХНОЛОГИЯ ПАРСИНГА ДАННЫХ С ПРИМЕНЕНИЕМ НЕЙРОСЕТИ И АЛГОРИТМА WEB-ДРАЙВЕРА // Современные наукоемкие технологии. 2024. № 5-1. С. 26-30;URL: https://top-technologies.ru/ru/article/view?id=40000 (дата обращения: 01.08.2026).
DOI: https://doi.org/10.17513/snt.40000