



В настоящее время разработка учебно-методических материалов для дисциплин высшего образования требует от преподавателя больших временных затрат, связанных с созданием набора разнообразных неповторяющихся вариантов для проверки усвоения студентами каждого модуля дисциплины. Особенно актуальной эта проблема становится для тех дисциплин, которые изучаются в одинаковом объеме и имеют сходное содержание для разных специальностей одного факультета. В частности, в Мордовском государственном университете на первом курсе медицинского института дисциплина «Введение в современные информационные и интеллектуальные технологии» изучается на специальностях «Лечебное дело», «Педиатрия», «Стоматология», «Фармация», при этом суммарный контингент обучающихся на 2023-2024 учебный год составляет порядка 800 человек. Таким образом, возникает необходимость автоматической генерации вариантов лабораторных работ по всем модулям данной дисциплины. При этом подобная генерация должна обеспечить уникальность получаемых вариантов для обеспечения самостоятельности выполнения обучаемыми лабораторного практикума.
Материалы и методы исследования
Разработкой различных способов и подходов, применяемых для автоматической генерации вариантов индивидуальных заданий, занимались многие отечественные исследователи. Так, в работе [1] предложена следующая классификация основ методов генерации: машинное обучение; нейронные сети; деревья; правила или шаблоны. Отдельное место в этой классификации занимают гибридные методы и подходы. При этом авторы для реализации вышеуказанных методов использовали как существующее программное обеспечение, так и собственные разработки с применением высокоуровневых языков программирования. В [2] предлагается использование R-project в качестве системы генерации вариантов заданий для проверочных работ по теории графов, при этом параметры, используемые в вариантах, задаются случайным образом, а допустимость полученного набора значений проверяется перед генерацией варианта. В [3] представлена собственная разработка автора – программное обеспечение Vargen, предназначенное для автоматизированной генерации вариантов заданий на курсовое проектирование по дисциплине «Моделирование систем». При этом генерация уникального варианта выполняется на основе порядкового номера обучающегося, что позволяет при утере студентом вариативных данных восстановить их в программе.
Новый метод генерации тестовых заданий, основанный на применении шаблона, использующего заданные преподавателем продукционные правила, предложен в [4]. Сгенерированные тесты импортируются в систему дистанционного обучения Moodle. Кроме того, возможности встроенного языка программирования вычисляемого вопроса Moodle позволяют проводить генерацию тестовых заданий, основываясь на декларативном принципе программирования [5].
Интересным представляется метод генерации тестов в виде «обратной задачи» [6], т.е. постановку задачи предлагается начинать не от задания, а от ответа. Метод семантического анализа текстов применяется в [7]. Этот метод формирует вопросы теста и варианты ответа на основе текстовых учебных материалов, при реализации метода используется библиотека RuWordNet и технология TextMining. В работе [8] исследовалась пригодность современных генеративных моделей для автоматического создания текстов учебных задач. Решение задачи конструирования разноуровневых заданий в фасетных учебно-информационных комплексах на основе фасетной классификации и облачных сервисов рассмотрено в [9].
В представленном исследовании предлагается технология генерации вариантов, основанная на применении языков веб-программирования и систем управления базами данных. Цель данного исследования состоит в описании указанной технологии применительно к лабораторному практикуму по ИТ-дисциплинам, включенным в учебный план медицинских специальностей вузов, оценке преимуществ данной технологии и её реализации в виде программно-информационной системы.
Данное исследование базируется на учебных планах медицинских специальностей Мордовского государственного университета, материалах учебных пособий по профильным медицинским дисциплинам. Основным методом исследования является графическое моделирование, результаты которого представлены в виде блок-схем и схемы данных базы данных. Для реализации предлагаемой технологии генерации вариантов были использованы следующие инструментальные средства: редактор кода Visual Studio Code, языки веб-программирования (HTML, PHP, JavaScript, CSS), система управления реляционными базами данных MySQL, локальный сервер Denwer.
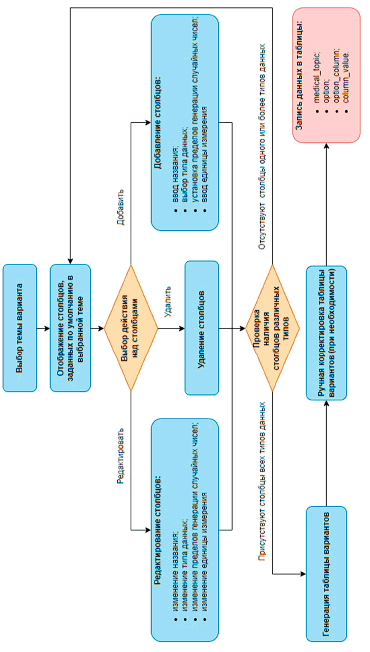
Рис. 1. Алгоритм генерации набора исходных данных варианта
Результаты исследования и их обсуждение
В рабочую программу дисциплины «Введение в современные информационные и интеллектуальные технологии» включен модуль «Применение Microsoft Excel для обработки и анализа медицинской информации». Данный модуль составляют 3 лабораторные работы: «Работа с формулами и функциями», «Построение диаграмм», «Сортировка и фильтрация данных». Все работы выполняются на основе одного набора входных данных, который содержит информацию, используемую в медицинских информационных системах. Набор включает 10-15 столбцов и не менее 15 строк, при этом столбцы должны содержать данные различных типов: текстовые данные (например, ФИО пациента), дата или время (например, дата направления на УЗИ), числовые данные (анатомические или физиологические характеристики). Генерацию требуемого набора данных обеспечивает алгоритм, схема которого представлена на рисунке 1.
Выбор темы варианта предполагает либо создание новой темы варианта, либо выбор одной из предлагаемых тем, например: «Анализ крови», «УЗИ внутренних органов», «Журнал вызовов скорой медицинской помощи», «Прививочная карта взрослого» и т.п. После выбора темы отображаются столбцы, используемые для данной темы по умолчанию. На рисунке 2 показан интерфейс пользователя для задания столбцов, которые будут входить в вариант на тему «УЗИ печени»; пользователь может выбрать предлагаемые по умолчанию столбцы, добавить собственные, а также удалить ненужные столбцы. Для каждого столбца необходимо задать название, тип данных, нижнюю и верхнюю границу для генерации случайных чисел, дат или времени, ввести или выбрать предлагаемые значения для столбцов, которые будут содержать текстовые данные.
Так как в варианте должны присутствовать столбцы различных типов данных, то после задания столбцов осуществляется проверка наличия среди них текстового, числового типов, а также типов даты или времени. При успешной проверке выполняется генерация или подстановка значений для каждого столбца (рис. 3). Пользователь может выполнить вручную корректировку сгенерированных данных, например для того, чтобы значения в каждом конкретном случае не противоречили известным данным анатомии и физиологии (нормальной и патологической), или для выделения случаев, имеющих определенную патологию у пациентов.
При сохранении варианта выполняется запись значений таблицы в базу данных Options, фрагмент схемы которой представлен на рисунке 4.
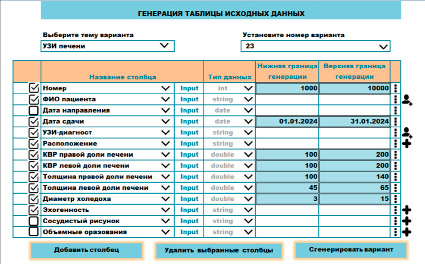
Рис. 2. Задание столбцов и их свойств для генерации исходных данных
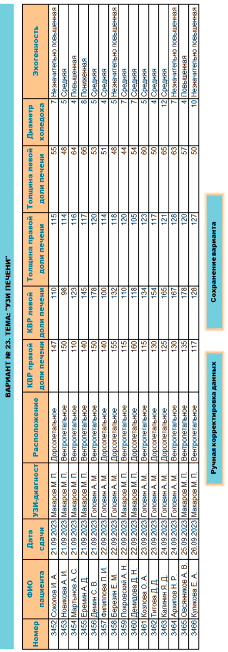
Рис. 3. Пример сгенерированного варианта
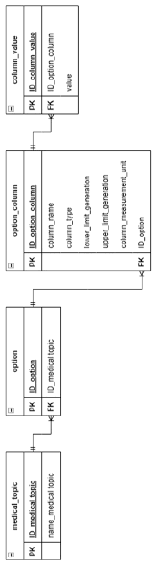
Рис. 4. Фрагмент схемы базы данных Options
Представленный фрагмент схемы содержит таблицы: medical_topic хранит данные о темах вариантов; option содержит номера вариантов с указанием темы, к которой относится каждый вариант; option_columns описывает каждый столбец варианта (название столбца, тип хранимых данных, нижний и верхний предел генерации значений для столбцов числового типа, а также дат и времени; единицу измерения данных столбца), column_value содержит данные, хранящиеся в каждом столбце варианта.
В лабораторной работе «Построение диаграмм» требуется построить 3 диаграммы:
1) круговую диаграмму, отображающую процентное соотношение количества значений выбранного числового показателя, попадающих в заданные диапазоны;
2) однорядную гистограмму, показывающую зависимость средних значений числового показателя, вычисленных для каждого уникального значения некоторого текстового параметра;
3) двухрядную гистограмму, визуализирующую количество значений показателя любого типа в распределении по двум параметрам.
Перед построением диаграммы необходимо провести предварительные расчеты величин, которые затем будут визуализированы на диаграммах.
Для генерации формулировок заданий на построение диаграмм был разработан алгоритм «Генерация диаграмм», представленный на рисунке 5.
Например, для диаграммы 1 был выбран случайным образом числовой столбец «Толщина левой доли печени», в диапазоне изменения значений которого были выделены числа 50 и 60. Проверка непустоты множеств, задаваемых условиями A1 (ТЛДП<50) = {44, 48, 48}, A2 (50≤ТЛДП≤60) = {50, 50, 51, 53, 54, 55, 57, 60}, A3 (ТЛДП>60) = {63,64,65,66}, прошла успешно, поэтому произошла генерация формулировки задания на построение круговой диаграммы и построен образец данной диаграммы, который должен получить студент в ходе выполнения задания. При написании формулировки задания используется фиксированная фраза: «Задание № 1. Построить круговую диаграмму о распределении пациентов по показателю *», в которой в качестве названия показателя используется имя выбранного столбца (рис. 6).
Для диаграммы 2 случайным образом был выбран столбец «Эхогенность», содержащий текстовые данные, а из оставшихся после выбора столбца для первой диаграммы числовых столбцов – столбец «Диаметр холедоха». Данные выбранных столбцов послужили основой для формулировки задания на построение гистограммы о средних значениях диаметра холедоха, рассчитанных для каждого значения эхогенности. Формулировка задания включает фразу «Задание 2. Построить гистограмму о среднем значении показателя * в распределении по показателю *», где вместо значка «*» используются имена столбцов (рис. 6).
Аналогично для диаграммы 3 выбираются 2 столбца из оставшихся после выбора столбцов для первой и второй диаграмм, для каждой пары уникальных значений из этих столбцов подсчитывается частота ее встречаемости, соответственно генерируется формулировка задания вида: «Задание 3. Построить гистограмму о распределении пациентов по показателям * и *» (рис. 6).
Хранение данных, необходимых для построения диаграмм, осуществляется в таблице «diagram», в которой первичным ключом является поле ID_option (номер варианта), затем идут значения number_1, number_2 и имена столбцов, участвующих в формулировках заданий. Таблица «diagram», её связи с ранее созданными таблицами, а также заполнение данной таблицы для диаграмм, представленных на рисунке 6, показаны на рисунке 7.
Лабораторная работа «Работа с формулами и функциями» включает 10 заданий на построение формул с применением встроенных функций Microsoft Excel для нахождения количества, минимального, среднего, максимального значений при выполнении некоторых условий на входные данные. Так, задания 1-3 требуют применения функций МАКС(), МИН(), СРЗНАЧ(); задания 4-6 – функции СЧЕТЕСЛИ(), задание 7 – функции СЧЕТЕСЛИМН(), задания 8-9 – функций СРЗНАЧЕСЛИ(), СРЗНАЧЕСЛИМН(), задание 10 – функции ЕСЛИ(). Для генерации формулировок заданий был разработан алгоритм «Генерация заданий на формулы и функции», представленный на рисунке 8.
Данный алгоритм должен обеспечить выполнение следующих требований:
1) формулировки задания должны охватывать все столбцы таблицы вариантов;
2) условия, входящие в функции ЕСЛИ(), СЧЕТЕСЛИ(), СЧЕТЕСЛИМН(), СРЗНАЧЕСЛИ(), СРЗНАЧЕСЛИМН(), должны задавать непустые множества записей таблицы вариантов.
Сохранение данных, необходимых для генерации формулировок заданий, осуществляется в таблицах «function» и «condition» (рис. 9).
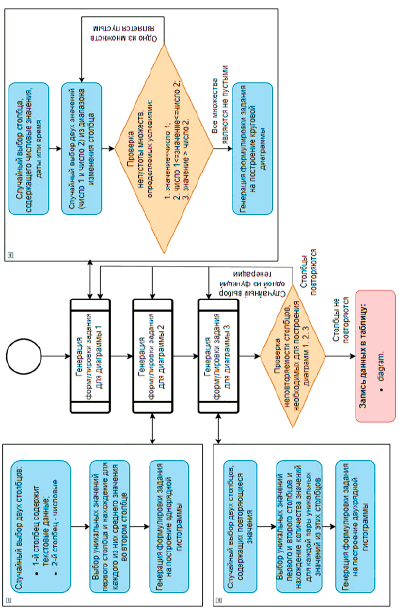
Рис. 5. Алгоритм «Генерация диаграмм»
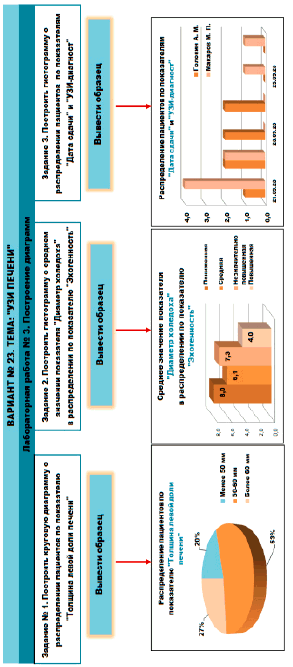
Рис. 6. Генерация формулировок заданий для построения диаграмм
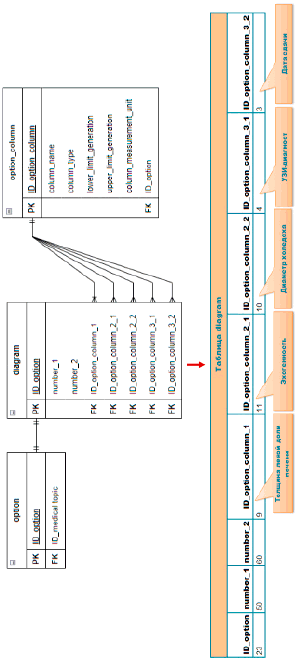
Рис. 7. Фрагмент схемы базы данных с таблицей «diagram» и пример ее заполнения
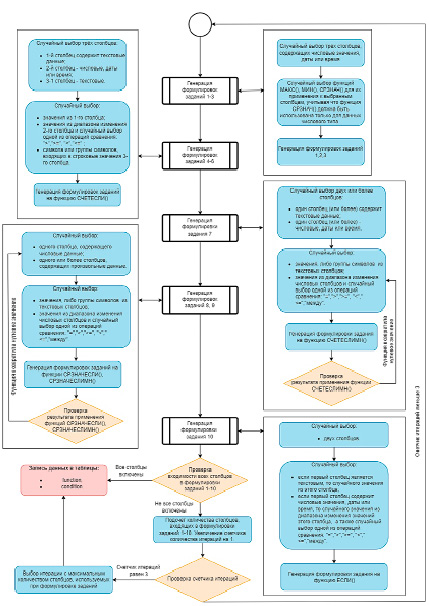
Рис. 8. Алгоритм «Генерация заданий на формулы и функции»
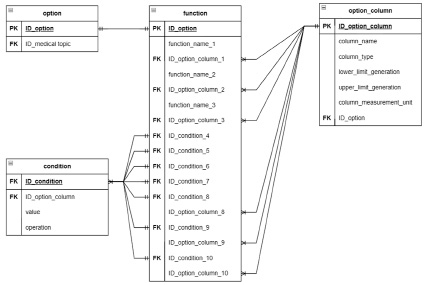
Рис. 9. Фрагмент схемы базы данных с таблицами «function» и «condition»

Рис. 10. Генерация формулировок заданий на применение формул и функций
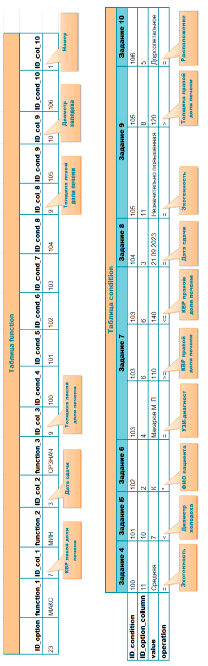
Рис. 11. Примеры заполнения таблиц «function» и «condition»

Рис. 12. Генерация формулировок заданий на сортировку и фильтрацию данных
Так, таблица «condition» содержит логические выражения, применяемые в заданиях на функции и включающие имена столбцов с наложенными на них условиями в формате «столбец – знак логической операции – значение». Данные этой таблицы используются при генерации заданий 4-10. Таблица «function» содержит:
− для заданий 1-3 имена встроенных функций Excel (МАКС(), МИН(), СРЗНАЧ()) и идентификаторы столбцов, к которым они применяются;
− для заданий 4-7 ключи на условия для функций СЧЕТЕСЛИ() и СЧЕТЕСЛИМН(), хранящиеся в таблице «condition»;
− для заданий 8-10 ключи на условия для функций СРЗНАЧЕСЛИ(), СРЗНАЧЕСЛИМН() и ЕСЛИ(), а также идентификаторы столбцов, для которых производится расчет средних значений или вывод значений, соответствующих заданным условиям.
Пример генерации формулировок заданий для лабораторной работы «Работа с формулами и функциями» представлен на рисунке 10.
Лабораторная работа «Сортировка и фильтрация данных» включает 11 заданий, предусматривающих выполнение базовых операций по одноуровневой и многоуровневой сортировке с использованием диалогового окна «Настраиваемая сортировка», фильтрации данных по нескольким полям с применением текстовых, числовых, настраиваемых фильтров, фильтров по дате и времени, а также опции «Дополнительно», позволяющей воспользоваться расширенными возможностями при задании условий фильтрации записей. Для генерации формулировок заданий был разработан алгоритм «Генерация заданий на сортировку и фильтрацию данных», аналогичный алгоритму, представленному на рисунке 8. Требования, предъявляемые к сгенерированным заданиям, остаются прежними:
1) задания должны охватывать все столбцы таблицы вариантов;
2) условия фильтрации записей должны задавать непустые множества записей таблицы вариантов.
Пример генерации формулировок заданий для лабораторной работы «Сортировка и фильтрация данных» представлен на рисунке 12.
Заключение
В статье рассматривается проблема автоматизации генерации вариантов заданий для лабораторных работ модуля «Применение Microsoft Excel для обработки и анализа медицинской информации», являющегося частью дисциплины «Введение в современные информационные и интеллектуальные технологии». Для каждой лабораторной работы приведена система входящих в неё заданий, на основе которой разработаны алгоритмы конструирования вариантов и определены структуры таблиц, входящих в базу данных для их хранения. Для реализации указанных алгоритмов и таблиц были использованы современные технологии управления базами данных и языки веб-программирования. Кроме того, в статье приведены примеры генерации заданий для варианта «УЗИ печени» для лабораторных работ «Сортировка и фильтрация данных», «Работа с формулами и функциями», «Построение диаграмм». Представлены формулировки сгенерированных заданий, выполняемых студентами в процессе изучения модуля, показана организация хранения в таблицах данных, полученных на основе этих формулировок.
Разработанная на основе этих алгоритмов программно-информационная система была применена в учебно-информационном комплексе, предназначенном для генерации вариантов, распределении их в академических группах, автоматизации проверки и оценивания полученных студентами результатов по вышеуказанному модулю дисциплины. Результаты её применения показали высокую эффективность при обеспечении учебного процесса необходимыми методическими материалами, связанную с накоплением базы проверочных материалов, что в свою очередь обеспечило минимизацию их возможных повторений при большом количестве обучаемых.
Библиографическая ссылка
Рябухина Е.А., Фирсова С.А. РАЗРАБОТКА ПРОГРАММНО-ИНФОРМАЦИОННОЙ СИСТЕМЫ ДЛЯ АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ ЗАДАНИЙ ЛАБОРАТОРНОГО ПРАКТИКУМА ПО ДИСЦИПЛИНЕ «ВВЕДЕНИЕ В СОВРЕМЕННЫЕ ИНФОРМАЦИОННЫЕ И ИНТЕЛЛЕКТУАЛЬНЫЕ ТЕХНОЛОГИИ» // Современные наукоемкие технологии. 2024. № 4. С. 69-82;URL: https://top-technologies.ru/ru/article/view?id=39975 (дата обращения: 12.07.2026).
DOI: https://doi.org/10.17513/snt.39975