



В современных научных исследованиях вычислительные кластеры играют большую роль, предоставляя высокопроизводительные ресурсы при решении сложных научных и инженерных задач [1, 2]. Однако для обеспечения эффективной и бесперебойной работы таких кластеров необходима специализированная система мониторинга [3], которая способна следить за различными параметрами их функционирования и своевременно предупреждать о нештатных ситуациях.
При этом мониторинг вычислительных кластеров выходит за рамки простого наблюдения, превращаясь в важную составляющую управления инженерной и вычислительной инфраструктурой. Эффективная система мониторинга позволяет оперативно выявлять потенциальные проблемы, оптимизировать распределение ресурсов, обеспечивать высокую производительность и стабильную работу кластеров за счет автоматического устранения части неисправностей.
В ходе вычислительных экспериментов возникает необходимость не только в использовании существующих вычислительных кластеров, но и в создании облачных (виртуализированных) [4]. Этот переход к облачным решениям обусловлен не только расширением требований к вычислительным мощностям, но и необходимостью обеспечения гибкости и масштабируемости вычислений. В связи с этим возникает неизбежная задача развертывания системы мониторинга, которая отвечала бы требованиям высокопроизводительных облачных кластеров. Выбор и тонкая адаптация системы мониторинга к имеющейся инфраструктуре становится важным компонентом успешной реализации облачной инфраструктуры, предоставляя не только полный контроль над состоянием кластера, но и обеспечивая инструменты для быстрого выявления и решения возможных проблем.
Существующие системы мониторинга не предоставляют готовых решений, которые были бы универсальными для развертывания в различных типах инфраструктур [3, 5]. Это ставит перед исследователями задачи не только инженерного, но и научно-технического характера. В число задач входит разработка критериев сбора и хранения метрик состояния кластера, а также алгоритмов для определения аномалий в текущем состоянии, прогнозирование и устранение неисправностей, анализ больших объемов данных, использование методов машинного обучения для предсказания возможных сбоев, а также разработку новых подходов к автоматизированному реагированию на изменения в инфраструктуре.
С целью решения озвученных выше проблем ведется разработка модульной системы мониторинга, ориентированной на специфику различных типов инфраструктур и требования к современным системам мониторинга. В статье представлена архитектура такой системы, обеспечивающей мониторинг облачных ресурсов, вычислительных кластеров и их инженерного оборудования.
Материалы и методы исследования
Характерной особенностью вычислительного кластера по сравнению с облачной средой является более локализованная и высокооптимизированная инфраструктура. В отличие от облачных вычислений, которые предоставляют вычислительные ресурсы через интернет, кластер может быть развернут внутри организации. Это может быть обусловлено рядом причин, в том числе и с позиций информационной безопасности. С другой стороны, кластеры являются менее гибкими и масштабируемыми по сравнению с облачными средами, где ресурсы могут моментально добавляться в зависимости от потребностей пользователей [4]. Другой важной чертой кластера является способ организации совместной работы через систему очередей заданий с использованием менеджера ресурсов, в то время как облачные ресурсы выделяются по запросу пользователя в монопольное пользование.
В ходе исследований методов интеграции облачных систем в гетерогенную вычислительную среду был предложен подход к представлению вычислительных заданий пользователей в виде расширенного описания, содержащего спецификацию и требования к контейнеру или виртуальной машине [6], запускаемых в облачной среде. Кроме того, ранее в работе [7] был представлен подход к классификации заданий пользователей для их распределения на более подходящие ресурсы. Таким образом была организована гетерогенная распределенная вычислительная среда, но без единой системы контроля за ее состоянием.
Как правило, мониторинг включает в себя широкий спектр операций, таких как наблюдение, анализ и поддержание работоспособности системы, процессов или предоставляемых услуг. Кроме того, он может охватывать мониторинг производительности, безопасности, доступности и других параметров. Набор этих параметров, а также их полнота определяются на основе экспертного опыта системных администраторов ресурсов и их технических возможностей по предоставлению информации о своем текущем состоянии.
В области мониторинга существует обширный набор различных технологий и программных систем, предназначенных для эффективного наблюдения, анализа и оценки аспектов наблюдаемых систем и процессов [8], таких как Zabbix, Nagios, Ganglia. Подобные в большей степени пригодны для мониторинга отдельных серверов, для кластерных систем существует более современная система NetData [9], но и ее эффективность на крупных кластерных системах не нашла подтверждения, несмотря на обширный набор собираемых метрик. С целью решения проблемы мониторинга гетерогенной вычислительной среды предложена архитектура прототипа системы мониторинга (рис. 1), которая обеспечивает доступ к мониторингу как классических кластеров и их инфраструктуры, так и облачных ресурсов.
Пользователям предоставляется веб-ориентированный доступ для отображения текущего состояния вычислительной среды в виде таблиц, диаграмм, графиков и т.д. Кроме того, реализована поддержка интерфейса командной строки (CLI) в браузере для выполнения SQL-подобных запросов на языке PromQL для работы с необходимыми метриками. Для обеспечения доступа к состоянию вычислительной среды внешним системам, например средствам управления вычислениями, реализован соответствующий API для поддержки как REST, так и SOAP сервисов. Через этот API представляются актуальные сведения о загрузке ресурсов, что позволяет повысить эффективность распределения потоков заданий между узлами среды. С другой стороны, API обеспечивает доступ к ретроспективным данным мониторинга для их применения в специализированных системах моделирования работы вычислительных сред.
Доступ к определенным видам метрик определяется политиками групп доступа через службу LDAP. За проверку доступа через LDAP и маршрутизацию запросов отвечает реверс-прокси сервер на базе Traefik. В изолированной сети Traefik осуществляет запросы к остальным подсистемам.
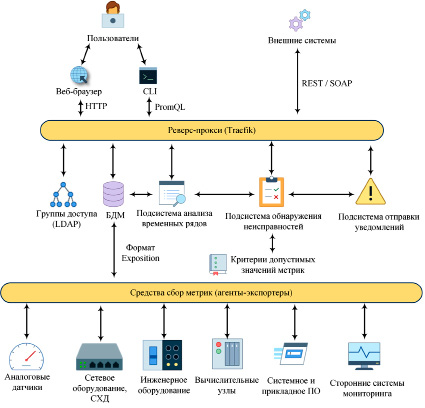
Рис. 1. Архитектура системы мониторинга
Эти подсистемы получают данные из базы данных метрик (БДМ) (реляционных, объектных и других специализированных баз данных). Формат хранения метрик определяется критериями БДМ и ориентирован на представление в виде временных рядов. В качестве БДМ выбрана система Prometheus, которая является в настоящее время индустриальным стандартом для сбора и хранения метрик [10]. Также Prometheus обеспечивает сжатие данных и быстрый доступ к ним на языке запросов PromQL.
В свою очередь за наполнение БДМ отвечает комплекс средств сбора метрик (агентов-экспортеров), которые выгружают специализированный набор метрик из вычислительной среды и конвертируют их в формат хранения БД метрик. Вычислительная среда включает в себя вычислительные и управляющие ресурсы (физические узлы и облачные), сетевую инфраструктуру (сервисные и управляющие сети, коммутаторы Ethernet и InfiniBand), системы хранения данных (СХД), инженерную инфраструктуру, системное и прикладное программное обеспечение (ПО), вычислительные задания пользователей.
При таком модульном подходе первостепенной задачей является определение набора собираемых метрик и разработка (настройка) агентов-экспортеров. Агент-экспортер является отдельной службой, доступ к которой осуществляется через HTTP-запросы (API). Он может быть как частью системы, поддерживаемой БДМ, так и работающим независимо. Отдельный экспортер позволяет реализовать сбор данных с датчиков устройств (температуры, влажности, напряжения, оборотов вентиляторов и т.д.), работающих по специализированным протоколам (UART или через GPIO), в том числе и аналоговым. В качестве платформы для сбора данных может быть использован микрокомпьютер [11], например Raspberry Pi или Arduino. Аналогично мониторингу аппаратных средств, с помощью экспортеров выполняется сбор данных о приложениях, контейнерах и виртуальных машинах.
Каждый экспортер зарегистрирован в БДМ для обеспечения сбора данных из него. Регистрация экспортеров возможна в автоматическом режиме, поэтому такой подход применим как для мониторинга статичных сущностей кластера, так и ресурсов облачной среды. В нашей системе мониторинга реализуется сбор метрик с вычислительных узлов, контейнеров и виртуальных машин с помощью Node Exporter [5, 9] и NetData. Они обеспечивают гибкую конфигурацию набора метрик, собираемых с узлов (загрузка и частота процессора, загрузка оперативной памяти, загрузка скорости сети и дисков, сетевые задержки, промахи кэша и т.д.) и их гранулярность. Сенсоры системы электропитания, вентилирования и охлаждения кластера имеют собственные протоколы и текстовые форматы представления данных, для них реализованы соответствующие экспортеры на языке Node.js. Все экспортеры по запросу БДМ отправляют данные в формате Exposition (Листинг).
В Листинге представлены следующие поля источника бесперебойного питания (ИБП):
− ups_battery_charge – гистограмма, представляющая уровень заряда батареи ИБП;
− ups_input_voltage – гистограмма, представляющая входное напряжение ИБП;
− ups_output_voltage – гистограмма, представляющая выходное напряжение ИБП;
− ups_load_percentage – гистограмма, представляющая загрузку ИБП в процентах от его емкости;
− ups_status – гистограмма, представляющая операционный статус ИБП (0 – OK, 1 – Предупреждение, 2 – Критическое состояние).
# HELP ups_battery_charge Battery charge level of the UPS
# TYPE ups_battery_charge gauge
ups_battery_charge{ups_id="ups1"} 92.5
# HELP ups_input_voltage Input voltage provided to the UPS
# TYPE ups_input_voltage gauge
ups_input_voltage{ups_id="ups1"} 230.5
# HELP ups_output_voltage Output voltage provided by the UPS
# TYPE ups_output_voltage gauge
ups_output_voltage{ups_id="ups1"} 220.0
# HELP ups_load_percentage UPS load as a percentage of its capacity
# TYPE ups_load_percentage gauge
ups_load_percentage{ups_id="ups1"} 35.7
# HELP ups_status UPS operational status (0 – OK, 1 – Warning, 2 – Critical)
# TYPE ups_status gauge
ups_status{ups_id="ups1"} 0
Листинг. Пример данных в формате Exposition от системы электропитания
Каждая метрика имеет уникальный идентификатор (ups_id), который может использоваться для идентификации конкретных ИБП в системе. Эти метрики могут быть использованы БДМ для мониторинга и анализа работы системы бесперебойного электропитания.
Следующим компонентом системы мониторинга является комплекс визуализации метрик и отправки уведомлений администратору вычислительной системы. В нашей системе мониторинга используется система Graphana [9], которая наряду с Prometheus является стандартизированным решением [10]. Graphana имеет встроенную поддержку метрик из Prometheus, что позволяет использовать единую точку мониторинга вычислительной инфраструктуры в виде приборной панели. Приборная панель является инструментом для группировки метрик и настройки способа их представления (тепловые карты, гистограммы, шкалы и т.д.). Для каждой задачи визуализации (общее состояние кластера, состояние конкретного узла, загрузка сети, состояние инженерной инфраструктуры) администратор создает отдельную приборную панель. Кроме того, в Graphana выполняется формирование набора наблюдаемых метрик и их пороговых значений, конфигурирование методов отправки оповещений через e-mail, SMS и системы мгновенного обмена сообщениями.
Отличительной особенностью Graphana от других подобных систем является поддержка создания сложного набора правил для определения неисправностей. Система создания правил является достаточно гибкой и позволяет описывать нестандартные ситуации, которые могут привести к сбою. В правилах имеется поддержка описания зависимостей между группами метрик. Однако создание таких правил требует экспертных знаний системных администраторов. В качестве инструментального средства для расширенного анализа метрик (выполнение запросов и фильтрация на языке PromQL, применение алгоритмов анализа временных рядов) системными администраторами разработан соответствующий JupierNotebook на языке Python. Из JupiterNotebook выполняется вызов сервисов и библиотек [12, 13] для многокритериального анализа временных рядов, получаемых в результате выполнения запросов на языке PromQL из БДМ.
Результаты исследования и их обсуждение
На основе выбранных технологий и экспертного опыта администрирования вычислительных кластеров, а также с учетом требований новых вычислительных задач был разработан прототип системы мониторинга гетерогенной вычислительной (облачных и кластерных ресурсов) и инженерной инфраструктур. В процессе интеграции существующих инженерных систем разработаны экспортеры для сбора наиболее важных метрик их состояния. Данные экспортеры были зарегистрированы в БДМ и полученные метрики были успешно визуализированы с помощью Graphana. Также проведена настройка приборной панели мониторинга администратора, что обеспечило единую точку мониторинга ключевых компонентов вычислительной среды (рис. 2). Проведено тестирование системы оповещений и отправки уведомлений, что в целом подтверждает работоспособность прототипа и позволяет продолжить его разработку.
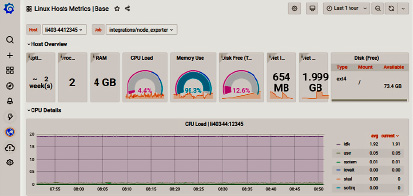
Рис. 2. Интерфейс приборной панели системы Graphana
Заключение
В статье представлены подход и архитектура разрабатываемой системы мониторинга гетерогенной вычислительной среды. Представлены основные компоненты и особенности их реализации. В настоящее время ведется активная разработка специализированных экспортеров и их интеграция с БДМ. Кроме того, продолжаются исследования, связанные с применением методов искусственного интеллекта для обнаружения аномалий во временных рядах метрик, а также методов обнаружения и исправления сбоев. В качестве обучающей выборки для нейронной сети выступят ретроспективные данные мониторинга, хранимые в БДМ. На основе этих данных планируется выполнить разметку с указанием нештатных ситуаций. Предполагается, что методы искусственного интеллекта позволят обнаруживать корреляции и взаимосвязи между временными рядами метрик и смогут прогнозировать аварийные ситуации заранее, что даст возможность провести профилактические мероприятия. Как следствие, это увеличит эффективность функционирования вычислительной среды, ее отказоустойчивость и надежность.
Прототип новой системы мониторинга функционирует параллельно с уже существующей системой мониторинга кластера для обеспечения преемственности разработок. Этот подход позволяет поэтапно внедрять и проверять новые возможности, снижая воздействие на текущую эксплуатацию кластера.
Библиографическая ссылка
Костромин Р.О. Особенности реализации системы мониторинга гетерогенной вычислительной среды // Современные наукоемкие технологии. 2023. № 12-2. С. 264-269;URL: https://top-technologies.ru/ru/article/view?id=39892 (дата обращения: 21.06.2026).
DOI: https://doi.org/10.17513/snt.39892