



Аппарат математического программирования на сегодняшний день успешно применяется для отбора наиболее информативных регрессоров (ОИР) в регрессионных моделях. В зарубежной литературе такая процедура известна как «feature selection», «subset selection» и т.д. При этом в иностранных источниках задача ОИР в основном сводится к задаче частично-булевого квадратичного программирования (ЧБКП). Одна из первых таких формализаций для линейных регрессий, оцениваемых с помощью метода наименьших квадратов (МНК), была представлена в [1]. В [2] сформулирована задача ОИР на основе скорректированного коэффициента детерминации и информационных критериев Акаике и Шварца, в [3] – на основе критерия Мэллоуза, в [4] – на основе критериев среднеквадратичных и абсолютных ошибок, в [5] – на основе критерия кросс-валидации. В [6] исследуется целостная линейная регрессия, для которой сформулирована задача ОИР с ограничениями на значимость коэффициентов и степень мультиколлинеарности, а в [7] осуществляется так называемая регрессионная диагностика с использованием линейных ограничений на наблюдаемые значения t-критерия Стьюдента. В [8] сформулирована задача ОИР для устранения мультиколлинеарности с помощью факторов «вздутия» дисперсии, в [9] разработан алгоритм для решения задачи максимизации канонической корреляции, а в [10] сформулирована задача для выявления уравнений сложных динамических систем.
В [11–14] автором предложены различные формализации задачи ОИР в линейной регрессии, оцениваемой с помощью МНК, в виде задач частично-булевого линейного программирования (ЧБЛП). Для контроля мультиколлинеарности в [11] использованы ограничения на факторы «вздутия» дисперсии. Однако этих ограничений недостаточно для того, чтобы гарантировать отсутствие значимой корреляции абсолютно между всеми парами объясняющих переменных, что необходимо для корректного объяснения полученных с помощью МНК оценок.
Цель исследования состоит в формализации задачи ОИР для линейной регрессии, оцениваемой с помощью МНК, в виде задачи ЧБЛП с линейными ограничениями на корреляции объясняющих переменных (интеркорреляции).
Материалы и методы исследования
Модель множественной линейной регрессии имеет вид
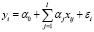 , i = 1,n, (1)
, i = 1,n, (1)
где yi, i = 1,n – значения объясняемой (зависимой) переменной y; xij, i = 1,n, j = 1,l – значения l объясняющих (независимых) переменных x1, x2,…, xl; n – объем выборки; αj, j = 0,l – неизвестные параметры; εi, i = 1,n – ошибки аппроксимации.
Задача ОИР для модели (1), оцениваемой с помощью МНК, формулируется следующим образом: необходимо из l объясняющих переменных выбрать m наиболее информативных так, чтобы либо сумма квадратов остатков модели была минимальна, либо коэффициент детерминации R2 был максимален.
Проведем нормирование (стандартизацию) всех переменных по правилам:
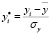 ,
, 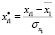 , ...,
, ..., 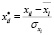 ,
,
i = 1,n,
где 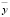 ,
, 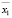 , …,
, …, 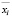 – средние значения переменных,
– средние значения переменных, 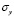 ,
, 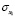 , …,
, …, 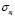 – среднеквадратические отклонения переменных.
– среднеквадратические отклонения переменных.
Составим модель стандартизованной линейной регрессии:
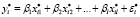 , i = 1,n, (2)
, i = 1,n, (2)
где β1, …, βl – неизвестные параметры; 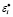 , i = 1,n – ошибки аппроксимации.
, i = 1,n – ошибки аппроксимации.
МНК-оценки стандартизованной регрессии (2) находятся по формуле
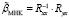 ,
,
где  – матрица
– матрица
интеркорреляций;
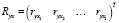 – вектор корреляций объясняющих переменных с y.
– вектор корреляций объясняющих переменных с y.
В [14] сформулирована следующая задача ЧБЛП для ОИР в модели (2):
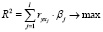 (3)
(3)
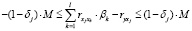 ,
,
j = 1,l, (4)
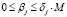 , j ∈ J+, (5)
, j ∈ J+, (5)
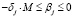 , j ∈ J–, (6)
, j ∈ J–, (6)
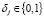 , j = 1,l, (7)
, j = 1,l, (7)
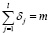 , (8)
, (8)
в формуле (8) 
M – большое положительное число, J+ и J– – сформированные из множества 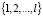 индексные подмножества, элементы которых удовлетворяют условиям
индексные подмножества, элементы которых удовлетворяют условиям 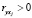 и
и 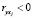 .
.
Решение задачи ЧБЛП (3)–(8) приводит к построению оптимальной по критерию R2 линейной регрессии с m объясняющими переменными, в которой знаки коэффициентов согласованы со знаками соответствующих корреляций вектора Rxy. Для того чтобы можно было объяснить полученные оценки, еще до решения задачи (3)–(8) необходимо исключать все объясняющие переменные, противоречиво коррелирующие с y. Для объяснения необходимо использовать МНК-оценки модели (1), связанные с МНК-оценками регрессии (2) формулами
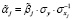 , j = 1,l,
, j = 1,l,
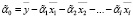 .
.
Пусть множество Ф содержит номера отобранных переменных. Поскольку для оцененной линейной регрессии выполняются условия 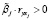 , j ∈ Ф, то становятся справедливыми следующие формулы для абсолютных вкладов переменных в общую детерминацию R2:
, j ∈ Ф, то становятся справедливыми следующие формулы для абсолютных вкладов переменных в общую детерминацию R2:
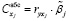 , j ∈ Ф.
, j ∈ Ф.
С помощью этих коэффициентов можно контролировать степень влияния любой объясняющей переменной на y. Поэтому в [14] было предложено в задаче (3)–(8) заменить линейное ограничение (8) на следующее:
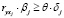 , j = 1,l (9)
, j = 1,l (9)
где θ ≥ 0 – назначенный исследователем наименьший вклад входящих в модель объясняющих переменных в общую детерминацию R2. Чем выше значение θ, тем больше переменных «выдавливается» из модели, следовательно, регрессия становится проще и снижается эффект мультиколлинеарности.
Таким образом, решение задачи ЧБЛП (3)–(7), (9), приводит к построению линейной регрессии с оптимальным по критерию R2 количеством объясняющих переменных, в которой 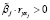 , j ∈ Ф, и вклады
, j ∈ Ф, и вклады 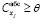 , j ∈ Ф.
, j ∈ Ф.
Для контроля в оптимизационной задаче ОИР абсолютных величин интеркорреляций введем следующие линейные ограничения:
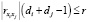 ,
, 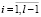 ,
, 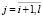 ,(10)
,(10)
где 0 ≤ r ≤ 1 – назначенная исследователем наибольшая величина абсолютных интеркорреляций входящих в модель объясняющих переменных. Если r = 0, то в построенной регрессии все интеркорреляции должны быть равны 0, а если r = 1, то нет ограничений на величины интеркорреляций в оцененной модели.
Если в ограничении (10) 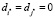 , что означает, что ни i*-я, ни j*-я переменная не входят в регрессию, то оно принимает вид
, что означает, что ни i*-я, ни j*-я переменная не входят в регрессию, то оно принимает вид 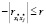 , поэтому справедливо всегда. Если в ограничении (10) либо
, поэтому справедливо всегда. Если в ограничении (10) либо 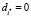 ,
, 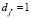 , либо
, либо 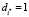 ,
, 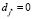 (в модель входит либо i*-я, либо j*-я переменная), то оно принимает вид 0 ≤ r, поэтому справедливо всегда. Если же в ограничении (10)
(в модель входит либо i*-я, либо j*-я переменная), то оно принимает вид 0 ≤ r, поэтому справедливо всегда. Если же в ограничении (10) 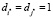 (в модель входит и i*-я, и j*-я переменная), то оно принимает вид
(в модель входит и i*-я, и j*-я переменная), то оно принимает вид 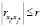 . В последнем случае, если
. В последнем случае, если 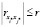 выполняется, то i*-я и j*-я переменные могут входить в модель одновременно, а если не выполняется, то нет.
выполняется, то i*-я и j*-я переменные могут входить в модель одновременно, а если не выполняется, то нет.
Заметим, что общее число ограничений (10) может быть сокращено. Действительно, если 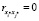 , то ограничение (10) выполняется для любых значений бинарных переменных. Аналогично, если
, то ограничение (10) выполняется для любых значений бинарных переменных. Аналогично, если 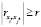 . Тогда ограничения (10) следует переписать в виде
. Тогда ограничения (10) следует переписать в виде
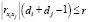 ,
,
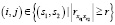 (11)
(11)
Таким образом, решение задачи ЧБЛП (3)–(7), (9), (11) приводит к построению линейной регрессии с оптимальным по критерию R2 количеством объясняющих переменных, в которой 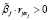 , j ∈ Ф, вклады
, j ∈ Ф, вклады 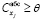 , j ∈ Ф, и интеркорреляции
, j ∈ Ф, и интеркорреляции 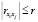 , i, j ∈ Ф, i < j.
, i, j ∈ Ф, i < j.
Предложенные ограничения (11) на величины интеркорреляций могут быть использованы для формализации задачи кластеризации корреляционной матрицы. Эта задача может быть сформулирована следующим образом: необходимо из l объясняющих переменных выбрать как можно больше переменных так, чтобы все их интеркорреляции не превосходили числа r.
Эта задача может быть формализована в виде задачи булевого линейного программирования (БЛП) с целевой функцией
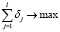 (12)
(12)
и линейными ограничениями (7), (11).
Ее решение позволяет сформировать кластер слабо коррелирующих объясняющих переменных (КСКП).
Аналогично можно сформулировать задачу отбора из l объясняющих переменных наибольшего числа переменных так, чтобы все их интеркорреляции были не меньше числа r. Она формализуется в виде задачи БЛП с целевой функцией (12), линейными ограничениями (7) и
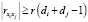 ,
,
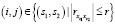 (13)
(13)
Решение задачи (12), (7), (13) позволяет сформировать кластер высоко коррелирующих объясняющих переменных (КВКП).
Заметим, что сформулированные задачи БЛП могут иметь несколько оптимальных решений.
Результаты исследования и их обсуждение
Для тестирования предложенного математического аппарата были использованы встроенные в эконометрический пакет Gretl статистические данные о зарплатах игроков НБА (data7-20.gdt). Для удобства были исключены все фиктивные переменные и составлена выборка из первых 30 наблюдений для зависимой переменной SALARY и оставшихся 17 объясняющих переменных. Для решения оптимизационных задач использовался решатель LPSolve IDE на персональном компьютере с 4-ядерным процессором (3100 МГц) и оперативной памятью 4 Гб. Для заданного числа r решалась задача ЧБЛП (3)–(7), (11) (без ограничений на вклады), задача БЛП (12), (7), (11) и задача БЛП (12), (7), (13). Для удобства назовем их задача A, задача B и задача C соответственно. В результате решения задачи A фиксировались номера отобранных переменных, время решения t в секундах и коэффициент детерминации R2. А в результате решения задач B и C фиксировалось число отобранных переменных m и время решения t. Результаты тестирования представлены в таблице. Большое число M для решения задачи A выбиралось так, как это предложено делать в [14].
По таблице видно, что LPSolve IDE справился со всеми задачами практически мгновенно. Как и ожидалось, при решении задачи A с уменьшением числа r, т.е. с ужесточением требования на объясняющие переменные с высокими интеркорреляциями, число отобранных переменных в линейной регрессии снижается. При этом также снижается время решения задачи и значение коэффициента детерминации. А время решения задач B и С практически не менялось в зависимости от выбранных значений r. При этом в задаче B с уменьшением r объем кластера слабо коррелирующих переменных уменьшался, а в задаче C объем кластера высоко коррелирующих переменных увеличивался. Полученные результаты подтверждают корректность предложенного математического аппарата.
Заключение
В результате проведенных исследований сформулирована задача ЧБЛП, решение которой приводит к построению линейной регрессии с оптимальным по критерию R2 числом объясняющих переменных, в которой знаки оценок согласуются со знаками соответствующих коэффициентов корреляции 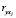 , абсолютные вклады переменных не меньше числа θ, а интеркорреляции не превосходят числа r. Построенная регрессионная модель гарантированно может быть интерпретирована, если на начальном этапе были исключены все противоречиво коррелирующие с y объясняющие переменные.
, абсолютные вклады переменных не меньше числа θ, а интеркорреляции не превосходят числа r. Построенная регрессионная модель гарантированно может быть интерпретирована, если на начальном этапе были исключены все противоречиво коррелирующие с y объясняющие переменные.
Результаты решения задач
|
r |
Задача A |
Задача B |
Задача C |
||||
|
Номера переменных |
t |
R2 |
m |
t |
m |
t |
|
|
0,9 |
2, 3, 6, 8, 9, 11, 12, 13, 14, 15, 17 |
1,481 |
0,5854 |
14 |
0,013 |
2 |
0,025 |
|
0,8 |
2, 3, 5, 9, 11, 12, 13, 14, 15, 17 |
1,217 |
0,5556 |
12 |
0,015 |
3 |
0,051 |
|
0,7 |
3, 5, 9, 11, 12, 13, 14, 15, 17 |
0,791 |
0,5413 |
10 |
0,021 |
4 |
0,031 |
|
0,6 |
4, 6, 9, 12, 13, 15, 17 |
0,557 |
0,4626 |
9 |
0,021 |
5 |
0,032 |
|
0,5 |
4, 5, 9, 12, 13, 15, 17 |
0,402 |
0,4438 |
8 |
0,025 |
7 |
0,027 |
|
0,4 |
4, 5, 9, 13, 15, 17 |
0,235 |
0,4233 |
6 |
0,032 |
7 |
0,023 |
|
0,3 |
4, 5, 15, 17 |
0,206 |
0,2841 |
5 |
0,036 |
8 |
0,021 |
|
0,2 |
4, 15, 17 |
0,155 |
0,2050 |
3 |
0,042 |
9 |
0,023 |
|
0,1 |
4, 15, 17 |
0,095 |
0,2050 |
3 |
0,027 |
10 |
0,016 |
Помимо этого разработанные линейные ограничения на интеркорреляции позволили сформировать задачи БЛП для построения кластеров слабо и высоко коррелирующих переменных. Первый из них способствует построению традиционных моделей множественной линейной регрессии, а второй – моделей полносвязной линейной регрессии, в которых все объясняющие переменные связаны между собой. В дальнейшем планируется провести тестирование предложенного математического аппарата для построения регрессионных моделей по выборкам большого объема.
Библиографическая ссылка
Базилевский М.П. Формализация процесса отбора информативных регрессоров в линейной регрессии в виде задачи частично-булевого линейного программирования с ограничениями на коэффициенты интеркорреляций // Современные наукоемкие технологии. 2023. № 8. С. 10-14;URL: https://top-technologies.ru/ru/article/view?id=39723 (дата обращения: 23.07.2026).
DOI: https://doi.org/10.17513/snt.39723