



В условиях BANI-мира (акроним от английских слов: «хрупкий», «тревожный», «нелинейный» и «непонятный»), сложившегося в результате развития Индустрии 4.0, и становления шестого технологического уклада, требуются новые подходы к управлению компаниями, основанные на активном использовании новых бизнес-моделей и инновационных цифровых технологий. Задача цифровой трансформации экономики и увеличения темпов экономического развития страны актуальна как никогда, поэтому требуются иные подходы к управлению с использованием инновационных цифровых технологий, дающие новые способы наращивания эффективности работы предприятий. Важным условием и фактором успешного проведения цифровой трансформации является повышение цифровой зрелости, которое выражается в степени готовности предприятия к запланированным переменам [1]. Показано, что стратегическая задача цифровой трансформации компании заключается в построении практически жизнеспособного цифрового двойника, который будет описывать взаимосвязь между цифровыми активами и видами деятельности, моделируя взаимодействие между различными источниками данных в организации [2]. Важным фактором при этом является использование предиктивной аналитики, которая объединяет в себе множество методов машинного обучения, статистики, моделирования, теории игр, на основе которых производится анализ исторических данных, составляются предсказания будущего состояния объекта и выявляются закономерности, а также определяются возможные риски и возможности. За счет интерпретации выявленных закономерностей предиктивная аналитика помогает создать персонализированный̆ подход по доставке информации при работе с клиентами и предугадать их потребности и желания. Преимущества включения предиктивного анализа в жизненный цикл организации заключаются в предоставлении интеллектуального анализа для принятия оптимальных решений, минимизации неопределенности, в точном управлении рисками, своевременном реагировании на изменение различного рода показателей̆ эффективности предприятия.
Целью исследования является обоснование актуальности и эффективности предлагаемой технологии кластеризации и генерации персонализированных торговых предложений для пассажирских авиаперевозок с учетом отраслевой специфики и принципов построения такой технологии.
Материал и методы исследования
Был выполнен обзор аналитических отчетов и статистических данных по сектору пассажирских авиаперевозок, особенно относящихся к области продажи дополнительных услуг. Для разработки технологии кластеризации были проведены проблемные интервью с представителями авиакомпаний, на основе лучших практик работы с большими данными выбирались оптимальные подходы к решению выявленных проблем. В разработке использовались нейросети (методы искусственного интеллекта) и машинное обучение, а также применялись автоматизированные подходы на основе формальных правил обработки данных и кластеризации.
Результаты исследования и их обсуждение
Необходимость подобных решений, скорректированных под рынок пассажирских авиаперевозок, обусловлена структурой доходности авиакомпаний и активным ростом данного рынка [3]. Да, годы пандемии существенно сказались на рынке авиаперевозок, но наблюдается его возврат к прежним показателям и в 2022 году прогнозируется выручка 782 млрд долларов, и это не намного меньше максимума выручки 838 млрд долларов в 2019 году [4]. При этом в пике в 2019 году было перевезено более 4,5 трлн пассажиров [5]. Каждому из этих пассажиров в той или иной форме делались предложения дополнительных сервисов, но с достаточно низкой степенью персонализации. Для более глубокого понимания нашего потенциала в этом секторе следует рассмотреть статистику по доходам авиакомпаний именно от продажи дополнительных сервисов. При этом по отрасли в целом доходы от продажи дополнительных сервисов занимают существенную долю в выручке авиакомпаний (более 10%) при огромной маржинальности, не сопоставимой с маржинальностью основной деятельности – непосредственно услуг по авиаперевозке (рис. 1).
При такой среднеотраслевой статистике видно, что лидеры рынка по внедрению дополнительных сервисов получают от них более половины своей выручки, а в рамках пандемии эта доля у многих компаний еще и существенно возросла (табл. 1). Таким образом, большинство авиакомпаний, в том числе крупнейших, имеют огромный потенциал по росту выручки уже сейчас – за счет интеграции грамотной системы продаж дополнительных услуг – как собственных (багаж, выбор места, питание и т.д.), так и сторонних (отели, трансферы, страхование). И для этого нужны, прежде всего, информационные решения, обеспечивающие информационную интеграцию с поставщиками услуг и внутренними системами авиакомпаний.
Таблица 1
Процент выручки от продажи дополнительных сервисов в доле общей выручки у избранных авиакомпаний [7]
|
№ |
Компания |
2021 |
2019 |
|
1 |
Wizz Air |
56,0% |
45,4% |
|
2 |
Frontier |
54,9% |
43,6% |
|
3 |
Spirit |
54,3% |
47,0% |
|
4 |
Allegiant |
51,3% |
46,5% |
|
5 |
Viva Aerobus |
44,8% |
45,0% |
|
6 |
Ryanair Group |
44,7% |
34,5% |
|
7 |
Volaris |
42,9% |
38,5% |
|
8 |
GOL |
33,0% |
17,0% |
|
9 |
easyJet |
31,4% |
21,6% |
|
10 |
Pegasus |
30,8% |
26,4% |
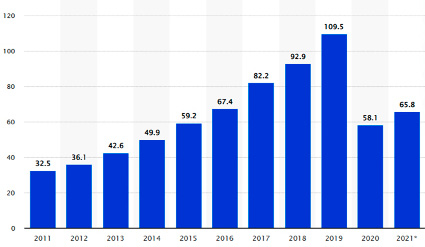
Рис. 1. Общая выручка от продажи дополнительных сервисов авиакомпаниями с 2011 по 2021 годы [6]
Такой продукт, стартовав в сфере пассажирских авиаперевозок, будет достаточно легко приспособлен и под иные сферы: железнодорожные компании; онлайн туристические агентства (и платформы по продаже билетов); туристические операторы; круизные компании; отельные агрегаторы (booking.com, expedia.com, kayak.com); веб-сервисы.
Объем данных в электронной коммерции систем авиакомпаний является одним из самых больших и может сравниться только с банковским сектором [8]. По сложности данных по каждому пассажиру и эволюции данных на каждом этапе полета системы электронной коммерции авиакомпаний также не уступают ни одной другой отрасли электронной коммерции. При этом решения по продажам на каждом этапе полета для пассажира должны приниматься в минимальное время. Все это фактически означает обработку массивных объемов данных, большое количество критериев при принятии решений, а также ограниченность времени принятия решений. Кроме того, постоянное добавление критериев, объектов продажи и обогащение данных о пассажире не позволяют задать четкие правила выбора времени, метода и объекта продажи: требуется постоянная коррекция принимаемых решений для максимизации дохода [9].
С точки зрения сбора и обработки информации интерес представляют три больших класса данных о пассажирах.
1. Статические данные. К ним относится информация о пассажире, которая не изменяется со временем и не накапливается. Ключевыми записями, относящимися к статическим данным, являются: паспортные данные; пол; возраст; дата рождения; знак зодиака; национальность; рост; страна рождения.
2. Исторические данные. К таким данным относятся транзакционные данные о пассажире, накапливаемые о пассажирах в процессе приобретения услуг компании и любом взаимодействии с ней: количество полетов; средний чек; история полетов; история покупок; компаньоны; время покупок; устройства, с которых делается заказ.
3. Классификация пассажира: данные (метки), присваиваемые пассажирам в процессе обработки записей о них системой кластеризации. Это могут быть как абстрактные кластеры , сформированные как с помощью обработки базы данных пассажиров методами машинного обучения и/или искусственного интеллекта, так и вручную – на основе присвоения пассажирам (клиентам) тех или иных меток на основе логических правил, заданных разработчиком (администратором/маркетологом), например: веган; любитель горнолыжного отдыха; часто летающий на Бали; летает с семьей; трое детей; летает по работе; VIP.
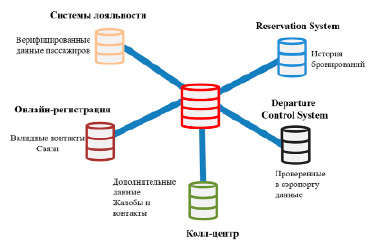
Рис. 2. Сбор статических и исторических данных из разных информационных систем
Сбор статических и исторических данных при этом является нетривиальной задачей, так как значимые записи содержатся в различных информационных системах авиакомпании, причем механизмы интеграции данных системы нестандартны и для каждого клиента свои. Чаще всего данные собираются из систем, изображенных на рисунке 2. К таким системам относятся следующие.
Системы управления лояльностью пассажиров. Как правило, основная функция данных систем – накопление подарочных миль и закрепление их за конкретным человеком. Из данного функционала вытекает критическая необходимость правильной и однозначной идентификации человека. Из-за этого из всех остальных информационных систем авиакомпании системы управления лояльностью содержат наиболее достоверные идентификационные данные пассажира.
Системы бронирования (Reservation System). Содержат данные об истории бронирований, выгрузка которых привязывается к пользователям по данным, полученным из систем управления лояльностью.
Системы контроля отправки пассажиров (DCS – Departure Control Systems). Необходимы для дополнительной верификации данных, так как содержат вручную проверенные в аэропорту при отправке пассажиров данные.
Системы онлайн-регистрации на рейс. Используются для получения верифицированных контактных данных пассажиров, необходимых для дальнейшей отправки им сообщений и рекламных предложений.
Данные колл-центров. Наименее структурированные из всех и, как правило, требуют дополнительной обработки текстовых записей методами искусственного интеллекта. Однако полезны и в части получения дополнительных контактных данных клиентов.
Столь большое количество информационных систем для сбора данных обусловлено неполнотой данных о клиенте (пассажире), содержащейся в каждой из них по отдельности. Так, где-то из идентифицирующих клиента данных могут быть записаны только телефонный номер, или только почта, или только ID, или только паспортные данные, и т.д. Кроме того, часть этих данных может быть занесена неправильно. Происходить это может либо из-за особенностей структуры базы данных самой системы, либо из-за ошибок оператора при занесении персональных данных, либо из-за ошибок самого клиента. Из-за этого данные из различных систем приходится сличать и сводить в единую базу данных.
На основе описанных данных о пассажирах проводилась их кластеризация. Направлений кластеризации при этом было выбрано два.
1. Кластеризация методами искусственного интеллекта [10]. Позволяет автоматизировать обработку данных и за счет установленных критериев кластеризации получать некий универсально применимый для маркетинговых целей результат. Очевидный плюс такого подхода – автоматизация. К отрицательным сторонам относится риск достаточно хаотичной кластеризации с точки зрения потребительских качеств, так как из-за специфики бизнес-процессов на вход системы подаются данные, весьма ограниченно связанные с портретом потребителя, прежде всего это статические данные, больше относящиеся к персональным. При этом из-за специфики авиаперевозок по каждому пассажиру имеется весьма небольшое количество транзакций, что затрудняет обучение алгоритмов и снижает релевантность кластеризации.
2. Кластеризация на основе формальных критериев. В данном случае каждому пользователю присваиваются «метки» на основе логических правил. Преимущества метода – однозначный контроль кластеризации со стороны авиакомпании, что повышает доверие к системе и возможность гибкой коррекции логики кластеризации.
Для внедрения был в итоге выбран именно подход, основанный на кластеризации клиентов с использованием формальных критериев с применением методов машинного обучения для формирования персональных предложений.
Алгоритм машинного обучения работает на основе вычисления метрики похожести всех клиентов компании, занесенных в базу данных. Для расчета метрики похожести используется множество тэгов, присваиваемых клиентам на основе установленных логических критериев. Например, тэг #familyTrip присваивается пассажирам, у которых больше 50% полетов – с семьей, тэг #dayOnly – пассажирам, летающим только днем, тэг #painServicesOften – пассажирам, приобретающим дополнительные платные услуги. Таким образом, каждому пассажиру может быть присвоено множество тэгов. У каждого тэга при этом в настройках программного обеспечения администратором устанавливается вес – число от 1 до 10, выражающее субъективную важность для компании-клиента данного тэга-характеристики в расчете персональных предложений.
Для поиска похожих на него пассажиров происходит сопоставление целевого клиента со всеми остальными клиентами авиакомпании с целью выявления общих тэгов. Далее веса всех тэгов, общих для целевого и текущего клиента, складываются, в итоге получается абсолютный коэффициент сродства (КС):
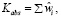
где Кabs – коэффициент сродства;
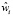 – вес каждого общего тэга у двух сравниваемых клиентов.
– вес каждого общего тэга у двух сравниваемых клиентов.
Для получения же удобной и наглядной относительной метрики сродства клиентов рассчитывался максимальный коэффициента сродства для целевого клиента Кmax, равный сумме всех коэффициентов тэгов целевого пассажира:
Кmax = ∑wi ,
где Кmax – максимальный коэффициент целевого клиента;
wi – вес каждого из тэгов, присвоенного данному клиенту.
Тогда значение целевого для нас относительного коэффициента сродства целевого клиента с текущим будет выражаться следующим образом:
КС = Кabs / Кmax .
Данный коэффициент сродства далее применяется для расчета персональных предложений. В расчете используются данные трех сущностей:
• реестр сделанных клиентам предложений;
• реестр кликов клиентов по сделанным предложениям;
• реестр совершенных клиентами покупок.
Для первичного обучения программного обеспечения эти реестры либо заполняются предварительно сгенерированными данными, либо клиентам определенное время делаются случайные предложения и в дальнейшем фиксируется реакция на них.
Данные реестры фактически соответствуют разным этапам воронки продаж. При этом с точки зрения формирования предложений наиболее ценным для нас действием является совершенная клиентом покупка, менее ценным – клик по предложению. Для сообщения алгоритму машинного обучения данной ценности каждому из типов действия присваивается свой вес в баллах: простой показ предложения считается за 1 балл, клик по предложению – за 2 балла, а покупка – за 10 баллов.
Для примера, если Клиенту N только один раз делалось предложение, это было предложение такси класса «люкс» и клиент его в итоге заказал, то для предложения такси «люкс» у этого клиента будет 1 + 2 + 10 = 13 баллов. Если бы клиент данную услугу не стал приобретать, а только кликнул по ней, то рейтинг этого предложения у него составил бы лишь 3 балла. Если бы данному человеку на разных этапах взаимодействия с нашей компанией эта реклама была бы показана несколько раз, то в сумме набралось бы несколько просмотров, несколько кликов и несколько покупок и тогда суммарный рейтинг данного предложения у этого клиента составил бы:
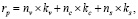
где rp – рейтинг конкретного предложения у конкретного клиента (от p = proposal);
nv – количество показов данного типа предложения данному клиенту (от v = view);
kv – вес показа (по умолчанию равен 1);
nc – количество кликов по данному предложению данным клиентом (от c = click);
kc – вес клика (по умолчанию равен 2);
ns – количество покупок данной услуги данным клиентом (от s = sale);
ks – вес покупки (по умолчанию равен 10).
Итоговый же алгоритм расчета персональных предложений использует как метрику сродства клиентов, так и данные рейтинги предложений по каждому из клиентов. Алгоритм в текущей реализации модуля запускается непосредственно в момент генерации предложения и состоит из следующих шагов (рис. 3).
• Для целевого клиента, которому делается предложение, подбирается ТОП-50 наиболее похожих клиентов из базы данных авиакомпании по метрике сродства, расчет которой описан выше.
• Для каждого из ТОП-50 похожих клиентов, а также для целевого клиента по всем когда-либо сделанным им предложениям рассчитываются рейтинги этих предложений.
• Каждый из рассчитанных для ТОП-50 рейтингов предложений умножается на коэффициент сродства клиента из ТОП-50 с текущим клиентом.
• Рейтинги предложений, рассчитанные для целевого клиента, умножаются на максимальный коэффициент сродства и дополнительно на 3 (kt – вес целевого клиента) (вручную выставляемый коэффициент повышения релевантности).
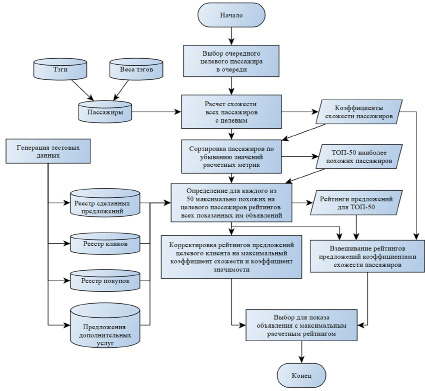
Рис. 3. Графическая схема работы алгоритма подбора персонального предложения
• По каждому из типов предложений суммируются все рассчитанные произведения рейтингов на коэффициенты сродства.
• Целевому клиенту делается предложение, которое при таком расчете набрало наибольшее количество баллов.
Данный алгоритм поиска оптимального предложения можно описать следующей формулой:
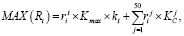
где i – порядковый номер конкретного предложения;
Ri – суммарный рейтинг конкретного предложения для данного клиента;
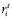 – рейтинг конкретного предложения из истории целевого клиента (от t = target);
– рейтинг конкретного предложения из истории целевого клиента (от t = target);
Кmax – максимальный коэффициент сродства целевого клиента;
kt – вес целевого клиента;
j – порядковый номер клиента из ТОП-50 похожих на целевого;
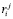 – рейтинг конкретного предложения у j-го клиента из ТОП-50 похожих на целевого;
– рейтинг конкретного предложения у j-го клиента из ТОП-50 похожих на целевого;
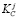 – коэффициент сродства целевого клиента с j-тым клиентом из ТОП-50 похожих на целевого.
– коэффициент сродства целевого клиента с j-тым клиентом из ТОП-50 похожих на целевого.
Или эту же формулу можно без каких-либо искажений использовать с абсолютным коэффициентом сродства:
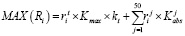
Если исходную формулу прописать в полностью развернутой форме, то модель поиска оптимального предложения будет выглядеть следующим образом:
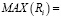
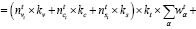
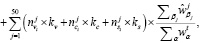
где i – порядковый номер конкретного предложения;
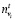 ,
, 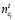 ,
, 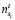 – количество взаимодействий, совершенных целевым пользователем с i-м предложением, соответственно показов, кликов и покупок;
– количество взаимодействий, совершенных целевым пользователем с i-м предложением, соответственно показов, кликов и покупок;
kv, kc, ks – веса соответствующих взаимодействий с рекламой (единые для всех клиентов), соответственно для показов, кликов и покупок;
kt – значимость показателей целевого клиента (по умолчанию 3);
α – суммарное количество тэгов у целевого клиента;
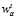 – вес конкретного тэга у целевого клиента;
– вес конкретного тэга у целевого клиента;
j – порядковый номер клиента из ТОП-50 похожих на целевого;
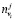 ,
, 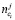 ,
, 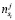 – количество взаимодействий, совершенных j-м пользователем с i-м предложением, соответственно показов, кликов и покупок;
– количество взаимодействий, совершенных j-м пользователем с i-м предложением, соответственно показов, кликов и покупок;
βj – количество общих тэгов у j-го клиента из ТОП-50 с целевым клиентом;
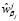 – вес каждого их тэгов, общих для целевого клиента и j-го клиента из ТОП-50.
– вес каждого их тэгов, общих для целевого клиента и j-го клиента из ТОП-50.
В результате разработанный метод дает возможность достаточно гибко управлять работой программным обеспечением со стороны клиента, не требуя при этом значительных вычислительных мощностей при проведении пересчета всех метрик в фоновом режиме по расписанию.
Заключение
Методы искусственного интеллекта являются эффективным средством решения поставленных задач по кластеризации и генерации персональных предложений.
В соответствии с этим был разработан подход, позволяющий выполнять кластеризацию клиентов с использованием перечня тэгов, присваиваемых каждому клиенту на основе логических правил. Данные правила (тэги) гибко настраиваются, адаптируясь под пожелания заказчика при внедрении программного обеспечения.
Обучение программного обеспечения и генерация персональных предложений осуществляются путем расчета метрики схожести, которая учитывает присвоенные каждому клиенту тэги, сделанные ранее каждому клиенту предложения и действия клиентов, совершенные с данными предложениями.
Обучение программного обеспечения может проводиться как на основе генерации предварительных данных о действиях пользователей с объявлениями, так и на основе формирования предложений случайным образом в течение ограниченного периода времени по выбору заказчика.
Разработанный подход к генерации персональных торговых предложений позволяет гибко управлять процессами кластеризации клиентов и формирования предложений, обеспечивает простоту внедрения, исключая при этом скачкообразные нагрузки на серверную архитектуру, так как основные вычислительные операции выполняются не по запросу пользователя, а в фоне по расписанию.
Библиографическая ссылка
Гордеев В.В., Столяров А.Д., Абрамов В.И. ТЕХНОЛОГИЯ КЛАСТЕРИЗАЦИИ И ГЕНЕРАЦИИ ПЕРСОНАЛИЗИРОВАННЫХ ТОРГОВЫХ ПРЕДЛОЖЕНИЙ ДЛЯ ПАССАЖИРСКИХ АВИАПЕРЕВОЗОК // Современные наукоемкие технологии. 2023. № 4. С. 34-41;URL: https://top-technologies.ru/ru/article/view?id=39577 (дата обращения: 31.07.2026).
DOI: https://doi.org/10.17513/snt.39577