



При наличии большого объема бумажной документации недвижимого имущества возникает необходимость автоматизации процесса осмысленного извлечения различной информации. Под осмысленным извлечением информации в данной работе подразумевается отличающаяся друг от друга работа с разными ее типами. Если информация является сплошным текстом, то ее обработка не вызывает каких-либо затруднений, однако если информация представляет собой табличные данные, то возникают сложности при ее анализе: необходимо обнаружить таблицу на отсканированной странице документа, выделить ячейки таблицы для извлечения информации из каждой по отдельности, понять, что представляет собой извлеченная из ячейки информация.
Цель исследования заключается в разработке алгоритма, который решает задачу по автоматическому извлечению табличных данных из отсканированных документов, таблицы которых имеют следующую структуру: отдельная осмысленная единица информации содержится в двух ячейках, которые идут друг за другом. В первой ячейке представлено наименование характеристики, а во второй ячейке – ее значение. Такой структуре отвечает справка бюро технической инвентаризации (БТИ) о состоянии здания (также известная как форма 5), на примере которой продемонстрированы шаги алгоритма.
Материалы и методы исследования
В качестве технологий в данном алгоритме используются:
1. Метод Оцу – алгоритм определения порога бинаризации для изображения в оттенках серого. Метод весьма прост, но в то же время стабилен, из-за чего получил широкое применение в области обработки изображений [1].
2. Алгоритм RLSA (Run Length Smoothing Algorithm) – алгоритм, позволяющий преобразовывать пиксели на основе окрестности.
3. Преобразование Хафа – представляет собой алгоритм, который позволяет обнаруживать на изображении определенные фигуры.
4. Фильтр Кэнни – оператор, позволяющий выделять на изображении границы объектов. Обладает хорошей производительностью и на текущий момент является стандартом в обработке изображений [2].
5. Алгоритм Satoshi Suzuki – алгоритм, предназначенный для поиска контуров на изображениях.
6. Tesseract OCR – бесплатная компьютерная технология для распознавания написанного текста, которая показывает отличные результаты при работе с текстом, написанным кириллическими символами [3].
Прежде чем приступать к описанию работы алгоритма, необходимо декомпозировать задачу извлечения табличных данных на более мелкие задачи. Так, извлечение табличной информации должно содержать следующие этапы:
1. Устранение наклона документа – отсканированный документ может обладать некоторым углом наклона, который в свою очередь будет влиять на конечный результат алгоритма.
2. Обнаружение таблицы в отсканированном документе и выделение ячеек.
3. Чтение информации из ячеек таблицы.
Перед началом всех действий изображение отсканированного документа необходимо сделать черно-белым, так как это позволяет значительно уменьшить количество лишней информации. Для этого необходимо перевести отсканированный документ в оттенки серого, а затем с помощью порогового значения и метода Оцу преобразовать документ в черно-белый.
1. Устранение наклона отсканированного документа
Очевидно, что для того чтобы исправить наклон отсканированного документа, необходимо знать его угол. Существует множество методов, которые позволяют решить задачу вычисления угла наклона, например метод анализа профиля проекции, метод основанный на преобразовании Хафа, метод ближайших соседей [4].
Хорошим методом для определения угла наклона документа будет использование преобразования Хафа. Однако для начала надо подготовить отсканированный документ. Сначала с помощью RLSA алгоритма строки текста на черно-белом отсканированном документе преобразуются в широкие линии (RLSA заменяет фоновые пиксели в бинаризированном изображении пикселями переднего плана, если количество фоновых пикселей в окрестности не превышает порогового значения, т.е. удаляет маленькие окрестности пикселей [5]). Затем с помощью морфологической операции эрозия с документа удаляется лишняя информация (например, линии таблиц или пометки). В таком виде преобразование Хафа может неправильно определить линии текста, чтобы этого избежать, нужно с использованием оператора Кэнни сделать их «тоньше». Затем с помощью преобразования Хафа определяются линии (документ с нанесенными линиями строк текста представлен на рис. 1), а затем вычисляется их наклон. Так как линии могут быть распознаны некорректно, стоит принять за угол наклона документа медианное значение углов наклона всех линий. Исправление наклона документа заключается в повороте документа в обратную сторону на величину найденного угла.
2. Обнаружение таблицы на документе и выделение ячеек
Сам процесс обнаружения таблицы представляет собой формирование маски, которая впоследствии позволяет из исходного отсканированного документа получить скелет таблицы, то есть саму таблицу без ее содержимого. Далее скелет таблицы позволяет вычленить отдельные ячейки и работать с каждой самостоятельно.
На этапе обнаружения таблицы также требуется применение RLSA. Данный алгоритм позволяет преобразовать строки текста внутри таблицы в сплошные широкие линии, которые используются в маске. Далее, с помощью морфологической операции эрозия удаляются мелкие дефекты сканирования, например пятно на стекле сканирующего устройства, и контур таблицы. Однако из-за этого линии строк текста уменьшаются в размере, чтобы вернуть их предыдущий размер, используется морфологическая операция дилатация. Таким образом формируется маска, которая представлена на рис. 2.

Рис. 1. Документ с нанесенными линиями строк текста
Затем из изначального изображения отсканированного документа вычитается маска, что позволяет оставить на изображении документа только скелет таблицы. На рис. 3 изображен документ, к которому применяется вышеописанный способ, результат которого представлен на рис. 4.
В найденной таблице определяются ячейки, для этого используется метод поиска контуров, предложенный Satoshi Suzuki [6]. Также определить ячейки можно с помощью другого метода – оконного преобразования Хафа [7].
3. Чтение информации из ячеек таблицы
Сама информация должна сохраняться в хеш-таблице, где ключом является наименование характеристики, а значением – ее значение.

Рис. 2. Маска для выделения таблицы
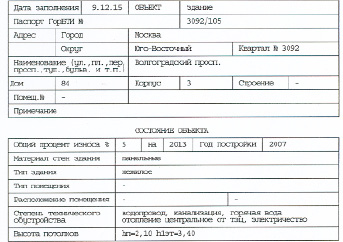
Рис. 3. Оригинальная таблица

Рис. 4. Полученный «скелет» таблицы
Предполагается, что обнаруженные контуры, которые содержат вписанные в себя другие контуры, не являются ячейками таблицы, поэтому при анализе игнорируются. Далее идет проход по всем ячейкам в направлении сверху вниз и слева направо, в ходе которого с помощью системы оптического распознавания символов Tesseract OCR определяются интересующие данные и их метаинформация. Делается это следующим образом: берется ячейка, которая должна быть обработана, из нее считывается информация, которая определяет метаинформацию, и сразу же читается следующая ячейка, которая определяет саму информацию, затем обе прочитанных ячейки записываются в хеш-таблицу, как пара «ключ – значение».
Вышеописанный алгоритм представлен на рис. 5.
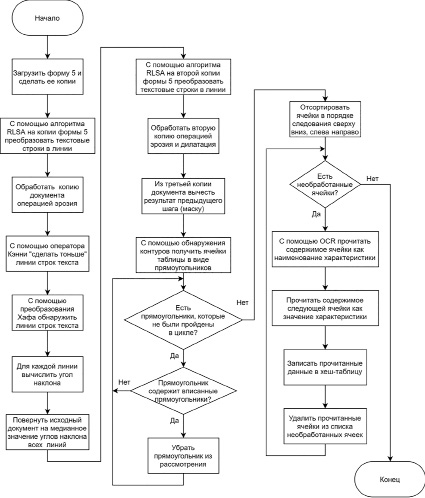
Рис. 5. Алгоритм анализа формы 5
Результаты тестирования предложенного алгоритма
|
Время выполнения, с |
Использование памяти, Мб |
Нагрузка на процессор, % |
|||
|
Стенд № 1 |
Стенд № 2 |
Стенд № 1 |
Стенд № 2 |
Стенд № 1 |
Стенд № 2 |
|
24,6 |
13,8 |
14,5 |
14,6 |
9,9 |
9,7 |
Результаты исследования и их обсуждение
Предложенный алгоритм был представлен в виде программы, написанной на языке Python версии 3.7.3, и протестирован на 50 отсканированных справках БТИ о состоянии здания, которые были созданы специально для проверки алгоритма и не являются реальными документами. Тестирование проводилось на двух стендах со следующими характеристиками:
1. Стенд № 1:
− центральный процессор: Intel Core i5 8500 с тактовой частотой 3 ГГц;
− оперативная память: DDR4 24 Гб с частотой 1 ГГц.
2. Стенд № 2:
− центральный процессор: AMD Ryzen 7 3700X с тактовой частотой 3,59 ГГц;
− оперативная память: DDR4 32 Гб с частотой 1,6 ГГц.
В таблице представлены усредненные результаты проведенного тестирования.
На всех 50 отсканированных справках БТИ о состоянии здания были правильно определены ячейки таблицы, однако из-за выборки маленького размера нельзя однозначно утверждать, что данный алгоритм с вероятностью 100 % не потеряет табличную информацию, но можно отметить, что все же данная вероятность стремится к этому числу.
Результат данной работы в виде предложенного алгоритма имеет практическую ценность – данный алгоритм можно использовать при работе с документами, содержащими таблицы, ячейки которых стоят в последовательности «характеристика – значение», что позволяет быстро извлекать информацию, при этом не теряя метаданные для каждой прочитанной характеристики. Также при некоторой модификации алгоритма его можно использовать как универсальный метод по извлечению информации из таблицы любого вида.
Научная новизна работы заключается в том, что предложен алгоритм, который решает задачу извлечения информации из таблиц, ячейки которых стоят в последовательности «характеристика – значение».
В будущем планируется разработка аналогичных алгоритмов для анализа других документов, относящихся к области недвижимого имущества.
Заключение
Предложенный алгоритм справляется с поставленной перед ним задачей – извлечение информации из таблиц, ячейки которых стоят в последовательности «характеристика – значение», и на выходе предоставляет хеш-таблицу, содержащую извлеченную информацию.
Библиографическая ссылка
Качалин В.С., Панов Ю.Н., Калугин А.В. Алгоритм извлечения табличной информации из отсканированных документов на примере справки бюро технической инвентаризации о состоянии здания // Современные наукоемкие технологии. 2022. № 11. С. 46-51;URL: https://top-technologies.ru/ru/article/view?id=39395 (дата обращения: 06.07.2026).
DOI: https://doi.org/10.17513/snt.39395