



В настоящее время всё популярнее становится организация «индивидуальной образовательной траектории». Кроме данного понятия существуют еще три, которые часто используют как синонимы: «индивидуальный образовательный маршрут», «индивидуальная образовательная программа», «индивидуальный учебный план» [1]. Учебные заведения не могут полностью положить построение траектории на плечи обучающихся, так как ограничены образовательными стандартами. Однако на основе этих стандартов могут предложить вариативность в выборе дисциплин обучения. Основная проблема студентов в такой ситуации – произвести выбор и не ошибиться. Университеты предлагают описание дисциплин, но зачастую этого недостаточно для понимания уровня знаний и компетенций, которые необходимы для обучения или которые будут получены по его итогу.
Для устранения вышеупомянутой проблемы было принято решение разработать систему с применением когнитивных технологий. Под когнитивными технологиями понимается направление развития систем искусственного интеллекта, которые используются человеком при принятии решений, анализе данных, поиске закономерностей и аномалий [2]. Иными словами, для построения индивидуальной траектории обучения необходимо использовать информационные технологии.
Современные образовательные организации стараются адаптировать методы и темпы передачи компетенций в зависимости от индивидуальных предрасположенностей каждого отдельного ученика. Для повышения эффективности оценивания уровня владения навыком, разделения учебного процесса на этапы и выдвижения предположений о заданиях, наиболее подходящих в данный момент, используются искусственные нейронные сети. Машинное обучение в образовательном процессе применяется в рекомендательных системах для решения задач кластеризации и классификации. При реализации применяются нейронные сети прямого и обратного методов распространения ошибки. Основной проблемой их использования является необходимость разработки методологий и техник по увеличению данных или же увеличения точности работы нейронных сетей при малом количестве исходной информации в связи с недостатком данных для обучения.
Цель исследования – проведение обзора и анализа научных исследований и разработок по построению индивидуальных траекторий обучения, научных исследований и разработок, направленных на использование машинного обучения и нейронных сетей, а также проведение анализа запроса целевой аудитории для конкретизации проблем, выявленных по итогу обзора и анализа научных исследований и разработок по построению индивидуальных траекторий обучения, а также проектирование системы, позволяющей получить рекомендации о целесообразности прохождения дисциплины, и способов анализа ее эффективности.
Методы построения индивидуальной траектории обучения. Понятие искусственного интеллекта сейчас повсеместно используется, в связи с этим существует множество различных определений данного термина. Широкое определение искусственного интеллекта не отображает картины того, какой тип ИИ используется в настоящее время. Искусственным интеллектом обычно называют узкий искусственный интеллект (УИИ). Он позволяет запрограммировать систему на выполнение одной задачи даже в режиме реального времени. Однако такая система работает с определенным набором данных [3]. Вопрос, чем машинное обучение отличается от глубокого обучения, возникает достаточно часто. В первую очередь необходимо понять, что машинное обучение является подразделом ИИ и науки о данных, специализирующимся на использовании данных и алгоритмов для имитации процесса наработки опыта человеком с постепенным повышением точности [4, 5]. Глубокое же обучение является подвидом машинного обучения. Нейронные сети, также известные как искусственные нейронные сети (ИНС) или смоделированные нейронные сети, представляют собой подмножество машинного обучения и лежат в основе алгоритмов глубокого обучения. ИНС работают по принципу черного ящика – мы, как создатели системы, не можем точно определить, что происходит внутри нейронной сети, когда она работает [6]. Чтобы нейросеть работала, ее необходимо обучить. Обучение производится с использованием трех выборок некоторого набора данных: тестовая, обучающая и контрольная. Тестовая выборка проводит проверку построенной и обученной сети. Контрольная выборка позволяет избежать переобучения сети – как только ошибка на этой выборке начинает возрастать, процесс обучения прекращается [7]. Этап обучения сети обычно самый длительный и трудоемкий. Он состоит из двух частей: прямое и обратное распространение ошибки [8]. Метод обратного распространения ошибки позволяет вычислить и объяснить ошибки, связанные с каждым нейроном, что позволяет скорректировать и адаптировать параметры модели соответствующим образом [6].
Искусственная нейронная сеть состоит из трех компонентов: входной слой; скрытые слои и выходной слой. Крайний левый слой называется входным слоем, крайний правый слой – выходным слоем. Средний слой называется скрытым, потому что его значения не видны в обучающем наборе. Иными словами, скрытые слои – это вычисляемые значения, и чем их больше, тем сеть глубже. А глубокой нейронной сетью называется любая ИНС с двумя или более скрытыми слоями [4]. Веса и смещения – это обучаемые параметры внутри сети. Обучаемая нейронная сеть будет подбирать случайные значения веса и смещения до того, как начнется обучение. По мере продолжения обучения оба параметра корректируются в сторону желаемых значений и правильного вывода. Эти два параметра различаются по степени их влияния на входные данные. Проще говоря, смещение показывает, насколько далеки прогнозы от их предполагаемого значения. Низкое смещение предполагает, что сеть делает больше предположений о форме вывода, тогда как высокое значение смещения делает меньше предположений о форме вывода. С другой стороны, вес можно рассматривать как силу соединения. Вес влияет на степень влияния изменения входных данных на выходные данные. Низкое значение веса не будет иметь никаких изменений на входе, и, наоборот, большее значение веса более значительно изменит выход [9]. Для понимания, как именно работает нейросеть, необходимо знать о линейной регрессии. Линейный регрессионный анализ (линейная регрессия) используется для прогнозирования значения переменной на основе значения другой переменной. Независимой переменной называется переменная, которая используется для предсказания значения другой переменной. А зависимой переменной – переменная, значение которой предсказывается. Эта форма анализа заключается в подборе таких коэффициентов линейного уравнения с одной или несколькими независимыми переменными, чтобы это уравнение наилучшим образом предсказывало значение зависимой переменной [10]. Каждый отдельный узел представляется в виде модели линейной регрессии. Она состоит из входных и выходных данных, весовых коэффициентов и порогового значения (смещения). Такую модель можно представить следующими формулами (1, 2), где x – входной слой, w и b – набор весов и смещений между каждым слоем [8]:
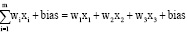 , (1)
, (1)
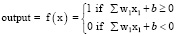 . (2)
. (2)
После определения слоя входных данных назначаются весовые коэффициенты. Затем необходимо просуммировать произведения входных данных и соответствующих им весовых коэффициентов. Наконец, выходные данные будут переданы через функцию активации, что вычисляет результат. При превышении результатом порогового значения узел передает данные на следующий слой (активируется). Тогда выходные этого слоя становятся входными для следующего. Такой процесс передачи данных между слоями характерен для нейронных сетей прямого распространения.
В ходе обучения модели требуется оценить точность с помощью функции стоимости (или потерь), среднеквадратической ошибки (MSE). В уравнении (3) используются следующие обозначения: i – индекс выборки, y-hat («y c крышечкой») – прогнозируемый результат, y – фактическое значение, m – число выборок.
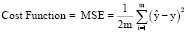 . (3)
. (3)
Проведение статистических экспериментов. Информационная система (ИС), позволяющая получить рекомендации о целесообразности прохождения дисциплины, требует тщательной проработки. Одним из важных моментов в ее создании является удовлетворение запроса целевой аудитории. Целевой аудиторией этой ИС являются обучающиеся, в учебном плане которых присутствуют выборные дисциплины. Для уточнения ее запроса было проведено анкетирование [11]. В опросе приняли участие 76 чел., 68 из них сталкивались с необходимостью формирования индивидуального учебного плана. Только к 12 предъявлялись требования, и почти половина (47 %) опрошенных оказались не удовлетворены выборными дисциплинами по различным причинам.
При анализе внесенных в опрос причин были выделены три наиболее часто встречающиеся:
− Слишком высокие требования к базовым для дисциплины знаниям.
− Материал был слишком простой, новой информации получено не было.
− Большие затраты времени и сил на изучение «базового» материала для выбранной дисциплины.
На основе проведенного анализа запроса целевой аудитории был сделан вывод о том, какую систему необходимо разрабатывать. В первую очередь было принято решение о типе системы. Выбор стоял между мобильным приложением и веб-сервисом. По итогу для проектирования и дальнейшей разработки выбран веб-сервис, так как его возможности шире, чем у мобильного приложения, а именно появляется возможность использовать его в браузере на любом устройстве.
Для данной системы наиболее удачным вариантом базы данных является реляционная модель. Данная модель была выбрана в связи с наличием следующих преимуществ: независимость данных и наличие методов нормализации, позволяющих получить базу данных с необходимыми характеристиками. Перед переходом к проектированию системы необходимо определить пользователей системы и их роли, а также функциональные и нефункциональные требования [12].
На основе результатов анализа действий, который пользователь может выполнять в данной системе, выделено четыре вида пользователей (акторов):
− неавторизованный пользователь,
− авторизованный пользователь (не добавлен в группу),
− пользователь в группе,
− администратор.
Каждый следующий «уровень» пользователя наследует возможности предыдущего. На основе анализа основных вариантов использования, которые должны быть доступны пользователям, были сформулированы функциональные требования к системе.
На основе этих данных была выделена информация, которую должна хранить база данных, и сформированы логические информационные группы:
1. Информация о пользователе, в том числе информация для входа в систему: ФИО, электронная почта, пароль.
2. Тестирование: название и описание теста, материалы к нему.
3. Отзывы: тип отзыва, текст отзыва, оценка.
4. Рекомендации: результат тестирования, рекомендация.
Данные группы информации были преобразованы в сущности базы данных. Кроме того, были выделены сущности, не указанные в блоках необходимой информации: роли и группы. В таблице представлены все сущности базы данных, а также их атрибуты.
На основе выделенных сущностей была спроектирована база данных. На этапе создания информационно-логической модели была раскрыта связь многие-ко-многим между сущностями группы (groups) и тесты (tests). На рис. 1 представлена модель, полученная в результате одного из этапов проектирования базы данных.
Информационную систему, позволяющую получить рекомендации о целесообразности прохождения дисциплины, необходимо контролировать. Важной частью контроля системы является именно результативность системы. Оценить такой параметр могут только непосредственные пользователи системы: насколько система удобна, насколько полезна и т.д. Наиболее простой способ узнать мнение пользователя о системе –спросить его. Так как система предполагает большое количество пользователей, то хорошим вариантом является создание подсистемы. Поэтому было решено воспользоваться моделированием процесса оценки отзывов.
Нечеткая логика – форма многозначной логики, в которой истинные значения переменных могут быть любыми действительными числами от 0 до 1 включительно. Такая форма логики применяется для обработки состояний «частичной истинности». В таком случае истинное значение будет меняться от полностью истинного до полностью ложного. В то время как в классической булевой логике истинные значения переменных могут быть только значениями 0 или 1 [13].
Основные сущности базы данных и их атрибуты
|
Сущности |
Атрибуты |
Описание |
|
Users |
Идентификатор, Имя, Фамилия, Отчество, Группа, Роль, Пароль, Почта, Дата регистрации |
Информация о пользователе |
|
Review |
Идентификатор, Идентификатор пользователя, Идентификатор теста, Текст отзыва, Оценка от пользователя, Оценка отзыва, Вариант оценивания |
Информация об отзыве |
|
Roles |
Идентификатор, Название Роли, Описание |
Информация о ролях пользователей |
|
Group |
Идентификатор, Название Группы, Описание |
Информация о группах |
|
Tests |
Идентификатор, Название, Описание, Дата создания, Дата открытия, Дата закрытия |
Информация о тестах |
|
Materials |
Идентификатор, Идентификатор теста, Название материала, Описание |
Информация о материалах |
|
Results |
Идентификатор, Идентификатор пользователя, Идентификатор теста, Результат, Рекомендация, Дата прохождения |
Информация о результатах |
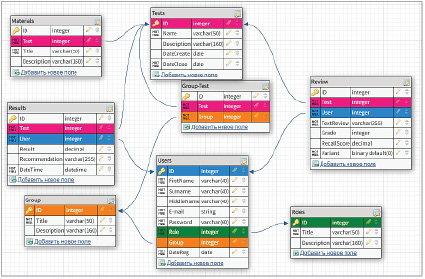
Рис. 1. Информационно-логическая модель базы данных
Для построения модели подсистемы в используемом программном обеспечении (ПО) необходимо:
1) указать входные переменные,
2) указать выходные переменные,
3) определить параметры термов (переменных состояний),
4) описать правила [14].
Первый этап – определение входных параметров. В ходе анализа цели подсистемы выделено две категории входных параметров: количество слов с положительной окраской, количество слов с негативной окраской. В каждой из категорий присутствует по два входных параметра: один относится к отзыву о тестировании, то есть на сам тест, второй – к отзыву о самой системе, например, по окончанию обучения на выбранной дисциплине. Решение «продублировать» входные переменные принято с учетом того, что для анализа текстов отзывов, направленных на разные объекты системы, будут использоваться разные наборы слов. Таким образом получаем четыре входных параметра, измеряемых в процентах:
− количество положительно окрашенных слов в отзыве о тестировании,
− количество негативно окрашенных слов в отзыве о тестировании,
− количество положительно окрашенных слов в отзыве о системе,
− количество негативно окрашенных слов в отзыве о системе.
Каждая переменная может принимать следующие значения: «очень мало», «мало», «средне», «много», «очень много».
Второй этап – описать значения термов. В программу FisPro были добавлены четыре входные переменные, в каждую из них были добавлены термы. На рис. 2 представлена одна из входных переменных.
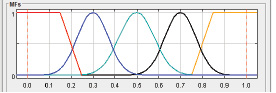
Рис. 2. График входной переменной
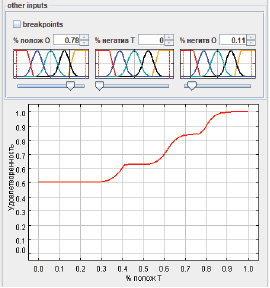
Рис. 3. Зависимость выходной переменной от входной при заданных значениях трех входных переменных
Для реализации алгоритма нечеткой логики необходимо ввести в программу правила, которые определяют значение выходной переменной в зависимости от значений входных переменных. Следующий этап – проверка системы. Был произведен просмотр выходного параметра в зависимости от входных параметров.
Так, на Рис. 3 представлены графики зависимости выходной переменной от процента слов с положительной окраской в отзыве о тестировании при следующих заданных значениях других входных переменных:
− отсутствие (0 %) в отзыве о тестировании слов с негативной окраской;
− очень низкое (11 %) значение наличия в отзыве о системе слов с негативной окраской;
− высокое значение (78 %) наличия слов с положительной окраской в отзыве о системе.
Можно заметить, что при таких заданных параметрах значение удовлетворенности пользователя ИС не будет падать ниже среднего. Однако необходимо помнить, что показатель «средне» также может свидетельствовать о несовершенстве системы.
На Рис. 4 представлены графики зависимости выходной переменной от процента слов с положительной окраской в отзыве о тестировании при следующих заданных значениях других входных переменных:
− отсутствие (0 %) в отзыве о системе слов с положительной окраской;
− среднее (56 %) значение наличия в отзыве о системе слов с негативной окраской;
− высокое (76 %) значение наличия слов с негативной окраской в отзыве о тестировании.
Можно заметить, что при таких заданных параметрах значение удовлетворенности пользователя ИС не будет подниматься выше среднего, что связано с большим количеством негативно окрашенных слов. Однако необходимо помнить, что показатель «средне» так же может свидетельствовать о несовершенстве системы, что может произойти при значении изменяющейся входной переменной = 100 % (или 1 в численном значении).
Кроме того, была просмотрена зависимость выходной переменной от двух входных переменных. Так, на рис. 5 представлен график зависимости выходной переменной от процента слов с положительной окраской в отзыве о тестировании и отзыве о системе при следующих заданных значениях других входных переменных:
− среднее (60 %) значение наличия в отзыве о тестировании слов с негативной окраской;
− высокое (74 %) значение наличия в отзыве о системе слов с негативной окраской.
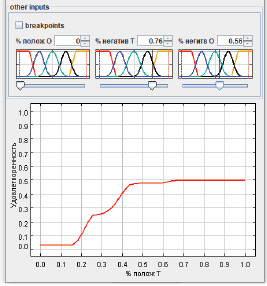
Рис. 4. Зависимость выходной переменной от входной при заданных значениях трех входных переменных
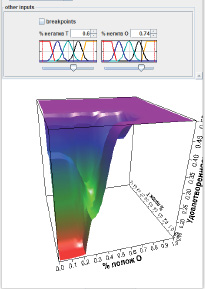
Рис. 5. Зависимость выходной переменной от двух входных при заданных значениях двух входных переменных
Можно заметить, что при таких заданных параметрах значение удовлетворенности пользователя ИС не будет подниматься выше среднего, что связано с большим количеством негативно окрашенных слов. Однако необходимо помнить, что показатель «средне» также может свидетельствовать о несовершенстве системы или ошибках в ней, например, при значении изменяющихся входных переменных = 100 % (или 1 в численном значении).
Разработанная модель оценки степени удовлетворенности рекомендательной системой позволяет на основе отзывов пользователей делать выводы о необходимости внесения изменений в систему. Так, резкое увеличение количества средней оценки позволяет сделать вывод о необходимости проверки базы слов на наличие ошибок или же на пересмотр базы. Кроме того, выявлены ситуации, которые при правильной работе системы возникать не должны (рис. 3). К таким ситуациям можно отнести одновременную оценку слов с положительной и негативной окраской (касающихся, например, тестирования) высоким процентом встречаемости, или же высокий процент встречаемости слов с негативной окраской у одного параметра (например, по итогам тестирования) и при этом низкий процент – у другого (например, у отзыва по итогам прохождения дисциплины).
В результате изучения предметной области была выявлена проблематика вопроса о построении индивидуальной траектории обучения, а также актуальность создания системы, способствующей грамотному и полноценному составлению таких учебных планов.
По итогам анкетирования сделан вывод о недостатке информации о требованиях к знаниям обучающихся на выборных дисциплинах, что ведет к понижению заинтересованности в обучении. Также сделан вывод, что обучающиеся критически относятся к введению новых систем в процесс организации построения индивидуальных образовательных программ (около 45 % не уверены, что хотели бы использовать рекомендательную систему). Был проведен анализ требований к системе, сделан вывод о необходимости создания системы в виде веб-приложения, что позволяет в любое время при наличии интернет-соединения авторизоваться на данной платформе с любого устройства. Это способствует уменьшению вероятности потери данных, а также способствует отсутствию «привязанности» к одному конкретному устройству. Из данного факта следует существенное достоинство приложения – кроссплатформенность. Вне зависимости от операционной системы при наличии браузера, который поддерживается приложением, будет иметься возможность его использования. Кроме того, произведено моделирование подсистемы оценки качества системы, которая поможет производить оценку степени удовлетворенности качеством рекомендательной системы на основе нечеткой логики. Такой подход позволит быстрее выявлять проблемы, возникающие с предметной стороны проекта, а значит, оперативнее повышать качество его работы. Однако данная подсистема требует доработ
Библиографическая ссылка
Касицына М.С., Осипов Н.А., Зудилова Т.В., Ананченко И.В., Иванов С.Е. ПРИМЕНЕНИЕ КОГНИТИВНЫХ ТЕХНОЛОГИЙ В ПОСТРОЕНИИ ИНДИВИДУАЛЬНОЙ ТРАЕКТОРИИ ОБУЧЕНИЯ // Современные наукоемкие технологии. 2022. № 11. С. 32-39;URL: https://top-technologies.ru/ru/article/view?id=39393 (дата обращения: 06.07.2026).
DOI: https://doi.org/10.17513/snt.39393