



Определение семантической близости текстов является одной из важнейших задач области компьютерной лингвистики. Ее решение может быть использовано при классификации текстов, автоматизации информационного поиска и пр.
Вопросам классификации текстов посвятили свои исследования многие специалисты в России и за рубежом: Т. Батура [1], Д.О. Долбин, В.И. Адамчук [2], А.М. Федотова, С.Е. Шаньшин, А.В. Куртукова, А.С. Романов [3], Х.Т. Максудов, Б.Б. Иномов [4], И.А. Батраева, А.Д. Нарцев, А.С. Лезгян [5], Yilin Niu, Chao Qiao, Hang Li, Minlie Huang [6], Omid Shahmirzadi, Adam Lugowski, Kenneth Younge [7].
Анализ существующих решений позволил сделать вывод об их научной и практической значимости. Однако существующие решения не могут быть использованы для задачи, поставленной перед авторами данной статьи. Особенностью решаемой авторами задачи является то, что тематики текстов заранее не определены, они могут меняться в процессе работы, и отсутствует обучающая выборка.
Современное состояние проблемы
Вопросы автоматизации извлечения информации из текстов широко применяются для решения ряда прикладных задач, среди которых можно выделить задачу тематической классификации текстов; анализа тональности, выявления спама и др. Как правило, классификация может быть точной или пороговой (используется мера подобия). Для классификации текстов часто используются ряд методов на основе машинного обучения (рис. 1). Подробный обзор методов, оценку их достоинств и недостатков рассматривает в своей работе Т. Батура [1].

Рис. 1. Краткий обзор методов классификации текстов
Вопросу классификации текстов посвящены исследования как российских, так и зарубежных авторов, что подтверждает актуальность создания программного продукта, реализующего функцию вычисления принадлежности текстов одной тематике. Д.О. Долбин и В.И. Адамчук для классификации текста по темам используют нейронную сеть с моделью многослойного персептрона [2]. А.М. Федотова, С.Е. Шаньшин, А.В. Куртукова и А.С. Романов рассматривают применение моделей RuBert, MultiBert, SVM и MLP для задачи определения автора текстов, заранее обучая модели на четырёхстах художественных текстах пятидесяти авторов [3]. Для определения специализации научных текстов Х.Т. Максудов и Б.Б. Иномов рассматривают методы k-ближайших соседей и логистической регрессии [4]. И.А. Батраева, А.Д. Нарцев, А.С. Лезгян при решении задачи определения жанровой принадлежности текстов используют векторное представление слов с помощью модели word2vec и подают его сверточной нейронной сети [5].
Теме статьи посвящены работы и зарубежных авторов. Так, YilinNiu, Chao Qiao, Hang Li, Minlie Huang для определения близости текстов используют пословные эмбеддинги [6], а Omid Shahmirzadi, Adam Lugowski, Kenneth Younge для решения задачи сходства используют меры близости на основе TF IDF и эмбеддингов [7].
Существующие решения имеют научную и практическую значимость, но не подходят для решения задачи, поставленной перед авторами, так как в данной задаче нет заранее известных тематик для текстов, они могут меняться в процессе работы, и отсутствует обучающая выборка. Вследствие чего возникла необходимость в написании собственной программной реализации определения принадлежности текстов одной тематике.
Постановка задачи оценки принадлежности текстов одной тематике
Для оценки семантического сходства заранее не известных текстов на русском языке на произвольные темы используется функция определения принадлежности текстов одной теме. Математическая постановка задачи заключается в оценке функции принадлежности двух текстов одной теме, а именно определению sim(text1, text2), где text1 и text2 – два произвольных текста, для которых определяется принадлежность одной теме, А – некоторая тема, которой могут принадлежать тексты. Учитывается то, что тексты text1 и text2 (в общем виде – textj, где j=1,2, состоят из отдельных слов textj = (tij, .., tnj), textj – j-й текст, tij– i-е слово в j-м тексте, n – количество уникальных слов) – произвольные. Функция принадлежности определяется как
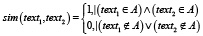 .
.
Разработанное программное решение должно учитывать функцию принадлежности и предложенный ранее авторами [8] алгоритм решения задачи.
Таким образом, необходимо разработать программное решение для определения степени семантической близости между произвольными текстами, приложение должно иметь простой и удобный интерфейс.
Программный комплекс для реализации информационных процессов
Программный комплекс состоит из нескольких запускаемых файлов, связанных между собой по типу клиент-сервер.
Клиентская часть программы имеет дружественный интерфейс и реализована на языке С#. Интерфейс программы (рис. 2) создавался для прикладного решения задачи оценки семантического сходства заранее не известных текстов на русском языке – определение направления обращений граждан среди различных ведомств.
Задача клиентской части программного решения – предоставление пользователю удобного формата работы с текстами, а именно загрузка множества текстов разом, наглядный вывод степеней близости текстов.
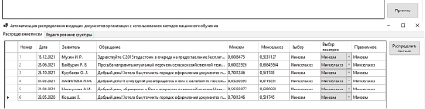
Рис. 2. Интерфейс разработанного программного решения
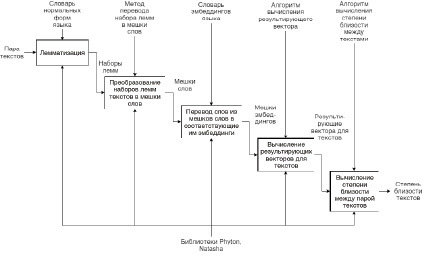
Рис. 3. Обобщенная функциональная модель серверной части программного решения
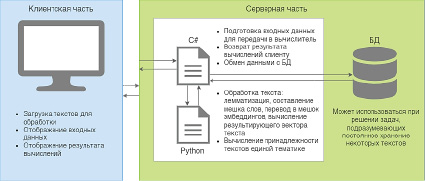
Рис. 4. Архитектура программного комплекса
Серверная часть программного решения предназначена для обработки текстов и вычисления степени близости между ними и представлена в обобщённом виде на следующей функциональной модели (рис. 3).
Основная часть логики программы написана на языке Python. Разумность установки этой части на сервер обусловлена повышенными требованиями языка к окружению. Для работы программы необходима установка python 3.9.9 и следующих библиотек: Xmlrpc.server, Natasha, Navec, Pymorhy2, Scipy, Numpy.
На рис. 4 представлена архитектура программного комплекса, взаимодействие между серверной и клиентской частями, их задачи и логические компоненты.
Обзор библиотек для реализации основных этапов задачи. Для того чтобы машина научилась понимать человека, в области компьютерных наук выделилось направление технологий искусственного интеллекта – обработка естественного языка, или Natural Language Processing (NLP). Эта группа технологий занимается проблемами компьютерного анализа и синтеза текстов на человекочитаемых языках, позволяет распознавать тексты, классифицировать документы, выполнять машинный перевод, определять спам-письма, создавать чат-боты и виртуальных помощников.
Основными библиотеками, которые включают в себя эмбеддинги для русского языка, можно считать RusVectores, DeepPavlov и Natasha (рис. 5).
Для решения задачи было решено использовать библиотеки проекта Natasha по ряду критериев: а) более понятная и подробная документация к проекту, простой и удобный для использования интерфейс, прозрачная обработка текста (явная инициализация компонент, загрузка эмбеддингов, вызов необходимых методов – разбиения на токены, анализа морфологии и прочего); б) на основе результатов сравнения Natasha с моделью ruBertот DeepPavlov в задаче выделения именованных сущностей (табл. 1) и в) на основе результатов сравнения Natasha с инструментом RusVectores при оценке качества эмбеддингов на задаче семантической близости (табл. 2).

Рис. 5. Основные библиотеки, включающие в себя эмбеддинги для русского языка
Таблица 1
Сравнение DeepPavlov и Natasha
|
Natasha, Slovnet NER |
DeepPavlov BERT NER |
|
|
PER/LOC/ORG F1 по токенам, среднее по Collection5, factRuEval-2016, BSNLP-2019, Gareev |
0.97/0.91/0.85 |
0.98/0.92/0.86 |
|
Размер модели |
27 МБ |
2 ГБ |
|
Потребление памяти |
205 МБ |
6 ГБ (GPU) |
|
Производительность, новостных статей в секунду (1 статья ≈ 1КБ) |
25 на CPU (Core i5) |
13 на GPU (RTX 2080 Ti), 1 на CPU |
|
Время инициализации, с |
1 |
35 |
|
Библиотека поддерживает |
Python 3.5+, PyPy3 |
Python 3.6+ |
|
Зависимости |
NumPy |
TensorFlow |
Таблица 2
Сравнение RusVectores и Navec
|
Среднее качество на 6 датасетах |
Время загрузки, секунды |
Размер модели, МБ |
Размер словаря, х103 |
||
|
Navec |
hudlit_12B_500K_300d_100q |
0,719 |
1,0 |
50,6 |
500 |
|
news_1B_250K_300d_100q |
0,653 |
0,5 |
25,4 |
250 |
|
|
RusVectores |
ruscorpora_upos_cbow_300_20_2019 |
0,692 |
3,3 |
220,6 |
189 |
|
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0,691 |
5,0 |
290,0 |
248 |
|
|
tayga_upos_skipgram_300_2_2019 |
0,726 |
5,2 |
290,7 |
249 |
Несмотря на то, что Natasha на 1 % показала качество ниже, чем DeepPavlov, размер ее модели меньше в 75 раз, потребление памяти меньше в 30 раз, а скорость работы на CPU выше в 2 раза, что, несомненно, делает библиотеки Natasha более приемлемым вариантом для решения поставленной задачи.
По таблице видно, что качество модели hudlit_12B_500K_300d_100q лучше, чем у моделей от RusVectores, при этом словарь больше в 2–3 раза, а размер модели меньше в 5–6 раз.
Используемая модель для построения эмбеддингов обучена на большом наборе текстов русской художественной литературы (более 300 тыс. текстов с размером словаря 5×105 элементов).
Пример использования программного решения для практической задачи
Данный программный комплекс был разработан для решения задачи автоматизации распределения обращений от граждан между различными министерствами. Семантическую близость необходимо было определить между входящим обращением и «функцией» министерства.
Важной особенностью решаемой задачи стало содержание большого количества вводных и общих фраз как для обращений граждан, таких как «Добрый день», «Прошу обратить внимание» и пр., так и в положениях о министерствах, таких как «участвует в разработке», «обеспечивает работу» и пр. Это значительно затруднило определение назначения обращения, поэтому привело к решению задачи о поиске значимых слов, только тех, которые точно передают функцию ведомства или суть обращения, и отбрасывании лишних.
После предварительной обработки программа показала высокую долю качественно распределенных обращений – 97,9 %.
Заключение
Особенностью решаемой авторами задачи по оценке семантического сходства текстов является то, что тематики текстов заранее не определены, они могут меняться в процессе работы, а также отсутствует обучающая выборка. Результаты анализа готовых программных решений задачи позволили сделать вывод о необходимости разработки собственного программного решения, в основу которого положены предложенные авторами функция принадлежности и алгоритм решения задачи.
Программный комплекс состоит из нескольких запускаемых файлов, связанных между собой по типу клиент-сервер. Клиентская часть программы имеет дружественный интерфейс и реализована на языке С#. Основная часть логики программы написана на языке Python. Для решения задачи следует использовать библиотеки проекта Natasha.
Программный комплекс апробирован для задачи автоматизации распределения текстовых обращений граждан между различными министерствами.
Программное решение может быть использовано при оценке сходства новых версий клинических рекомендаций в медицине с текущими.
Результаты исследований, приведенные в статье, частично поддержаны грантом РНФ 22-19-00471.
Библиографическая ссылка
Каспранская А.И., Сметанина О.Н. Программная реализация задачи оценки принадлежности текстов одной тематике // Современные наукоемкие технологии. 2022. № 8. С. 58-64;URL: https://top-technologies.ru/ru/article/view?id=39267 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.39267