



В настоящее время распознавание признаков на разнородных поверхностях с использованием мобильных устройств становится все более актуальным. Развитие технологий, а также пользовательский опыт в расширяющейся сфере мобильных устройств стимулирует развитие все более новых технологий, рассчитанных на мобильные устройства в самых разных областях народного хозяйства, в том числе в задачах сбережения различных видов цветов и растений. Однако на данный момент технологии по обработке изображений на базе мобильных устройств зачастую не приспособлены к мобильным устройствам в силу ограничений по вычислительным ресурсам последних. Также немалую роль играет возможность сбора достаточного объема набора данных для создания качественных моделей машинного обучения. На сегодняшний день диагностика болезней растений, идентификация повреждений на поверхностях нуждаются в участии человека, что вызывает соответствующие издержки на вызовы специалистов в район работ.
Современный пользовательский опыт с каждым годом все больше обращен в сторону мобильных технологий. Это, в свою очередь, порождает бурный рост количества исследований в области адаптации современных технологий к использованию на мобильных устройствах, включая как облачные сервисы, так и самостоятельные решения, работающие непосредственно на мобильном устройстве. В совокупности с трендом к цифровизации всех отраслей народного хозяйства, пользовательский опыт и рост числа исследований позволяют говорить о необходимости и возможности разработки технологий классификаций признаков на разнородных поверхностях.
Еще одной важной задачей является разработка такой технологии, которая могла бы эффективно функционировать на самых разнородных, но сходных морфологически датасетах. Таким образом, возникает задача разработки технологии машинного обучения, позволяющей осуществлять эффективную классификацию признаков на поверхностях с использованием малых разнородных выборок для обучения.
Целью исследования является разработка подхода к формированию сжатых моделей машинного обучения для высокоточной классификации объектов по их оптическим изображениям на основе малых выборок. Получаемые модели должны быть пригодны в том числе для мобильных устройств. Тем самым будет возможно решать задачи распознавания объектов и/или их свойств с помощью смартфонов, планшетов и иных видов мобильных устройств.
Материалы и методы исследования
Ранее такие задачи интеллектуальной обработки, как классификация изображений, решались в том числе и классическими методами машинного обучения [1, 2]. Позднее, с прорывом в области изучения когнитивных и обобщающих способностей нейронных сетей, на арену методов обработки изображений вышли сверточные нейронные сети, заняв на конкурсе ImageNet в 2012 г. первое место [3]. С тех пор сверточные нейронные сети постоянно совершенствовались, демонстрируя все более высокие показатели точности классификаций изображений. Появились такие архитектуры нейронных сетей, как ResNet [4], U-net [5], MobileNetV2 [6] и др. Обучение этих моделей машинного обучения составляло нередко довольно трудоемкий и ресурсоемкий процесс: один только датасет ImageNet состоял в 2019 г. из 14 миллионов изображений, принадлежащих различным классам объектов, и со временем датасет становится все больше [7], а время обучения нередко сопровождается значительными временными затратами, даже с использованием технологий параллельных вычислений на видеокартах. Для ряда задач уже существует способ избежать вычислительных издержек путем обучения нейросетей методом transfer learning [8]. Однако в силу небольшого объема либо полного отсутствия в ImageNet изображений, соответствующих области решаемой задачи (например, задаче идентификаций болезней растений, цветов), так или иначе возникает необходимость дообучения готовой модели. Это не всегда приводит к ожидаемому результату [9], точность классификации не превысила 87% при отсутствии возможности эффективного использования обученной модели на мобильном устройстве.
Предыдущие исследования
Чтобы избежать переобучения, а также необходимости создавать очень большой по величине датасет, ранее мы применили комплексный метод, основанный на обучении готовой модели transfer-learning методом с применением triplet-loss ошибки [9].
Ранее разработанная технология представлена схемой на рис. 1, на которой отражены следующие процессы:
− обучение сиамской нейронной сети-экстрактора признаков с применением triplet-loss-функцией ошибки;
− сжатие обученной модели с помощью применения методов квантизации;
− обучение классификатора признаков многослойного перцептрона.
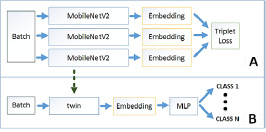
Рис. 1. Схема технологии создания сжатой модели – классификатора признаков
Реализованная нами ранее модель тестировалась на специально собранном датасете растений PDD [9]. Результаты эксперимента убедительно доказали применимость технологии для классификации признаков на поверхностях растений. Точность модели с применением таких подходов, как transfer-learning, сиамских нейронных сетей, а также обучение с применением функции ошибки triplet-loss, составила 99,5%. Применяемая архитектура: MobileNetV2.
Ключевой особенностью технологии является возможность one-shot обучения на выборках малого объема и применение квантизации модели с целью уменьшения ресурсоемкости процесса обучения.
Квантизация
Использовались следующие виды квантизации: статическая и динамическая.
Статическая квантизация заключается в замене весов модели, хранящихся, как правило, в формате float, занимающем в памяти 4 байта, на значения типа int8, занимающем в памяти лишь 1 байт (табл. 1) в соответствии с формулой (*).
Таблица 1
Ресурсозатраты на значения в разных типах данных
|
Память |
Такты процессора |
|
|
INT8 |
2 байта |
1–3 такта |
|
FLOAT32 |
8 байт |
2–8 тактов |
Конкретные пределы минимальных и максимальных значений конкретного веса определяются с помощью модулей-наблюдателей, накапливающих статистику в ходе обучения о минимальных и максимальных пределах, в которых находилось значение веса за весь период обучения.
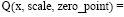
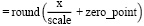 , (*)
, (*)
где x – исходное значение веса,
scale – масштабирующий коэффициент,
zero_point – нулевой сдвиг.
Общий алгоритм статической квантизации модели выглядит следующим образом:
1) в исходной модели выбираются области с весами, за которыми закрепляются модули-наблюдатели;
2) производится обучение модели, в процессе которого наблюдатели определяют диапазоны весов;
3) по формуле (*) вычисляются целочисленные значения весов.
Сигнал в сети распространяется следующим образом:
1) на вход модели подаются квантизированные значения в формате int8;
2) выходные значения (inferences, в случае квантизации только сверточной подсети – экстрактора признаков) модели преобразуются вновь в значения float.
Динамическая квантизация включает в себя статическое (преобразование весов в int8), а также квантизацию активаций модели «на лету», что и объясняет динамичность процесса. Поскольку в иных видах квантизации преобразуются к int8 только веса модели, а сигналы, образующиеся на выходах активаций, остаются вещественными float-переменными, то и передаваемые между слоями сигналы все же остаются вещественными числами. Квантизация активаций позволяет получать на их выходах уже значения int8, что должно способствовать ещё большему ускорению и сжатию модели.
Эксперимент
С целью оценки точности классификации на датасете, отличном от ранее использованного датасета PDD, был проведен эксперимент по классификации изображений на датасете с изображениями поверхностей цветов.
Основной задачей эксперимента является также и оценка применимости модели на мобильных устройствах, а также меньшие ресурсозатраты при формировании обучающих датасетов и обучения модели в целом. Ключевыми факторами, напрямую влияющими на ресурсозатратность всего процесса обучения, являются:
1. Величина обучающей выборки.
2. Размер готовой сжатой модели в Мб.
3. Скорость работы сжатой модели.
Для оценки потерь в точности классификации при обучении малыми выборками, мы провели сравнительные эксперименты не только на полном наборе обучающих данных, но и на сокращенном наборе данных: Flower Recognition, Flower Recognition, Small Flower Recognition соответственно.
Flower Recognition – это открытый набор данных с изображениями цветов, загруженных на платформу Kaggle. В этом наборе данных 4242 изображения цветов (пример на рис. 2). Сбор данных основан на данных flickr, google images, yandex images. Набор данных содержит такие классы, как ромашка, тюльпан, роза, подсолнух, одуванчик. Для каждого класса есть около 800 фотографий. Фотографии имеют невысокое разрешение, около 320x240 пикселей. Для экспериментов были определены два типа этого набора данных. Для одного эксперимента был взят полный набор данных, для другого набор данных был обрезан, и для каждого из классов было сделано менее 50 изображений.
Основные параметры датасетов, в том числе и параметры ранее применявшегося датасета PDD, приведены в табл. 2.
Была произведена серия экспериментов для каждого из наборов данных с применением и без применения методов квантизации. Результаты экспериментов приведены в табл. 3.
Результаты исследования и их обсуждение
В ходе экспериментальных исследований выяснилось, что точность классификации на новом, несжатом датасете незначительно ниже показателя точности для модели, обученной на первоначальном обучающем наборе. Чуть больший отрыв по качеству классификации у PDD и Small Flower Dataset – сокращенной версии исходного датасета: 87–90%. Однако важно учесть, что:
1. PDD более чем в два раза превосходит Small Flower Dataset по количеству изображений.
2. Наименьшие показатели точности, полученные для квантизированных моделей, являются достаточными для эффективного применения обученных моделей на мобильных устройствах в полевых условиях.
Среди методов квантизации наиболее эффективным оказался метод статической квантизации: при практически полном отсутствии разницы в показателях точности классификации с моделью, полученной с применением динамической квантизации, размер модели, полученной с применением статической квантизации, отличается почти в два раза, а время, затрачиваемое на обработку ста изображений, меньше почти в семь раз. Это объясняется, прежде всего, наличием дополнительных блоков, предназначенных для реализации динамической квантизации активации моделей.

Рис. 2. Пример датасета с изображениями поверхностей цветов
Таблица 2
Параметры массивов данных
|
Наименование |
Количество изображений |
Количество классов |
Краткое описание |
|
PDD |
611 |
15 |
Фотографии листьев больных и здоровых растений |
|
Flower Recongnition |
4242 |
5 |
Фото цветов из интернета |
|
Small flower recongition |
250 |
5 |
Сокращенная версия датасета с изображениями цветов |
Таблица 3
Показатели точности классификации и ресурсоемкости процесса обучения квантизованных моделей в сравнении с исходными
|
Метрика |
Без квантизации |
Динамическая квантизация |
Статическая квантизация |
|
Точность на датасете PDD |
98% |
98% |
98% |
|
Точность на Flower dataset |
96,3% |
94,2% |
96,4% |
|
Точность на значительно уменьшенном Flower dataset |
90% |
88% |
87% |
|
Время, затраченное на обработку 100 изображений, с |
14,2 |
14,2 |
2,6 |
|
Размер модели, Мб |
18,6 |
13,2 |
7,6 |
Таким образом, технология обучения сжатых моделей применима не только к задаче классификации признаков на растениях с целью идентификации признаков на поверхностях растений, но также и для классификации признаков на поверхностях цветов, что и подтверждают показатели точности, приведенные в табл. 3.
Практическая применимость
В ходе разработки технологии был разработан Телеграм-бот и мобильное приложение Android.
Телеграм-бот представляет собой интерфейс, посредством которого пользователь может получить топ-5 результатов прогнозирования, по убыванию вероятности принадлежности изображения к тому или иному классу (рис. 3).
Модель, используемая в боте, запускается в Docker-контейнере. Приложение реализовано с помощью Python с использованием Telegram API tools.
Мобильное приложение для Android представляет собой уже самостоятельную программную единицу, результаты вычисления которой уже не зависят от наличия соединения с сервером, осуществляющим расчеты, предоставляющего интерфейс и т.д. Загрузив данное приложение на мобильное устройство, пользователь получает возможность офлайн-классификации загруженного изображения растения или цветка из галереи (рис. 4).

Рис. 3. Скриншоты, демонстрирующие работу с Телеграм-ботом
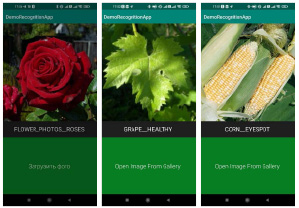
Рис. 4. Скриншоты, демонстрирующие работу приложения
Реализация мобильного приложения осуществлялась на языке программирования Java в Android Studio. Рабочий экземпляр приложения на устройстве включает в себя статически квантизированную модель сверточной триплет-сети-экстрактора признаков и классификатор на основе многослойного перцептрона.
Имея на своем устройстве мобильное приложение, пользователь получает возможность офлайн классификации изображений малой (квантизированной) моделью. В то же время у пользователя остается возможность более точной классификации изображений неквантизированными моделями посредством Телеграм-бота при наличии сети Интернет.
Заключение
В данной работе предложен и протестирован подход к формированию сжатых моделей машинного обучения для высокоточной классификации объектов по их оптическим изображениям на основе малых выборок. Здесь применена модель машинного обучения, созданная с применением комбинаций таких методов машинного обучения, как transfer-learning, Сиамская сеть, с обучением классификатора с MLP и трехчленной функцией ошибки. Эти методы показали свою эффективность как для небольших наборов данных (90%), так и для наборов с классами, сходными по морфологии с ранее использовавшимся датасетом PDD (96,3%).
В будущем планируется продолжить исследования, рассмотреть такие архитектуры, как, например, U-net, RNN, а также провести больше экспериментов с наборами данных, схожих по морфологии.
Исследование выполнено в рамках НИР Университета ИТМО «Разработка технологии формирования моделей машинного обучения малого объема в целях распознавания признаков на изображениях с высокой точностью при сверхмалых выборках данных».
Библиографическая ссылка
Сметанин А.А., Першуткин А.Э., Духанов А.В. КЛАССИФИКАЦИЯ ПРИЗНАКОВ НА ПОВЕРХНОСТЯХ ЦВЕТОВ С ПОМОЩЬЮ СЖАТЫХ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ // Современные наукоемкие технологии. 2022. № 6. С. 29-34;URL: https://top-technologies.ru/ru/article/view?id=39195 (дата обращения: 12.07.2026).
DOI: https://doi.org/10.17513/snt.39195