



Технологии искусственного интеллекта стремительно развиваются и позволяют решить многие задачи, что зачастую ранее сделать было невозможно. Вопросы лингвистического взаимодействия машины и человека связаны с областью обработки естественного языка. Одним из примеров решения задач в этой области является создание чат-ботов, таких что человек не всегда поймет, что с ним общается «искусственный интеллект». В целом область обработки естественного языка включает в себя множества задач, таких как распознавание речи, машинный перевод, выявление спама, голосовые помощники и пр.
В области анализа текста немаловажную роль играет задача оценки сходства текстов, в том числе и семантического. Среди исследователей в области обработки естественного языка, посвятивших свои работы оценке сходства текстов, можно отметить таких авторов, как В.Б. Барахнин, В.А. Нехаева, А.М. Федотов [1], А.Е. Письмак, А.Е. Харитонова, Е.А. Цопа, С.В. Клименков [2], А.В. Крюкова [3], Хиен Т. Нгуен, Фук Х. Дуонг [4], А. Розева, С. Зеркова [5], А.Х. Хакимова, М.М. Чарнин, А.А. Клоков, Е.Г. Соколов [6], Б. Мааке, С. Оджо, Т. Зува [7].
Активный интерес исследователей к вопросу автоматической обработки текста подтверждает актуальность тематики в области решения вопроса об оценке семантической близости текстов. Ряд работ посвящен математической оценке сходства текстов, что не всегда может учитывать смысловую часть слова. Например, использование меры близости вместо меры сходства может породить ошибочные результаты (возможно ошибочное использование меры Левенштейна и др.). В другой части исследований можно обратить внимание, что решение связано с определенной заранее известной тематикой, построением ключевых слов либо векторного представления слов по заранее заданным текстам. Анализ современного состояния проблемы позволил сделать заключение, что такие решения не подходят для заранее неизвестных текстов произвольной тематики.
Исследование посвящено определению принадлежности двух текстов одной теме. В ходе работы необходимо провести анализ современного состояния проблемы, рассмотреть предложенные решения. Важной особенностью поставленной задачи является произвольная и заранее неизвестная тематика текстов, которая не позволит обучить собственную модель на некотором ограниченном наборе данных.
Современное состояние проблемы
В рамках решения задач NLP, например расширения запросов при поиске, оценке схожести текстов и др., используются различные меры сходства.
Для оценки меры близости текстов могут использоваться следующие метрики: с использованием n-грамм, расстояние Левенштейна, вычисление самых длинных подпоследовательностей, подстрок, косинусовая близость и пр.
Автор А.В. Крюкова в своей работе [3] при сравнении различных мер показала, что наибольшая важность для итогового решения имеет косинусовая близость.
Для оценки близости наборов текстов также используются алгоритмы кластеризации с выделением некоторых характеристик текстов [1], при этом методы кластеризации нельзя применить при оценке смысловой близости двух текстов.
Одним из способов оценки могут служить алгоритмы с использованием заранее подготовленных корпусов для языка [8], в которых для каждого слова определена его семантическая близость с другими словами. К сожалению, такие корпуса разработаны не для всех языков или не находятся в свободном доступе.
Результаты анализа современного состояния проблемы показали, что нужно разработать подход, позволяющий оценить принадлежность двух текстов одной тематике.
Постановка задачи
Формальная постановка задачи может быть представлена с использованием нотации IDЕF0 (рис. 1).
Для задачи оценки сходства заранее неизвестных текстов на русском языке на произвольные темы используется функция определения принадлежности текстов одной теме.
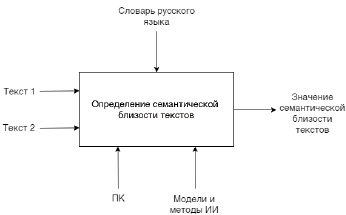
Рис. 1. Формальная постановка задачи определения семантической близости текстов
Дано: два произвольных текста – textj, где j=1, 2, состоящих из отдельных слов textj = (tij, .., tni),textj– j-й текст, tij– i-е слово в j-м тексте, n – количество уникальных слов.
Определить: значение принадлежности –
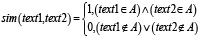 ,
,
где sim(text1, text2) – функция определения принадлежности текстов одной теме, text1и text2– два текста, для которых определяется принадлежность, А – некоторая тема, которой могут принадлежать тексты.
На вход программы подается два текста, на выходе получаем числовое значение семантической близости из диапазона [0, 1]. При этом, чем значение ближе к 1, тем ближе семантическая близость текстов.
Предлагаемый подход к решению задачи
В постановке задачи имеется два текста на различные, заранее не определенные темы. Неопределенность темы является важной особенностью данной задачи, так как это ограничение не позволяет натренировать собственную модель машинного обучения для задачи классификации. Тексты представлены на русском языке. Предлагается следующий алгоритм решения (рис. 2).
Для обработки текста машиной необходимо привести его к более подходящему для обработки виду. Все шаги алгоритма насмотрены на примере текста о центральном процессоре: «Центра́льный проце́ссор – электронный блок либо интегральная схема, исполняющая машинные инструкции (код программ), главная часть аппаратного обеспечения компьютера или программируемого логического контроллера. Иногда называют микропроцессором или просто процессором».
Проводится процесс лемматизации, то есть слова заменяются нормальной формой. Такой набор слов называется набором токенов. Далее токены собираются в мешок слов. Мешок слов – представление текста в виде набора нормализованных уникальных слов текста. Мешок слов переводится в мешок векторов, то есть каждому элементу сопоставляется вектор, полученный из модели машинного обучения.
Текст подготовлен, и для определения близости текстов было расширено следующее правило – чтобы определить близость двух слов, нужно перевести их в векторы и посчитать косинус угла между ними.
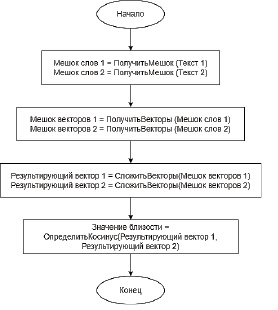
Рис. 2. Алгоритм решения задачи оценки близости текстов
Алгоритм перевода текстов можно описать следующим образом:
1. Для каждого токена из текста подбираем эмбеддинг (вектор). Можно представить текст как
textj = (tij, .., tni) =>(eij, .., enj) = embj,
где textj – набор токенов входящих в j-й текст, tij– i-й токен в j-м тексте, eij – i-й эмбеддинг (вектор) в j-м тексте, n – количество уникальных токенов в тексте и соответствующих векторов, embj – представление текста в виде набора векторов.
2. Складываем все вектора и получаем результирующий для всего текста
ResVj = ∑embj,
где ResVj – результирующий вектор для текста j, embj – набор соответствующих токенам текста векторов.
Так, тексты определяются в n-мерном векторном пространстве (рис. 3).
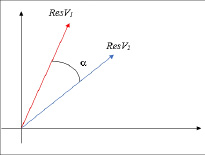
Рис. 3. Представление текстов в виде векторов
Представление в векторном пространстве такое, что чем ближе находятся векторы друг к другу, тем более близкие значения они представляют с точки зрения семантики. Из чего следует, что угол a1) на техническую тему – «Микропроце́ссор – процессор (устройство, отвечающее за выполнение арифметических, логических операций и операций управления, записанных в машинном коде), реализованный в виде одной микросхемы или комплекта из нескольких специализированных микросхем (в отличие от реализации процессора в виде электрической схемы на элементной базе общего назначения или в виде программной модели)»;
2) текст из ботаники – «Рома́шка – род многолетних цветковых растений семейства Астровые, или Сложноцветные, объединяет около двадцати видов невысоких пахучих трав, цветущих с первого года жизни».
Для всех текстов были посчитаны результирующие векторы, а после косинусовые меры близости для пар текстов:
1. Центральный процессор – микропроцессор (близость – 0,8698).
2. Центральный процессор – ромашка (близость – 0,1428).
Полученные результаты показывают, что тексты на одну тематику, техническую, имеют более близкое значение семантической близости, чем тексты на разные тематики.
При решении задачи использованы библиотеки проекта Natasha, которые предоставляют инструменты для решения базовых задач обработки естественного русского языка, а именно – сегментацию на токены и предложения, синтаксический и морфологический анализ, лемматизацию, извлечение именованных сущностей. Для сопоставления токенам эмбеддингов использовалась модель hudlit_12B_500K_300d_100q из библиотеки Navec. Эта модель имеет размер словаря в 500 000 записей и была обучена на текстах художественной литературы объемом 145 GB, благодаря этому она покрывает 98 % слов в художественных текстах [9].
Вычислительный эксперимент
Для проверки работоспособности предлагаемого решения задачи и оценки его корректности был составлен набор из 1000 парафраз на основании корпуса парафраз В. Гудкова и О. Митрофановой [10]. Оригинальный корпус парафраз был размечен по смыслу предложений. Фразы: 1. «У меня есть пять яблок» и 2. «У меня нет пяти яблок» ранжировались как различные. Для рассматриваемого исследования такое ранжирование не подходит, так как цель – определить принадлежность текстов одной теме. А в данном случае обе фразы о яблоках. Поэтому способ ранжирования был изменен.
Для определения границы принадлежности текста теме была проведена серия из 8 запусков алгоритма с разными показателями в диапазоне [0,4; 0,57]. Границы диапазона определялись в случае существенного ухудшения точности алгоритма. Результаты прогонов представлены на рис. 4, и итоговая граница была определена – 0,51. Это значит, что если значение косинусовой близости текстов больше или равно этому значению, то тексты определяются как принадлежащие одной теме, в противном случае тексты принадлежат различным темам.
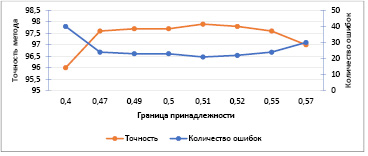
Рис. 4. Подбор значения для определения границы принадлежности текста
В результате прогона набора из тысячи пар текстов была получена точность решения – 97,9 %. Это является хорошим показателем для модели, обученной на художественной литературе русского языка без дополнительного дообучения узким предметным областям, которым могли принадлежать тексты.
Заключение
Результаты анализа текущего состояния проблемы в области оценки сходства текстов показал ее актуальность и необходимость более эффективного решения задачи.
В основу предложенного решения положены перевод текстов в векторное представление и нахождение косинусовой близости между ними. Особенностью решения является использование модели, обученной на больших наборах разнообразных текстов на русском языке. Это позволяет процесс распознавания близости между текстами представить наиболее похожим на то, как это делает человек. Однако модель представляет и самое уязвимое место в решении: если тексты специфические, то модель может не знать используемых слов; если сравниваются тексты не очень близкие друг другу по смыслу, то для корректной работы требуется дополнительная обработка текстов – нахождение уникальных слов внутри тем с отбрасыванием лишних.
При решении была использована готовая модель для построения эмбеддингов (библиотеки проекта Natasha), которая обучена на большом наборе текстов русской художественной литературы, включающем в себя более 300 тыс. текстов, с размером словаря 5×105 элементов. Точность работы была определена в ходе вычислительного эксперимента и составила 97,9 % на наборе объёмом 1000 пар текстов, основанном на наборе парафраз для русского языка. Идея показала свою работоспособность и может иметь практическое применение в решении задач определения близости текстов для различных тематик.
Результаты исследований, приведенные в статье, частично поддержаны грантом РНФ 22-19-00471.
Библиографическая ссылка
Каспранская А.И., Сметанина О.Н. Подход к оценке принадлежности текстов одной тематике // Современные наукоемкие технологии. 2022. № 5-1. С. 43-47;URL: https://top-technologies.ru/ru/article/view?id=39148 (дата обращения: 24.07.2026).
DOI: https://doi.org/10.17513/snt.39148