



В современном мире обучающийся не привязан больше ни к учителю, ни к своей среде обитания. Цифровые коммуникационные технологии дают ему возможность выбирать, где и чему учиться, в какой среде развиваться, в какую деятельность включаться.
Успех в этой новой, все более цифровой системе образования определяет, насколько обучение адаптирует человека к текущему социально-экономическому укладу. Его развитие все больше зависит от способности постоянно адаптироваться, изменяться, эффективно осваивать новую деятельность и приобретать новые профессиональные качества [1].
Это предъявляет новые, принципиально другие требования к системе образования. В мире, где студент имеет возможность выбирать, где, как, когда и чему учиться, задача системы не в том, чтобы обеспечить качественно высокий уровень каждого конкретного преподавателя, обучающего конкретному предмету, а в том, чтобы:
− обеспечить студента инструментами для осознанного выбора;
− технологиями навигации в пространстве образовательных возможностей;
− надежными средствами оценки эффективности того или иного образовательного процесса.
Цифровой след – это постоянно пополняемый набор данных, включающий значения показателей, созданных самими студентами [1]. В их числе рефераты и обзоры литературы, курсовые, отчеты по практикам, описания проектов, выпускные квалификационные работы, эссе и мотивационные письма на конкурсы. Именно из этих текстов современные методы анализа данных позволяют извлечь объективную информацию для диагностики профессиональной компетентности выпускника и выявить факторы, которые повлияли на ее формирование [2].
Целью исследования является разработка системы траектории электронного обучения на основе цифрового следа с использованием распределенной системы сбора и анализа цифрового следа обучающегося вуза.
Материалы и методы исследования
К основным методам исследования относятся анализ литературы, моделирование, вычислительный эксперимент. Анализ литературы (интернет-статьи о методах и способах организации систем сбора данных), связанной с обработкой цифрового следа, использован при анализе предметной области. Метод моделирования использован при создании модели распределенной системы. Экспериментальный метод исследования использован для проверки работоспособности созданной системы. Разработка системы сбора и анализа цифрового следа студента включает совокупность выбранных методов и технологий. К ним относятся работа с базами данных на основе SQL запросов, стемминг текста, парсинг сайтов, работа с базой данных PostgresSQL, тематическое моделирование текстов при помощи BigARTM.
Результаты исследования и их обсуждение
Электронное образование – это система обучения, осуществляемая при помощи информационных и электронных технологий. На данный момент развитие электронной информационно-образовательной среды (ЭИОС) является одним из приоритетных направлений всех образовательных учреждений, так как это позволяет всем получать своевременный, удобный и равноценный доступ к материалам для обучения, а сам процесс обучения становится более прозрачным и понятным как студентам, так и людям вне образовательных учреждений. Основное положение, регламентирующее, из чего должна состоять электронная образовательная среда, включает в себя организационно-методические средства, совокупность технических и программных средств хранения, обработки, передачи информации, обеспечивающая оперативный доступ к информации и осуществляющая образовательные научные коммуникации [3].
Траектория образовательного процесса – путь или движение по образовательной среде обучающегося индивида. Основным отличием новой системы станет возможность ее анализа, а значит, и появления способа повлиять на нее.
Отличительной особенностью модели траектории электронного обучения на основе цифрового следа станет включение в нее распределенной системы сбора и анализа цифрового следа обучающегося [4]. Обычно цифровой след собирается по результатам достижений обучающихся, что не дает представления о путях к этим достижениям. Поэтому было решено изменить место его сбора в процессе получения знаний по конкретной дисциплине.
Основной задачей исследования является отслеживание и нахождение цифрового следа пользователей, его обработки и извлечения из него полезной информации. В работе в качестве основного источника информации цифровых следов рассмотрен компьютер дисплейного класса университета. Сбор и анализ цифрового следа обучающегося включает в себя сбор данных с компьютера дисплейного класса; передача полученных данных на сервер; сохранение данных в хранилище. После сбора данных будет происходить их первоначальный анализ для определения наиболее частых употребляемых слов или фраз на посещенных ими сайтах при помощи вычисления тематики сайтов, а также частотности их посещения [5]. Для этого надо решить следующие задачи, связанные с разработкой и реализацией способов сбора данных с компьютера, хранения и анализа, просмотра и вывода полученных данных, а также более детального рассмотрения каждой записи данных в системе.
При разработке ПО для анализа цифрового следа в университете будут использованы следующие модули:
− приложения C# для сбора истории посещенных сайтов из браузера Google Chrome;
− PostgreSQL для хранения всех полученных данных;
− алгоритм классификации данных при помощи алгоритмов через получение тематики текстов (собранных при помощи алгоритмов, описанных ранее), реализованные на языке Python.
Выбор алгоритма анализа данных проведен по следующим критериям: сложность разработки и настройки, скорость работы приложения, системные требования к аппаратному обеспечению.
Сама же обработка данных будет из двух этапов:
1) формирование выборки текста сайта при помощи парсера. Данный алгоритм будет рассмотрен в следующей главе;
2) построение модели классификации сайта по тематикам на основе полученных текстов, определение их приближенности к эталонному исходному документу. В качестве исходного документа можно использовать рабочие программы дисциплин (РПД).
Для решения поставленных задач необходимо реализовать следующие задачи:
1) изучить тематику дисциплины на основе РПД. Необходимо будет ввести в систему данный документ для возможности сравнения посещенных сайтов с выявленной тематикой и определения схожих элементов;
2) составить анализ тематик на основе тематического моделирования всех посещенных во время занятий сайтов в виде весов ключевых слов текста (токенов). Текст предварительно выбелить путем стемминга текста и удаления стоп-слов или словосочетаний, то есть частей текста, не несущих смысловой нагрузки;
3) построить модель и сравнить все построенные ранее тематические модели документов на предмет совпадений.
Преподаватель занимает место тьютора в процессе образования, что поможет разгрузить его время от монотонных действий, а студент может получить доступ к предлагаемой информации в любое удобное время. Основным плюсом является возможность быстрой эффективной оценки не только конкретных достижений в процессе обучения, но даже экспертной оценки самого процесса обучения, что и является основной новизной данной модели и работы в целом (рис. 1).
Модель работы системы по сбору и анализу цифрового следа обучающегося, включая все процессы от начала сборки данных до получения выходных данных, позволяет понять механизм распределения обязанностей внутри системы цифрового следа (рис. 2).
Система состоит из следующих компонентов: N клиентов для сбора информации (приложение на С# для сбора данных по истории посещения сайтов с браузера); сервера хранения данных (СУБД – PostgreSQL для хранения всех данных); сервера анализа и обработки данных (приложения на Python для классификации сайтов).
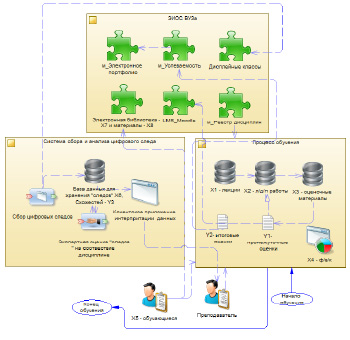
Рис. 1. Архитектура системы «Электронное образование»
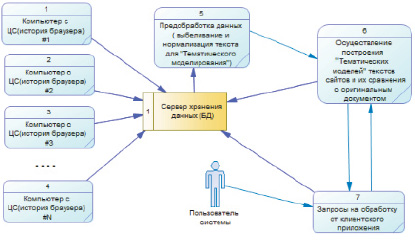
Рис. 2. Схема работы системы по получению и обработке цифрового следа
Основным отличием представленной модели является наличие клиента для работы с системой. Запросы на получение выходных данных, а также ввод исходного документа будет осуществляться при помощи клиентского приложения, но система будет полностью автономной и может работать без него. Клиентское приложение должно решать задачу создания удобного интерфейса работы с распределенной системой сбора и анализа цифрового следа.
Сервер системы должен поддерживать работу с несколькими потоками для осуществления своевременной обработки данных, используя параллельную работу, что обеспечит ускорение обработки данных.
Анализ данных будет осуществляться при помощи алгоритма тематического моделирования методом вероятностного латентно-семантического анализа. Формула разделения текстов на тематики, используемая в технологии bigARTM, имеет вид
р(d, w) = ∑ р(t)р(w|t)р(d|t), t ∈ T
где t – тема;
р(t) – неизвестное априорное распределение тем во всей коллекции;
р(d) – априорное распределение на множестве документов: р(d) = nd / n – длина документов;
р(w) – априорное распределение на множестве слов: р(w) = nw / n, где nw – число вхождений слова w во все документы.
Пример разделения сайтов по тематическим моделям можно представить в виде схем тематического анализа двух документов из статей «Ботаника» и «Астрология» (рис. 3).

Рис. 3. Пример тематического моделирования текста
После получения списка вероятностей совпадения тем необходимо получить модель поведения студентов. Сравнение исходного документа со всеми сайтами, посещенными студентами во время занятий, отсеянных при помощи фильтра по времени посещения, использование описанного ранее алгоритма даст представление о качестве получаемой студентами информации из сети Интернет.
Система берет на входе исходный документ, описывающий изучаемую дисциплину, сравнивая со всеми известными сайтами, подходящими по условию. В итоге получаем коэффициент полезности времени, проведенного студентами на сайтах.
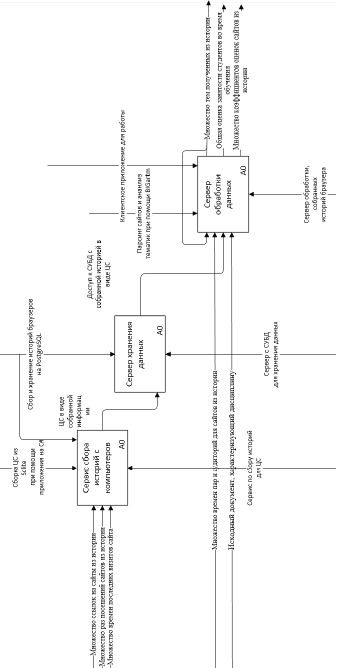
Рис. 4. Полная модель данных
Выборки данных для распознавания полезности сайта
|
Тестовая выборка |
Ожидаемый ответ |
Тестовая выборка |
Ожидаемый ответ |
|
Текст с сайта «youtube.com» |
30 % полезности |
Текст с сайта «esstu.ru» |
50 % полезности |
|
Текст с сайта «intuit.ru» |
70 % полезности |
Текст с сайта «esstu.ru» |
0 % полезности |
|
Текст с сайта «tiktok.com» |
0 % полезности |
Текст с сайта «esstu.ru» |
80 % полезности |
В таблице приведен пример ожидаемого ответа от программы. То есть система будет говорить, был ли полезен каждый сайт по отдельности, а потом интегрировать все полученные данные и давать итоговый вердикт.
При решении данной комплексной задачи будет использоваться готовое решение на основе библиотеки BigARTM, функциональная модель которой состоит из трех блоков (рис. 4).
Запрос такого анализа при помощи BigARTM будет осуществляться через удобный пользователю графический интерфейс, который получает на вход исходный документ, характеризующий дисциплину.
На основе полученных выходных данных система может дать рекомендации по сайтам, которые обучающиеся посещали чаще остальных. Это должны быть сайты, подходящие под тематику заданной дисциплины, так как они помогут обучающимся следующих курсов лучше освоить преподаваемую дисциплину.
Заключение
Предложенный в работе «цифровой переход» позволяет улучшить взаимодействие между участниками образовательного процесса и повысить качество освоения образовательной программы. Разработка системы обработки цифрового следа в образовательном учреждении является одним из ключевых элементов в цифровизации основного процесса и позволяет выстраивать индивидуальную образовательную траекторию обучающегося.
Библиографическая ссылка
Михайлова С.С., Данилова С.Д., Веселов А.В. РАСПРЕДЕЛЕННАЯ СИСТЕМА СБОРА И АНАЛИЗА ЦИФРОВОГО СЛЕДА ОБУЧАЮЩЕГОСЯ ВУЗА // Современные наукоемкие технологии. 2022. № 4. С. 62-67;URL: https://top-technologies.ru/ru/article/view?id=39109 (дата обращения: 06.07.2026).
DOI: https://doi.org/10.17513/snt.39109