



При эксплуатации нефтяных скважин для увеличения производительности и повышения экономической эффективности скважины применяются геолого-технические мероприятия (ГТМ) – комплекс мер геологического, технологического, технического и экономического характера. Существует несколько видов ГТМ, таких как гидроразрыв пласта, обработка призабойной зоны, смена частоты ЭЦН, оптимизация, вывод из бездействия.
При подборе скважин-кандидатов на определенное мероприятие используются различные параметры скважины, такие как пластовое давление, забойное давление, текущие дебиты жидкости и нефти, вязкости и другие, а также статистические данные скважины.
Автоматизация первичного подбора скважин на геолого-технические мероприятия с помощью информационных систем позволяет значительно повысить эффективность и оперативность данного процесса [1].
После процесса первичного подбора скважин происходит процесс согласования ГТМ для каждой предложенной скважины – специалист либо согласовывает ГТМ либо отклоняет с указанием причины. Причины отклонения могут быть связаны с недостатком данных, аномальными данными либо организационными причинами. Список причин отклонения может отличаться для каждого вида ГТМ.
Процесс согласования и отклонения геолого-технических мероприятий для скважин является трудоемким ввиду большого количества скважин и причин отклонения. Автоматическая классификация скважин по причинам отклонения может существенно повысить оперативность работы специалистов.
В данной статье рассмотрен подход к разработке системы классификации скважин-кандидатов на геолого-технические мероприятия по причинам отклонения.
Постановка задачи
Имеющаяся в системе автоматизированного подбора скважин на геолого-технические мероприятия информация может прямо или косвенно указывать на невозможность проведения данного мероприятия. К примеру, показатель пластового давления может указывать на причины «Низкое пластовое давление» либо «Аномально высокое пластовое давление», информация о состоянии скважины может указывать на причину «Запущена в работу в текущем месяце», информация о целевых параметрах скважины может указывать на причину «Отсутствие эффекта от ГТМ».
Таким образом, наличие в системе данных о скважине даёт возможность составить предварительную классификацию либо ранжирование скважин по причинам отклонения. Наличие множества возможных причин отклонения для каждого отдельного вида геолого-технического мероприятия характеризует данную задачу как задачу многоклассовой классификации.
Необходимо разработать программное решение в виде API-службы, позволяющее обучить классификатор на заданной обучающей выборке, а также классифицировать заданную скважину-кандидата по причинам отклонения, соответствующим данному типу геолого-технического мероприятия.
Математическая постановка задачи классификации скважин-кандидатов на геолого-технические мероприятия может быть сформулирована следующим образом.
Дано: множество параметров скважин-кандидатов на геолого-технические мероприятие Xгтм = {x1, x2,…, xn}, множество причин отклонения для данного геолого-технического мероприятия Yгтм = {y1, y2,…, yn}, где ГТМ ∈{ОПТ, ОПЗ, ГРП, УВЧ, ВБД, ВБД ПФ}, где ОПТ – оптимизация, ОПЗ – обработка призабойной зоны, ГРП – гидроразрыв пласта, УВЧ – изменение частоты ЭЦН, ВБД – вывод из бездействия, ВБД ПФ – вывод из бездействия прочего фонда – возможные геолого-технические мероприятия.
Разработать: алгоритмы aГТМ:XГТМ → YГТМ, способные классифицировать произвольную скважину xГТМ∈XГТМ.
Данная задача относится к классу задач многоклассовой классификации.
Подход к решению задачи многоклассовой классификации
Для решения задачи классификации скважин-кандидатов по причинам отклонения использован метод классификации с помощью нейронной сети. Обучающая выборка построена на основе данных из системы согласования скважин-кандидатов на геолого-технические мероприятия.
При построении обучающей выборки необходимо использовать только те скважины-кандидаты на геолого-технические мероприятия, признак согласования либо причина отклонения которых встречались в исходной выборке более 10 раз. Это ограничение связано с тем, что использование классов, для которых размер обучающей выборки меньше определённого числа не позволяет выполнить балансировку данных без потери обучающей способности нейронной сети.
При разработке классификатора были задействованы этапы, представленные на рис. 1.
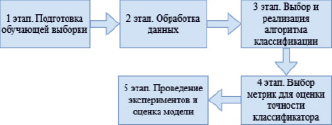
Рис. 1. Этапы разработки классификатора
Исходными параметрами алгоритма является вектор параметров для каждой i-й скважины 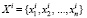 , который включает в себя такие данные, как:
, который включает в себя такие данные, как:
- Остановочные параметры скважины (дебит жидкости, нефти, забойное давление, пластовое давление, давление насыщения, линейное давление, обводненность).
- Потенциальные параметры скважины (дебит жидкости, нефти, обводненность, забойное давление).
- Параметры экономической эффективности скважины (Суммарные затраты на ГТМ, NPV, PI).
- Предыдущая причина отклонения (если возможно).
- Признак месторождения.
На основе этих данных алгоритм классифицирует скважину в один из 11 классов Yi (ГТМ принят, низкая экономическая эффективность, аварийный фонд, некорректные данные, и т.д.).
В связи с тем, что входные данные алгоритма имеют разные типы и области значений, данные в исходном виде могут оказывать разное влияние на обучение нейронной сети [2]. Для того чтобы избавиться от этого фактора, применяется нормализация данных. Среди входных параметров выделяются:
- Численные (Дебиты, давления, обводненность, экономические параметры).
- Категориальные (Признак месторождения, предыдущая причина отклонения).
Для нормализации численных параметров применяется метод минимаксной нормализации – 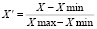 [3]. Для нормализации категориальных параметров применяется метод унитарного кода, при котором каждому из возможных значений признака сопоставляется отдельный бинарный признак [4].
[3]. Для нормализации категориальных параметров применяется метод унитарного кода, при котором каждому из возможных значений признака сопоставляется отдельный бинарный признак [4].
В наборах данных часто оказывается так, что какие-либо классы присутствуют в большем количестве, чем другие. Такие наборы данных могут негативно влиять на обучение нейронной сети, так как более присутствующие классы будут оказывать большее влияние на обучение, чем менее присутствующие [5, 6]. Для решения проблемы несбалансированности данных в обучающей выборке используется алгоритм SMOTE (Synthetic Minority Oversample Technique), суть которого заключается в генерации искусственных экземпляров миноритарного класса [7]. Искусственные экземпляры генерируются в «соседних» областях с помощью алгоритма ближайшего соседа (KNN).
При разбиении исходных данных на обучающую и тестовую выборки в задаче многоклассовой классификации важно, чтобы каждый класс был представлен равно как в обучающей, так и в тестовой выборке, иначе классификатор может иметь недостаточно данных для обучения либо для проверки. Для равномерного распределения классов среди обучающей и тестовой выборок используется алгоритм стратифицированного разделения.
Таким образом, исходное множество X делится на N подмножеств 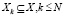 , где N – количество классов, в соответствии с принадлежностью к классу k. После этого из каждого подмножества случайным образом выбирается
, где N – количество классов, в соответствии с принадлежностью к классу k. После этого из каждого подмножества случайным образом выбирается 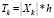 элементов, где h – коэффициент разделения, для тестовой выборки –
элементов, где h – коэффициент разделения, для тестовой выборки – 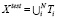 , а из оставшихся элементов формируется обучающая выборка –
, а из оставшихся элементов формируется обучающая выборка – 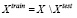 .
.
Для решения поставленной задачи используется архитектура многослойного перцептрона, со следующими слоями (рис. 2).
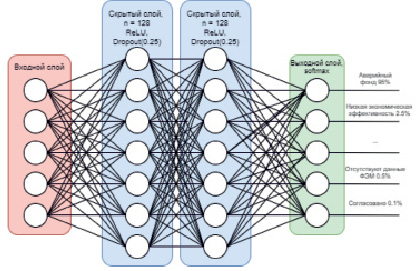
Рис. 2. Архитектура нейронной сети
- Входной слой, 36 элементов.
- Скрытый слой, 128 элементов.
- Скрытый слой, 128 элементов.
- Выходной слой, 11 элементов.
В скрытых слоях используется функция активации линейного выпрямителя (ReLU) – 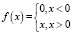 . Для выходного слоя используется функция активации Softmax –
. Для выходного слоя используется функция активации Softmax – 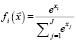 . Областью определения функции Softmax является (0,1), и её результат можно интерпретировать как вероятность попадания в заданный класс.
. Областью определения функции Softmax является (0,1), и её результат можно интерпретировать как вероятность попадания в заданный класс.
Для того чтобы предотвратить переобучение нейронной сети, используется метод регуляризации Dropout, суть которого заключается в отключении определённого количества случайных нейронов слоя на каждом шаге обучения. В данном случае метод Dropout применяется к скрытым слоям нейронной сети.
Для реализации заданной модели использовался язык программирования Python, а также пакет keras для реализации нейросетевой модели и пакет sklearn для обработки исходных данных и валидации результатов. API-служба реализована на языке Python с помощью фреймворка Flask.
Оценка результатов
Для проведения эксперимента был выбран метод скользящего контроля со случайными разбиениями. В данном методе исходная выборка XL делится N различными способами на две непересекающиеся выборки 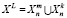 , где
, где 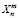 – обучающая выборка, а
– обучающая выборка, а 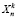 – тестовая выборка. Алгоритм классификации обозначим
– тестовая выборка. Алгоритм классификации обозначим 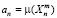 , значение оценки качества
, значение оценки качества 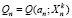 . После вычисления среднего арифметического значения оценок по всем выборкам получим оценку скользящего контроля:
. После вычисления среднего арифметического значения оценок по всем выборкам получим оценку скользящего контроля: 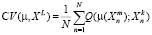 . В данном эксперименте исходная выборка делится на 10 различных случайных разбиений на обучающую и тестовую выборку.
. В данном эксперименте исходная выборка делится на 10 различных случайных разбиений на обучающую и тестовую выборку.
При оценке точности классификатора в задачах многоклассовой классификации принято использовать метрики Accuracy, Precision и Recall. Для оценки точности классификатора можно представить многоклассовый классификатор как множество бинарных классификаторов для каждого класса. Таким образом, введем понятия для результатов классификации: истинно положительный результат, ложно положительный результат, истинно отрицательный результат, ложно отрицательный результат. В задачах оценки классификатора такие результаты называются True Positive (TP), False Positive (FP), True Negative (TN), False Negative (FN). Метрика  показывает долю верно предсказанных результатов, метрику
показывает долю верно предсказанных результатов, метрику 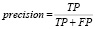 можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными, а метрика
можно интерпретировать как долю объектов, названных классификатором положительными и при этом действительно являющимися положительными, а метрика 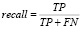 показывает, какую долю объектов положительного класса из всех экземпляров положительного класса определил классификатор. На следующей диаграмме показаны усреднённые по всем разбиениям оценки accuracy, precision, recall для геолого-технического мероприятия «Вывод из бездействия».
показывает, какую долю объектов положительного класса из всех экземпляров положительного класса определил классификатор. На следующей диаграмме показаны усреднённые по всем разбиениям оценки accuracy, precision, recall для геолого-технического мероприятия «Вывод из бездействия».
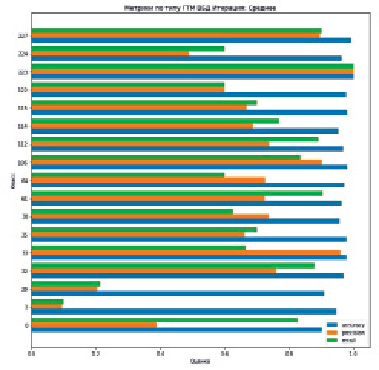
Рис. 3. Результаты оценки классификатора
Усреднив оценки по всем классам, получим итоговую оценку классификации по геолого-техническому мероприятию «Вывод из бездействия» accuracy = 96 %, precision = 67 %, recall = 72 %.
Для большинства результирующих признаков точность классификации является довольно высокой. Самая низкая точность классификации получилась для класса 1 (Стоит бригада), accuracy = 0.94, precision = 0.10, recall = 0.11. Для повышения точности классификации по этой причине отклонения необходима информация о бригадах, которой в данном исследовании не было в исходной выборке.
Заключение
Процесс согласования и отклонения скважин-кандидатов на геолого-технические мероприятия является трудоёмким и ресурсозатратным, автоматизация некоторых аспектов данного процесса может повысить его эффективность и надёжность.
В ходе исследования реализовано программное решение для классификации скважин-кандидатов на геолого-техническое мероприятие «Вывод из бездействия» по причинам отклонения с помощью нейросетевого классификатора. Результаты эксперимента показали, что нейронная сеть с заданными параметрами решает задачу классификации скважин с точностью, достаточной для отображения оператору в качестве предложения для принятия решения. Увеличение количества входных параметров о скважине, таких как информация о предыдущих мероприятиях, информация о мероприятиях на данном пласте, может существенно увеличить точность классификатора.
Библиографическая ссылка
Хакимов Р.Ф. К ВОПРОСУ О РАЗРАБОТКЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ДЛЯ КЛАССИФИКАЦИИ СКВАЖИН-КАНДИДАТОВ НА ГЕОЛОГО-ТЕХНИЧЕСКИЕ МЕРОПРИЯТИЯ ПО ПРИЧИНАМ ОТКЛОНЕНИЯ // Современные наукоемкие технологии. 2021. № 6-1. С. 96-101;URL: https://top-technologies.ru/ru/article/view?id=38704 (дата обращения: 10.07.2026).
DOI: https://doi.org/10.17513/snt.38704