



Большие объемы слабоструктурированных данных, возможность использования результатов анализа таких данных для принятия решений потребовали как разработки теоретических основ для проведения анализа, так и их программных реализаций. В частности, как отмечают авторы [1], такие решения основаны на современной инфраструктуре анализа текстов, как то: множество приемов, методов, инструментов для работы со строками; лексические ресурсы; компьютерная лингвистика; алгоритмы машинного обучения и пр. При использовании для анализа данных машинного обучения решения часто реализованы на языке Python, который имеет множество научных и вычислительных библиотек.
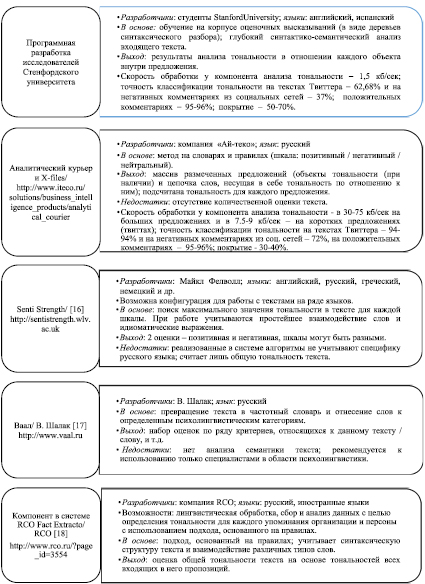
Рис. 1. Известные системы в области анализа тональности в текстах на ЕЯ
Несмотря на то что на данный момент имеются теоретическая база анализа текстов [2–4], в частности модели и методы [5–7], особенности решаемых задач [8–10], специфика данных [11, 12], вопросы автоматизации [13, 14] и ряд программных решений [15–17], позволяющих обрабатывать и анализировать тексты на естественном языке (ЕЯ), совершенствование теоретических основ, специфика ЕЯ (например, башкирского, когда приходится ограничивать применение методов предобработки из-за особенностей словообразования) и решаемых задач требует разработки нового подхода и, как следствие, программной реализации.
В статье представлены современное состояние проблемы построения классификаторов для анализа текста на ЕЯ, в частности для задачи анализа тональности новостных текстов, и готовые программные решения в этой области, обоснована необходимость новой программной реализации ввиду сложности адаптации готовых решений для анализа тональности новостных текстов на башкирском языке. Приводятся формальные требования к программно-аналитическому комплексу и описывается его структурная схема.
Современное состояние проблемы построения классификаторов для анализа текстов на естественном языке
Развитие фундаментальных положений и информационных технологий в области анализа текста привело к тому, что на рынке появилось множество сервисов, позволяющих обрабатывать и анализировать тексты на ЕЯ. Среди широко известных программных решений для задач автоматического определения тональности текста следует выделить Sentiment140, Библиотека NLTK, Senti Strength [16], RCO FactExtractor [18], «Аналитический курьер» и «X-files» и др. (рис. 1). При проведении сравнительного анализа для каждого программного решения отмечены такие аспекты, как: разработчики; языки, на которых может быть представлен текст для анализа; аппарат, положенный в основу решения; чем представлен выход, а также ряд других особенностей. Кроме указанных программных решений, можно отметить такие инструментальные средства, как текстовый процессор КроЛАН (ООО «ЛАН-ПРОЕКТ»), Quiddi Semantics (ООО «ТомскСофт»), 3i NLP Platform (ООО «ДСС Лаб») и др. (рис. 2).
Также следует выделить программу на основе наивного Байесовского классификатора и нечеткой логики «Гибридный классификатор текстовых документов на естественном языке» (ДГТУ), которая позволяет задать произвольное число категорий для классификации. Особенности языка не всегда позволяют использовать те или иные методы анализа, заложенные в имеющихся программных решениях. Часто информация о методах, положенных в основу программной реализации, отсутствует.
Результаты анализа программных решений для классификации текстов, несмотря на то, что используемые в них словари могут быть созданы на различных языках, продемонстрировали отсутствие возможности их применения для текстов на башкирском языке. Это обусловлено тем, что для решения задачи анализа тональности текстов на башкирском языке недостаточно только составления словаря. Специфика языка не позволяет использовать некоторые методы, заложенные в готовых программных решениях [19]. Поэтому необходима разработка программного решения для построения классификатора текстов на башкирском языке.
Цель исследования обусловлена потребностью решения широкого круга задач и принятия решений на основе анализа тональности текстов. К таким задачам могут быть отнесены, например, оценка уровня лояльности потребителя к товару или услуге, определение взглядов на то или иное событие, оценка новостных текстов с последующей оценкой общественного мнения и пр. В связи с тем, что объемы слабоструктурированных данных, на которых и проводится анализ, постоянно возрастают, необходимо также и повышение эффективности анализа данных.
Целью исследования является построение эффективного классификатора в виде программно-аналитического комплекса. В статье эффективность может быть получена и за счет автоматизации анализа, и за счет того, что построение классификатора осуществляется на основе метода, дающего «лучшее» решение. Выбор метода авторами был осуществлен ранее [19].
Постановка задачи и формализация требований к программному решению
Постановка задачи анализа тональности новостных текстов на башкирском языке предполагает, что можно выделить две категории классов – «положительные» / «отрицательные» (рис. 3). В основе решения задачи лежит гибридный подход, который включает методы, основанные на словарях, и методы, основанные на машинном обучении. Структура решения задачи анализа тональности текстов на башкирском языке (рис. 4) включает следующие этапы: предварительная обработка текста (приведение к нижнему регистру; удаление символов, не являющихся буквами; удаление стоп-слов), векторное представление слов (метод представления текста в векторном виде Bag-of-words и статистический показатель TF-IDF), классификация (положительная, отрицательная тональность; метод опорных векторов со стохастическим градиентным спуском).
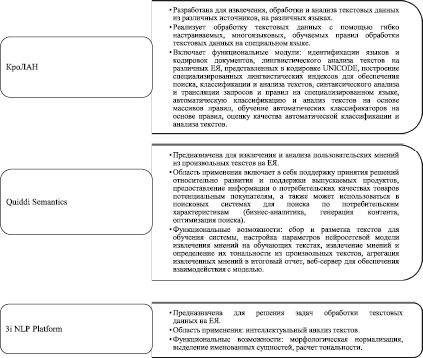
Рис. 2. Программные решения в области анализа тональности текста
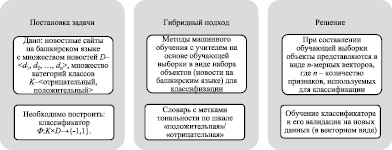
Рис. 3. Краткое представление функционала
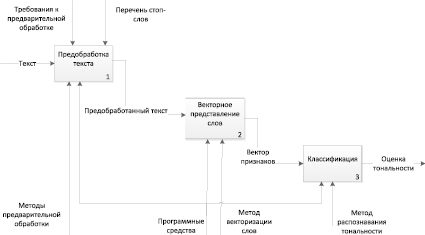
Рис. 4. Структура решения задачи анализа тональности текстов на башкирском языке
По результатам проведенного эксперимента для построения классификатора как наиболее точный был отобран метод опорных векторов со стохастическим градиентным спуском. В его основе лежит построение гиперплоскости для оптимального разделения объектов обучающей выборки 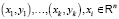 на два класса: yi∈{–1, 1}. Классифицирующая функция: F(x) = sign(<w, x> + b), где <w, x> – скалярное произведение, w – нормальный вектор к разделяющей плоскости, b – вспомогательный параметр. Один класс – объекты со значением функции F(x) = 1, другой класс – объекты с F(x) = –1. Любая гиперплоскость задается в виде <w, x> + b = 0 для некоторых w и b, выбираемых для максимизации расстояния от гиперплоскости до объектов каждого класса
на два класса: yi∈{–1, 1}. Классифицирующая функция: F(x) = sign(<w, x> + b), где <w, x> – скалярное произведение, w – нормальный вектор к разделяющей плоскости, b – вспомогательный параметр. Один класс – объекты со значением функции F(x) = 1, другой класс – объекты с F(x) = –1. Любая гиперплоскость задается в виде <w, x> + b = 0 для некоторых w и b, выбираемых для максимизации расстояния от гиперплоскости до объектов каждого класса 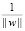 . Учитывая, что проблемы нахождения max
. Учитывая, что проблемы нахождения max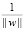 и нахождения min
и нахождения min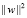 аналогичны, можно записать задачу оптимизации:
аналогичны, можно записать задачу оптимизации: 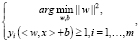 и ее решение с помощью множителей Лагранжа [19].
и ее решение с помощью множителей Лагранжа [19].
Таким образом, в основу создаваемого программно-аналитического комплекса легли предлагаемая теоретическая база для предварительной обработки текста и отобранный по результатам проведенного эксперимента метод опорных векторов со стохастическим градиентным спуском [19].
После определения того, что должно быть на входе и выходе системы, ее функций и атрибутов формулируются требования. Комплекс требований к программно-аналитическому комплексу включает: функциональные, нефункциональные, системные требования (рис. 5). Функциональные требования представлены UML-диаграммой вариантов использования: ввод текста, просмотр результата, определение тональности текста (предварительная обработка текста, векторное представление текста, анализ тональности), вывод результатов анализа (рис. 6). Диаграмма последовательностей демонстрирует взаимодействие объектов (компонентов программно-аналитического комплекса и пользователя) в динамике (рис. 7). Диаграмма размещения представляет общую конфигурацию и топологию распределенного программно-аналитического комплекса и содержит распределение компонентов по отдельным узлам системы.
Архитектура приложения представляет собой классическую архитектуру – «клиент – сервер».
К системным требованиям данного программно-аналитического комплекса относятся характеристики сервера и клиента, возможность переносимости комплекса и пр. (рис. 8).
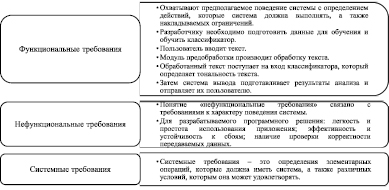
Рис. 5. Требования к программно-аналитическому комплексу
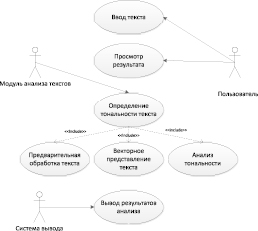
Рис. 6. Диаграмма вариантов использования
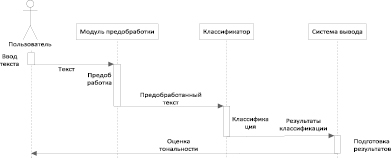
Рис. 7. Диаграмма последовательностей

Рис. 8. Детализация системных требований
Язык Python обеспечивает довольно короткие сроки написания программ, также используется большое количество библиотек, таких как Scikit-Learn, NLTK, Gensim, spaCy, NetworkX и Yellowbrick, реализующих методы машинного обучения.
Структурная схема программно-аналитического комплекса
Структурная схема программно-аналитического комплекса включает такие базовые модули, как: модуль web-приложения и модуль анализа тональности, а также несколько вспомогательных (рис. 9). Согласно функционалу, в структурной схеме некоторые вспомогательные модули вошли в состав базовых.
Модуль web-приложения позволяет: задавать конфигурацию приложения, импортировать пакеты, отслеживать обращения по адресам / и /index, реагировать на отправку формы ввода текста для анализа вызовом метода predict модуля анализа, обеспечивать безопасность клиентских сессий, для генерации формы ввода текста для анализа использовать класс AnalyzeForm; содержит папки с перечнем html-страницы для web-приложения, базовой страницей и страницей, ее расширяющей, формой для ввода текста и графические элементы, папки со статическими объектами, файлы со списком необходимых библиотек для работы приложения с указанием версий для каждой библиотеки.
Модуль анализа тональности: позволяет получить по обученной модели оценку тональности, очистить текст. В данный модуль включен блок обучения модели (программно реализован как вспомогательный). Вспомогательные модули реализуют следующий функционал: реализация методов парсинга, методов для автоматической разметки текстов, загрузки словаря тональности, методов предварительной обработки текста, метод для удаления стоп-слов.
Выводы
Результаты анализа современного состояния проблемы построения классификаторов для анализа текста на ЕЯ показали как наличие теоретической базы для разработки инструментальных средств для анализа, так и широкий спектр готовых программных решений: от «универсальных» до специальных, созданных под конкретную задачу.
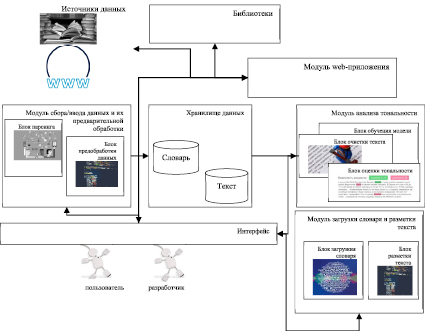
Рис. 9. Структурная схема программно-аналитического комплекса
Специфика словообразования в башкирском языке и отсутствие готовых корпусов текстов обусловили необходимость разработки программно-аналитического комплекса для анализа тональности новостных текстов, представленных на башкирском языке. Программная реализация основана на ранее описанном гибридном подходе [19]. Формальные требования к программно-аналитическому комплексу включают функциональные, нефункциональные и системные требования. Использование языка Python дало возможность написать программу в довольно короткие сроки.
Результаты исследований, приведенные в статье, получены в рамках выполнения грантов РФФИ 18-07-00193, 19-07-00709 и государственного задания № FEUE-2020-0007.
Библиографическая ссылка
Сметанина О.Н., Сазонова Е.Ю., Сулейманов А.К., Селиванов С.Г., Андрушко Д.Ю., Габдиев Ф.Ф. ПРОГРАММНОЕ РЕШЕНИЕ ПО ПОСТРОЕНИЮ КЛАССИФИКАТОРОВ ДЛЯ АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ // Современные наукоемкие технологии. 2020. № 12-1. С. 119-127;URL: https://top-technologies.ru/ru/article/view?id=38420 (дата обращения: 13.07.2026).
DOI: https://doi.org/10.17513/snt.38420