



Попытки создания устройства, определяющего типы печатных символов, предпринимались в разное время. Распознающее устройство может использоваться для ускоренной обработки печатной информации, для поиска нужной литературы, для анализа печатных текстов и т.д. Устройство должно выполнять две функции: первая функция – восприятие печатных символов с носителя текстов, вторая – определение типов печатных символов.
Реализация первой функции читающего устройства особых затруднений не вызывает.
При реализации второй функции главной проблемой является то, что устройство должно распознавать типы печатных символов не одного, а различных шрифтов, то есть оно должно определять один и тот же печатный символ (букву или цифру), но напечатанный с разным масштабом (высотой и шириной), с разным наклоном частей символа, с более жирными или более узкими частями символа, с возможными дефектами изображения символа и т.д.
До настоящего времени решение задачи определения типов символов печатных текстов, когда символы различных шрифтов значительно отличаются по своей форме и способу написания, до конца не завершено. Цель проведенных исследований заключается в создании устройства, которое позволило бы с высокой надежностью определять типы печатных букв и цифр с перечисленными выше особенностями формы символов.
В ходе анализа литературных источников установлено существование шести способов определения типов символов печатных текстов. Первый способ основан на определении типов печатных символов с использованием трафаретов. Было предложено устройство [1, 2], в котором изображение печатной цифры проектировалось на диск, содержащий вырезанные трафареты цифр, за которым был расположен фотоэлемент. При полном затемнении фотоэлемента переключалось реле и определялся тип цифры.
При использовании второго способа символы определялись с помощью специальных отметок или стилизованной формы. Типы цифр устанавливались созданной машиной [3–5], при этом цифры изображались в виде вертикальных полосок. Для реализации третьего способа авторы исследований [6–8] выделяли следующие особенности элементов формы символов: количество прямых и кривых частей, расположение этих частей друг относительно друга и т.д. (рис. 1, а). Кроме того, для определения печатных символов подсчитывалось количество пересечений изображения символа линиями, идущими по горизонтали, расположенными на разной высоте, определялось число концевых точек изображения и т.д.
Четвертый способ определения типов печатных символов основан на использовании наличия или отсутствия черного поля изображения символа в данном фиксированном месте. Созданная машина [4, 9, 10] определяет типы цифр при делении изображения печатной цифры на пять частей и фиксации наличия или отсутствия в частях черного поля.
Для реализации пятого способа автор работы [5, 11, 12] использовал интегральные характеристики формы печатных символов. Так, в разработанном устройстве для определения типов печатных символов использовались проекции площади изображения печатного символа на горизонтальную (рис. 1, б) и вертикальную оси.
Наконец, типы печатных символов определялись с помощью обучающихся электронно-вычислительных машин (ЭВМ) [6]. При этом изображения печатных символов заносились в запоминающее устройство ЭВМ с помощью рядов фотоэлементов. Алгоритм обучения ЭВМ состоял из следующих частей:
1. Проведение плоскостей, разделяющих один тип символа относительно другого типа
для предъявленных машине символов (рис. 2, а, б, в).
2. Выбрасывание лишних плоскостей (рис. 2, г).
3. Выбрасывание лишних кусков плоскостей (рис. 2, г).
4. Определение типов новых символов.
Все перечисленные выше способы определения типов печатных символов в настоящее время не используются, так как позволяют определять лишь ограниченное число типов символов, в лучшем случае в пределах одного шрифта.
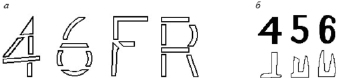
Рис. 1. Вид элементов фигуры, используемых для различения символов по элементам формы: а – третий способ определения типов символов печатных текстов; б – пятый способ определения типов символов печатных текстов на основе закона изменения проекции площади фигуры символа при проектировании ее на горизонтальную ось
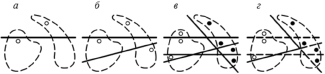
Рис. 2. Пояснения алгоритма обучения ЭВМ
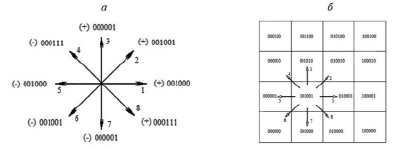
Рис. 3. Выбор направлений для определения типов печатных символов: а – найденная схема направлений с числами для перехода на сопредельные ячейки; б – передвижение по любому из восьми направлений из заполненной ячейки на соседние
Материалы и методы исследования
Разработанное устройство состоит из компьютера, воспринимающей, распознающей и запоминающей частей (ВРЗЧ). Совокупность электрических импульсов, снимающих образ с печатного носителя, поступает в установленном порядке в прямоугольную матрицу считывающего устройства. Матрица разбита на кодированные ячейки и каждому образу соответствует определенная совокупность ячеек в матричной оболочке [13].
После анализа были определены необходимые и достаточные признаки для определения типов печатных символов [14]. Ими оказались направления (1–8), входящие в выбранную комбинацию направлений (рис. 3, а). Направления комбинации образуются элементами контуров печатных символов. По разработанной для компьютера программе изображение символа, находящееся в матрице компьютера, начиная с концевой точки, обходится по контуру символа в соответствии с выбранной комбинацией направлений. С целью определения основного направления соседние заполненные ячейки матрицы опрашиваются по выбранным направлениям комбинации, начиная с заполненной концевой ячейки изображения символа. Главное направление устанавливалось числом заполненных ячеек-звеньев (то есть вес), превышающим число ячеек, определяющих наибольшую толщину отдельных частей напечатанного знака. Согласно заданному алгоритму программы, происходит переход с помощью чисел (рис. 3, а) на соседнюю заполненную ячейку в найденном основном направлении, определяя параметр (номер) основного направления и т.д. В дальнейшем процесс повторялся.
В итоге образуется код печатного символа, состоящий главным образом из последовательности номеров основных направлений. Таким образом, код символа создавался при обходе по главным направлениям фигуры символа. Переход от одной заполненной ячейки на другую соседнюю осуществлялся следующим образом. Пусть заполненная концевая ячейка изображения символа (или другая заполненная ячейка) имеет адрес 001001 (рис. 2, б).
Переход от данной ячейки на соседнюю, например, в направлении 1 совершается за счет добавления к адресу ячейки 001001 числа 001000 (рис. 2, б). Образуется число 010001, то есть определяется адрес соседней заполненной ячейки матрицы в направлении 1, на которую и происходит переход. Таким образом, код символа формируется из номеров основных направлений и определенных неосновных.
В дальнейшем производилось сравнение сокращенного (упрощенного) кода символа с эталонными кодами. Эталонный код, то есть ряд направлений, создаваемый путем обхода по направлениям элементов образцового очертания знака, был создан для каждого типа печатного символа. В процессе сравнения определялось количество неидентичных номеров для каждого эталонного кода. Тип печатного символа определялся по минимальному количеству несовпадений номеров [13–15].
Для обеспечения высокой надежности распознавания (определения) типов печатных знаков (символов) были приняты следующие меры.
1. Для составления кода печатного знака использовались необходимые и достаточные признаки (определенные направления, образуемые частями изображения печатного символа), позволяющие с высокой надежностью устанавливать типы и виды печатных символов разных шрифтов.
2. В процессе определения типа печатного символа по разработанному алгоритму производилось так называемое стирание по толщине, то есть приведение толщины отдельных частей знака к наименьшей в одну элементарную ячейку матрицы, и таким образом символы с разной толщиной частей (в определенных пределах) определялись в равной степени.
3. Образы печатных символов с помощью воспринимающей системы разработанного устройства заносились в определенную матрицу – звено ВРЗЧ устройства персонального компьютера, включающую 32×32 ячеек и обеспечивающую распознавание всех типов печатных символов разных шрифтов, кроме букв «ш» и «щ».
4. Полученный после окантовки изображения символа его код упрощался, то есть происходила ликвидация неосновных направлений, возникающих из-за изменения ориентации символа в целом или его отдельных частей из-за возможных дефектов, из-за наличия декоративных украшений в символах, из-за определенных шрифтов и т.д.
5. Эталонные коды составлялись с учетом характерных признаков печатных символов разных шрифтов. В эти признаки входили главным образом основные направления, а также определенные суммы, возникающие при переходе во время окантовки изображения символа от его одной части к другой.
6. Определение типов печатных знаков происходило путем сравнения номеров направлений упрощенного кода символа с номерами направлений всех эталонных кодов.
Совпавшие номера ликвидировались, а несовпавшие номера в эталонном коде и в упрощенном коде символа суммировались для каждого эталонного кода, и по наименьшему количеству несовпавших номеров направлений определялся тип и вид печатного образа. Для оценки достоверности установления печатных букв рекомендуется зависимость, учитывающая возможность появления в печатных текстах букв Pi:
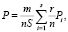
где m – число правильно прочтенных букв; S – число предназначенных для опознавания букв алфавита; n – количество проверок каждой буквы; r – число безошибочно опознаваемых букв для одного смыслового символа (то есть для одного типа буквы).
Все печатные буквы алфавита точно распознавались разработанным устройством друг относительно друга, за исключением букв «ш» и «щ», максимальная надежность идентификации которых Pmax составила 0,98.
Результаты исследования и их обсуждение
В процессе экспериментальных исследований анализировались два компьютерных шрифта. У одного из них печатные символы имели дополнительные украшения формы, а символы другого шрифта их не имели. Была выбрана комбинация направлений (рис. 3, а), отражающая существенные и необходимые признаки печатных символов, которые выявлялись после окантовки формы символа и по которым определялись типы символов.
По результатам исследований определено количество ячеек-звеньев прямоугольной матрицы ВРЗЧ устройства компьютера с учетом размеров заглавных символов и возможных смещений по вертикали и горизонтали изображений символов (32×32 ячеек-звеньев).
Разработаны следующие правила для стирания содержимого ячеек, формирующих лишнюю толщину элементов изображения символа:
- при обходе по направлениям «2», «4», «6», «8» содержимое заполненных ячеек по направлениям «1» и «5» ликвидируется, что устраняет лишнюю толщину наклонных линий символа;
- при окантовке по направлениям «3» и «7» происходит исчезновение содержимого ячеек по направлениям «1» и «5», что удаляет лишнюю толщину вертикальных линий символа;
- при окантовке по направлениям «1» и «5» содержимое ячеек по направлениям «3» и «7» исчезает, что устраняет лишнюю толщину горизонтальных линий символа.
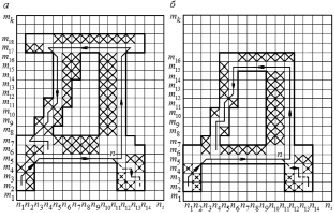
На рис. 4 представлена окантовка по направлениям букв «Д» различных шрифтов, включая перекрестие; изображены ячейки матрицы, составляющие лишнюю толщину частей знака, содержимое которых ликвидируется при обходе знака по контуру.
Было отмечено, что при обходе контура знака в качестве главного направления избиралось то направление, которое имело количество ячеек-звеньев большее или равное «весу». Вес (количество ячеек) хотя бы на одну ячейку должен быть больше количества ячеек, образующих толщину частей символа. После завершения окантовки контура символа кодовая запись знака, представляющая собой определенную комбинацию номеров направлений, преобразуется для того, чтобы исключить присутствие таких дефектов, как каверны в изображении символа, размывы, несвойственные отклонения вертикальных, горизонтальных, наклонных линий знака.
С целью устранения вышеперечисленных дефектов разработан следующий алгоритм оптимизации. Из кода символа исключаются номера неосновного направления в том случае, если при окантовке до и после них располагаются номера определенного основного направления или определенной суммы.
На рис. 5, I, представлена окантовка по направлениям отклоненных линий знака: горизонтальной (а), наклонной (б), вертикальной (в). В результате окантовки отклоненной горизонтальной линии (рис. 5, I, а) шифр линии представляет собой комбинацию номеров 118181118111 (вес равен 4, что соответствует трем номерам основного направления). После выполнения упрощения код линии выглядит как 111111111, что соответствует идеальной горизонтальной линии.
После окантовки отклоненной наклонной линии (рис. 5, I, б) код линии представляет собой комбинацию номеров 221222121222, а после операции упрощения – 222222222, что равнозначно идеальной наклонной линии. И в результате окантовки отклоненной вертикальной линии (рис. 5, I, в) код линии представляет собой ряд номеров 332332333233, а после операции упрощения – 333333333, что соответствует оптимальной вертикальной линии.
 – ячейки толщины, содержимое которых уничтожается при окантовке очертания
– ячейки толщины, содержимое которых уничтожается при окантовке очертания
Рис. 4. Окантовка по направлениям букв «Д» различных шрифтов
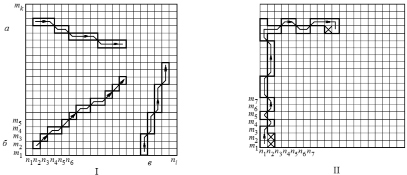
Рис. 5. Виды окантовки символов: I – окантовка по направлениям отклоненных линий знака; II – окантовка по направлениям буквы «Г» с размывами линий
Из-за низкокачественной печати либо непропечатки различных частей печатного символа, могут оказаться размытыми изображения или появиться такие дефекты, как каверны. Следовательно, необходимо рассмотреть возможность устранения таких дефектов. На рис. 5, II, представлено изображение буквы «Г» с размывами. В результате окантовки буквы «Г» формируется следующий код буквы: 332423433233334311218121117. После проведения упрощения код буквы представляет собой комбинацию номеров: 333333333311111117. Преобразованный код после сравнения со своим стандартным видом «31» не дает расхождений. (При вычислении числа несовпадений, направление 7 в расчет не принимается, так как количество его номеров меньше веса.) Поэтому рассматриваемые размывы линий знака не влияют на его опознавание.
Заключение
Для надежного определения разработанным устройством типов печатных символов выбраны существенные и достаточные признаки, определено оптимальное количество ячеек-звеньев матрицы ВРЗЧ устройства компьютера.
Для дальнейшего повышения надежности предусмотрены и реализованы меры, позволяющие распознавать типы печатных знаков, вне зависимости от вида шрифта, изменения в определенных пределах размеров символов и ориентации символа в целом или его отдельных частей, от наличия декорирования и определенных дефектов.
Таким образом, разработано новое устройство, которое с высокой надежностью и большим быстродействием решает проблему функции распознавания типов печатных символов. Разработанное устройство позволяет автоматизировать процесс обработки печатной информации.
Библиографическая ссылка
Пинт Э.М., Петровнина И.Н., Романенко И.И., Еличев К.А. ПОВЫШЕНИЕ НАДЕЖНОСТИ СПОСОБА ОПРЕДЕЛЕНИЯ ТИПОВ ПЕЧАТНЫХ СИМВОЛОВ РАЗНЫХ ШРИФТОВ // Современные наукоемкие технологии. 2020. № 5. С. 85-90;URL: https://top-technologies.ru/ru/article/view?id=38036 (дата обращения: 03.07.2026).
DOI: https://doi.org/10.17513/snt.38036