



Необходимость управления распределенными данными возникает как в области баз данных, так и в области грид- коммуникаций. Существующий инструментарий в области баз данных и грид-коммуникаций может быть эффективно применен к построению и управлению Data Grid. В статье анализируются отдельные особенности Grid-вычислений, унаследованные от высокопроизводительных и кластерных вычислений, когда несколько процессоров или рабочих станций соединены высокоскоростным соединением для совместного выполнения одной программы. Под распределенной базой данных (DDB) будем далее понимать набор из нескольких логически взаимосвязанных баз данных или частей одной базы данных, хранимых на различных ресурсах в компьютерной сети [1, 2]. Под системой управления распределенной базой данных (DDBMS) будем понимать программное обеспечение по управлению DDB и обеспечению прозрачного для пользователей механизма доступа к данным. Будем полагать, что данные распределены среди ресурсов компьютерной сети, которая имеет собственный сервер и хранилище данных. Все эти распределенные данные считаются единой логической базой данных, т.е. для механизма осуществления сетевых запросов к базе данных не важно, где конкретно в сети расположены данные [3].
Предлагается новый подход к операциям в распределенных системах БД, связанных с репликацией данных, который основан на использовании инструментария GRID. Он основан на некоторых эффективных инструментах Data Grid для управления распределенными объектно-ориентированными базами данных. Таким образом, получен принципиально новый инструментарий для проектирования, разработки архитектуры, повышения производительности и параллельному управлению распределенными системами баз данных (DDBS). Непосредственные результаты исследований позволяют эффективно оптимизировать запросы, распределения по узлам, и, главное, оптимизировать фрагментацию и консолидацию в Интернете.
Анализ процессов обработки данных в распределенной системе
С целью анализа возможностей повышения производительности и расширения диапазона применения научных методов и алгоритмов параллельной и распределенной обработки данных были проведены тесты распределенной системы в ресурсном центре Санкт-Петербургского государственного университета. Там же были проведены исследования по созданию операционной среды для базы данных и функционала по консолидации данных в распределенных средах. Разрабатываемая сеть может быть использована в других научно-исследовательских институтах, а также коммерческих предприятиях, для которых существует потребность или факт распределения ресурсов в локальной или глобальной сетях, удаленно друг от друга [4]. Разрабатываемая сеть может найти применение при решении некоторых задач построения архитектуры прототипированной системы для разработки алгоритмов и адаптации существующих программных продуктов. Такая система может быть представлена в виде блоков, которые объединены в распределенную виртуальную компьютерную систему под названием виртуальный полигон (TESTBED) [5].
Основой построения системы управления распределенной базы данных в нашем случае будет служить стандартная Грид- архитектура работы с распределенными приложениями. Технологии Грид включают в себя универсальные аспекты, одинаковые для любой системы (архитектура, протоколы, интерфейсы, сервисы). Используя эти технологии и наполняя их конкретным содержанием, можно реализовать ту или иную грид-инфраструктуру, предназначенную для решения того или иного класса прикладных задач. Грид-технологии не являются технологиями параллельных вычислений, задачей технологий Грид является координация использования ресурсов. Описание различных уровней архитектуры GRID можно представить в виде иерархической структуры, которая показана на рис. 1, состоящей из нескольких уровней. На каждом из представленных уровней существуют свои сервисы, взаимодействующие посредством определенных протоколов.
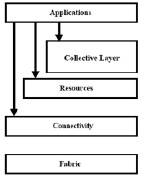
Рис. 1. GRID архитектура протокола
Уровень Fabric предоставляет ресурсы, совместный доступ к которым обеспечивается через протоколы GRID. Уровень connectivity определяет базовые коммуникационные и идентификационные протоколы, позволяющие осуществлять обмен данными между ресурсами уровня Fabric. Уровень Resource базируется на коммуникационном и авторизационном протоколах уровня Connectivity. На уровне Collective сгруппированы протоколы и сервисы, которые не связаны с каким-либо конкретным ресурсом, а являются более глобальными по природе и обеспечивают коллективное взаимодействие ресурсов. Уровень Application включает в себя приложение пользователя, функционирующее в среде GRID [6]. В нашем случае это DBMS.
Фундаментальная основа архитектуры проекта
Цели архитектуры позволяют не перечислять полный набор требуемых протоколов, а лишь сформулировать общие требования к основным уровням модели. Ее структура и соотношение с многоуровневой архитектурой интернет-протоколов приведена на рис. 2. Основой модели являются протоколы Middleware и Virtualization, на которые возложены функции обеспечения разделения индивидуальных ресурсов. Dataserver отвечает за координацию использования имеющихся ресурсов, доступ к ним осуществляется с помощью Clientserver and Gridserver [7].
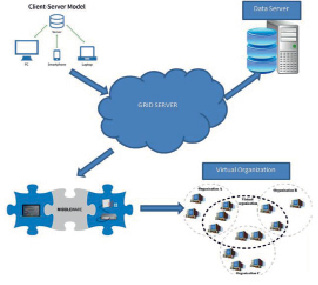
Рис. 2. Архитектура полигона в СпбГУ
Здесь важно подчеркнуть различие между параллельными и распределенными архитектурами баз данных. В промышленности сегодня преобладают различные реализации распределенных архитектур, которые постоянно развиваются для информационных систем крупных предприятий.
Параллельная архитектура чаще встречается в научных высокопроизводительных вычислениях, где требуется, чтобы многопроцессорные архитектуры справлялись с объемом данных, обрабатываемых транзакциями и приложениями для складирования. Поэтому мы вводим общую архитектуру распределенной базы данных [8]. Реализация ее осуществлена на основе трехуровневых клиент-серверных и федеративных систем баз данных. Проект по разработке системы выполнен в ресурсном центре Санкт-Петербургского государственного университета [9]. Весь проект можно разделить на 5 следующих блоков: Серверы клиентов, Grid Server, Data Server, Middleware virtual organization (рис. 2).
Серверы клиентов и главные серверы связаны между собой через высокоскоростную компьютерную сеть. Серверная машина запускает одну или несколько серверных программ с высокой производительностью и выделенными ресурсами для клиентов. Клиенты могут также обмениваться любыми данными из своих ресурсов. Кроме этого клиентам необходима связь с серверами, на которые они будут отправлять запросы [10]. Доставка пакета осуществляется в узел назначения с условием сведения к минимуму вероятности того, что пакеты могут прослушиваться по определенному каналу связи. Для этого выбор канала связи осуществляется с помощью процесса рандомизации канала доставки пакетов. В этом процессе предшествующий следующему переходу к ресурсу узел идентифицируется на первом этапе процесса. Этот процесс случайным образом осуществляет выбор очередного соседнего узла и текущий пакет передает на следующий переход.
При выборе следующего перехода отдельное внимание уделяется вопросу избегания передачи двух пакетов последовательных данных через каждый узел. Основной упор сделан на проблему оптимального распределения объектов данных и их разбиения на части с использованием схемы секретного доступа и удаленного кодирования репликаций. Это приводит к решению задачи достижения безопасности и высокой производительности хранилища данных в хранилище Data Grid. За основу топологии сети взята модель одноранговой Data Grid. К данным, которые разделены и распределены между различными узлами Data Grid, применяется операция репликации для минимизации последующих затрат. Проблему распределения данных естественно разделить на две задачи: внутрикластерного и межкластерного распределения, которые решались по отдельности и независимо друг от друга. Data Grid представляет собой распределенную вычислительную систему, построенную на основе глобальной сети, оперирующую большим количеством наборов данных и вычислительных ресурсов как единая система управления виртуальными данными (SVDMS). Data Grid может использовать и координировать данные из различных ресурсов и предоставлять различные сервисы для удовлетворения потребностей высокопроизводительных распределенных вычислений. Репликация данных применятся для повышения производительности процесса доступа к данным и распределения нагрузки в Data Grid [11].
Тестирование распределенной базы данных реального времени на Linux-сервере
С целью проведения эксперимента на сервере ресурсного центра Санкт-Петербургского государственного университета был установлен Hadoop. Для автономной работы Hadoop был использован один сервер, остальные сервера были оставлены под распределенные данных. Мы разделили узлы типа namenode и datanode, создав полностью распределенную конфигурацию Hadoop. Полностью распределенная конфигурация хороша для обработки больших данных.
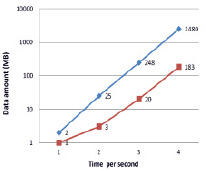
Рис. 3. Результат тестирования производительности Linux сервера в режиме реального времени
Обработка небольших данных с применением полностью распределенной конфигурации нежелательна, поскольку время, затраченное на сбор распределенных данных в отдельных узлах во время выполнения стадии Reduce, сводит на нет преимущества распределения данных для каждого узла на стадии Map reduce. На рис. 3 показаны результаты теста, когда в полностью распределенной конфигурации обработка 10 млн строк данных превзошла результаты тестирования для централизованных конфигураций. Результат теста варьируется в зависимости от объема данных и специ- фикации системы Big data и распределенной системы данных. Эффективность предлагаемого подхода будет только повышаться при увеличении объема данных и степени их пространственного распределения.
Заключение
Таким образом, был реализован подход, в котором объединены схемы разделения данных с динамической репликацией для обеспечения безопасности данных и повышения производительности при обработке данных. Установлено, что для достижения хороших преимуществ в производительности системы при репликации данных должно быть проведено очень корректно разделение данных. Преимуществами нашего проекта являются:
– защищенность данных;
– использование скоординированных данных из различных ресурсов и предоставление различных услуг по организации распределенных и высокоскоростных вычислений;
– более качественное использование данных, сокращение времени ответа клиента и времени на передачу данных путем применения методов репликации.
В предлагаемой системе проводится репликация данных из распределенных баз данных в промежуточное Grid-представление с большим объемом данных в глобальной сети (WAN). Предложены алгоритмы для обработки распределенных данных в Data grid, как в распределенной вычислительной архитектуре, которая объединяет большое количество наборов данных и вычислительных ресурсов в единую систему управления виртуальными данными. С учетом того, что часто данные могут храниться в различных системах управления базами данных, то разумно было попытаться понять ключевые особенности обоих структур: распределенных баз данных и Grid-систем. Объединение этих технологий позволяет строить эффективные системы Data Grid. В будущем мы планируем проанализировать различия в этих технологиях с акцентом на конструктивный выбор или модификацию их для дальнейшего развития систем Data Grid [12].
Библиографическая ссылка
Тхуреин К.Л., Богданов А.В. СИСТЕМА УПРАВЛЕНИЯ РАСПРЕДЕЛЕННЫМИ БАЗАМИ ДАННЫХ НА ОСНОВЕ ИНСТРУМЕНТАРИЯ GRID // Современные наукоемкие технологии. 2019. № 8. С. 84-88;URL: https://top-technologies.ru/ru/article/view?id=37635 (дата обращения: 24.07.2026).