



Ускорение, улучшение качества и повышение точности информационного поиска актуально для существующих и проектируемых информационных систем [1, 2]. В качестве алгоритмической основы улучшения поиска в рассматриваемом аспекте остается не раскрытым потенциал битового (разрядного) распараллеливания операций сравнения элементов строкового типа. С целью раскрытия этого потенциала в статье излагается максимально параллельное по разрядам операндов выполнение арифметического сложения чисел с учетом знака операндов. Способ отличается тем, что после элементарного предварительного преобразования операции вычисления переноса в нем становятся взаимно независимыми, отделяются друг от друга, выполняются синхронно по всем разрядам [3, 4], при этом не используются традиционные логические схемы вычисления переноса. Детально излагается распространение этого способа на случай параллельного по битам сравнения чисел и слов строкового типа. В результате представлены основы максимально параллельного выполнения базовых операций поиска, включая сравнение и сортировку. Предлагаемый способ сравнивается по временной сложности и аппаратным затратам с известными схемами разрядного распараллеливания арифметических операций [5, 6], а также базовых операций в информационных системах, включая операции сравнения, поиска, замены [7–9] с учетом построения структур данных [10, 11]. Как частный случай применения способа дан алгоритм параллельного сложения полноразрядных операндов без вычисления переноса за логарифмическое от числа разрядов время при квадратичном количестве элементов. В [5] декларируется отсутствие прогресса в синтезе сумматоров в течение 40 лет. Ниже исследуется альтернативное построение: в [3, 4] дан алгоритм сложения за время O(1) при абстрактно произвольном количестве разрядов слагаемых.
Преобразование параллельного по разрядам сложения для применения в информационном поиске
Преобразуемый метод сложения и его описание заимствуются из [3, 4]. Сущность метода в том, что после предварительного параллельного по разрядам шага все переносы становятся взаимно отделенными промежуточными нулями. Это дает возможность параллельного по разрядам одновременного преобразования, которое эквивалентно распространению переноса. При наличии параллельных битовых сумматоров время сложения формально имеет единичную оценку независимо от числа разрядов. Если соединить метод с параллельным преобразованием знаков, для этого используется аналог дополнительного кода, то возникает возможность сравнения слов, представленных в двоичном коде, с единичной оценкой времени независимо от длины слова. Для корректного представления преобразований необходимо краткое описание исходного метода. Метод заключается в следующем. Двоичные числа
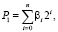
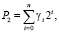 (1)
(1)
где βi, γi – двоичные коэффициенты 0 или 1, располагаются друг под другом согласно весу коэффициентов:
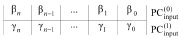 (2)
(2)
Здесь и ниже PC – разрядная сетка. Одновременно, взаимно независимо по индексам (2), выполняется сложение (по вертикали) βj + γj (CBj). Битовая сумма записывается в виде 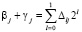 ,
, 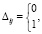
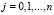 , по диагонали от j-го коэффициента (Дj-запись):
, по диагонали от j-го коэффициента (Дj-запись):
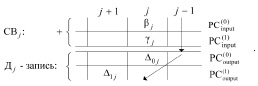 (3)
(3)
В двухрядном коде суммы слагаемых (1),
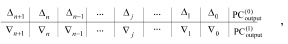 (4)
(4)
все переносы взаимно отделены парами вида 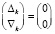 , в Дj-записи по диагонали от 1 из
, в Дj-записи по диагонали от 1 из 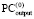 в
в 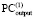 может располагаться только 0 [4]. Оба факта – следствия сложения по вертикали не более двух единиц равного веса. Далее, в (4) каждое Δj ≠ 0 из
может располагаться только 0 [4]. Оба факта – следствия сложения по вертикали не более двух единиц равного веса. Далее, в (4) каждое Δj ≠ 0 из 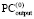 (и только из
(и только из 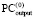 ) представляется в виде тождества
) представляется в виде тождества 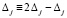 , правая часть которого размещается в порядке Дj-записи
, правая часть которого размещается в порядке Дj-записи
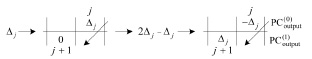 (5)
(5)
при всех возможных j = 0,1,..., n. Корректность преобразования (5) обосновывается отмеченным выше следствием [4]. Параллельное сложение битовых значений равного веса образует в 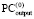 окончательную сумму P1 и P2 в однорядном коде. Примеры выполнения сложения изложенным способом будут даны ниже. Код суммы окажется знакоразрядным (значения разрядов
окончательную сумму P1 и P2 в однорядном коде. Примеры выполнения сложения изложенным способом будут даны ниже. Код суммы окажется знакоразрядным (значения разрядов 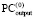 либо 0, либо +1, либо –1). Время сложения T при количестве элементов сумматора R составит
либо 0, либо +1, либо –1). Время сложения T при количестве элементов сумматора R составит
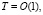
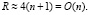 (6)
(6)
Чтобы выполнять необходимое для поиска сравнение данных, следует представить и обосновать выполнение вычитания в границах рассматриваемого способа (перейти от арифметического сложения к алгебраическому – с учетом знака слагаемых). Для этого используется обратный код вычитаемого и восстановление правильного результата по аналогии с дополнительным кодом. Пусть от P1 из (1) вычитается P2. Для этого P2 переводится в обратный код. Это равносильно тому, что вместо P1 – P2 выполняется 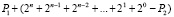 . Чтобы конечный результат был правильным, достаточно из него вычесть дополнительное слагаемое
. Чтобы конечный результат был правильным, достаточно из него вычесть дополнительное слагаемое 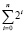 . Поскольку
. Поскольку 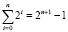 , из полученного результата достаточно вычесть
, из полученного результата достаточно вычесть 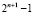 или сложить его с
или сложить его с 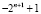 . При этом сложение должно выполняться изложенным согласно (1)–(6) способом. Знак окончательного значения разности дает знак старшего ненулевого разряда. Время выполнения вычитания сохранит оценку (6) с точностью до константы, определяемой двумя дополнительными шагами.
. При этом сложение должно выполняться изложенным согласно (1)–(6) способом. Знак окончательного значения разности дает знак старшего ненулевого разряда. Время выполнения вычитания сохранит оценку (6) с точностью до константы, определяемой двумя дополнительными шагами.
Сравнение элементов (слов) строкового типа
Символы слова представляются в двоичной форме на основе ASCII-кода. В порядке расположения символов в двоичном коде слово интерпретируется как число вида (1). Согласно лексикографическому порядку сравниваемые слова выравниваются по первым слева направо символам. В процессе выравнивания пустые символа меньшего по количеству символов слова заменяются нулями. Остается сравнить два полученных числа изложенным выше способом. Пусть, например, сравниваются слова 'sky' и 'sun'. С выравниванием по первым символам получится:

В данном расположении из верхнего слова вычитается нижнее. Алгебраическая сумма примет вид
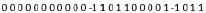
В соответствии знаку старшего ненулевого разряда 'sky' < 'sun'.
В [12] представлены результаты численного моделирования, показывающие, что с помощью изложенного метода могут идентифицироваться строки и текстовые фрагменты произвольного вида. Часть комплекса численного моделирования составляли двоичные полиномы вида (1), при их сравнении и при алгебраическом сложении слова выравниваются по младшему разряду. Численный эксперимент во всех рассмотренных случаях дал положительные результаты. С выравниванием порядков метод переносится на операции с плавающей точкой. Поиск по маске дает совпадение, если сравнение с маской влечет нулевую разность. Таким образом, поиск чисел и слов объединяется в общую алгоритмическую схему. Еще один способ построения единой схемы получается на основе поиска разности abs(ord() – ord()) для строк и abs(x – y) для чисел. В [13] для этой цели используется сортировка слиянием по матрицам сравнений с хранимыми ссылками на элементы входных массивов. Нулевое значение abs(x – y). В этом способе вычисляется приближенно с заданной границей погрешности. Если не учитывать время, требуемое для идентификации знака старшего ненулевого разряда, изложенное сравнение n-разрядных слов имеет временную сложность Tstring com parison (n) ≈ 8 τbinary = O(1), которая формально не зависит от n. Здесь и ниже τbinary – время переключения логического элемента.
Однако идентификация знака сравнения – самостоятельная задача. Ее решение в конечном счете приводит к исключению знаков разрядов на входе и на выходе метода с построением алгоритмической схемы параллельного сумматора.
Алгоритм идентификации знака старшего ненулевого разряда
Знак старшего ненулевого разряда в знакоразрядном двоичном слове можно выделить, в частности, при помощи схем, представленных в [3, 4] и [11]. Ниже для этой цели предлагается алгоритм на основе схемы сдваивания [14]. Сдваивание выполняется для всей последовательности n + 1 разрядов слова и необходимо включает старший разряд:
Операция 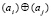 , затем
, затем 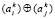 подразумевает выбор и сохранение знака в зависимости от знака сдваиваемых бит. Именно, если ai ≠ 0, то узел сдваивания выбирает и сохраняет бит со знаком ai, если ai = 0 и aj ≠ 0, то в узле выбирается и сохраняется aj, если ai = 0 и aj = 0, то выбирается и сохраняется 0. Алгоритм заканчивает работу на шаге первого соединения в узле сдваивания значения 0 старшего разряда (разряда с индексом n) с битовым значением
подразумевает выбор и сохранение знака в зависимости от знака сдваиваемых бит. Именно, если ai ≠ 0, то узел сдваивания выбирает и сохраняет бит со знаком ai, если ai = 0 и aj ≠ 0, то в узле выбирается и сохраняется aj, если ai = 0 и aj = 0, то выбирается и сохраняется 0. Алгоритм заканчивает работу на шаге первого соединения в узле сдваивания значения 0 старшего разряда (разряда с индексом n) с битовым значением 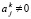 . После останова алгоритм перемещает
. После останова алгоритм перемещает 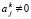 обратно вдоль пути нуля старшего разряда. В результате в разряде с индексом n на входе схемы окажется искомое значение знака старшего ненулевого разряда. Временная сложность алгоритма определяется числом последовательных шагов:
обратно вдоль пути нуля старшего разряда. В результате в разряде с индексом n на входе схемы окажется искомое значение знака старшего ненулевого разряда. Временная сложность алгоритма определяется числом последовательных шагов:
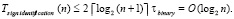 (7)
(7)
Необходимое дополнение заключается в том, что аналогичным способом можно поразрядно-параллельно выделить все совпадающие фрагменты двух строк. Именно, на первом шаге поразрядно-параллельного вертикального сложения CBj двоичных кодов строк пары совпадающих фрагментов дают в  цепочки подряд расположенных нулей. Количество нулей цепочки равно числу бит совпавшего фрагмента, расположение цепочек соответствует расположению совпавших фрагментов.
цепочки подряд расположенных нулей. Количество нулей цепочки равно числу бит совпавшего фрагмента, расположение цепочек соответствует расположению совпавших фрагментов.
Каждая отдельная цепочка нулей может быть идентифицирована с использованием схемы сдваивания, аналогичной представленной на рис 1. Для пояснения можно привести простой пример: выделяются совпадающие фрагменты слов 'КИТ' и 'КОТ'. Двоичный код сравниваемых слов:

В результате шагов (3)–(4) получится

Цепочки нулей в  дают совпадение фрагментов слов.
дают совпадение фрагментов слов.
С некоторыми оговорками, оценка временной сложности идентификации совпадающих фрагментов двух (n + 1)-разрядных слов примет вид
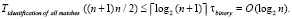
Возросшее по сравнению с (7) количество элементов R = (n + 1)n/2 объясняется тем, что аналог схемы на рис. 1 строится для каждого разряда сравниваемых слов. Алгоритм аналога отличается тем, что сдваивание начинается от нулевого разряда, слева от которого ненулевой разряд, так же как схема на рис. 1 начинается от старшего разряда.
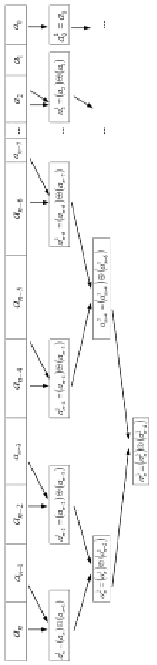
Рис. 1. Схема сдваивания для идентификации знака старшего ненулевого разряда
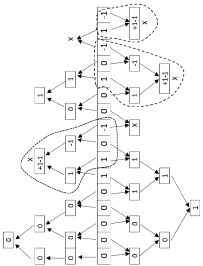
Рис. 2. Схема перевода знакоразрядного кода двоичной суммы в прямой код
В 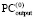 цепочки единиц будут означать все не совпадающие фрагменты слов, в примере – несовпадающие части кодов символов 'И' и 'О'.
цепочки единиц будут означать все не совпадающие фрагменты слов, в примере – несовпадающие части кодов символов 'И' и 'О'.
Развитие данных алгоритмов приводит к алгоритму параллельного сложения, использование которого позволяет всю входную и выходную информацию для арифметических операций представлять в дополнительном коде, без использования знаков в значениях разрядов.
Построение параллельного сумматора двоичных чисел
Пусть дана пара целых двоичных полиномов (1) и пусть над ними выполнены преобразования (2)–(5). В результате сумма получится в знакоразрядном двоичном коде, которую можно, как показано ниже, преобразовать в прямой двоичный код. Искомое преобразование удобно пояснить на примере.
Пример 1.

Над двухрядной суммой выполняется описанное ранее преобразование 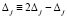 ,
, 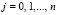 , значения разрядов
, значения разрядов  и
и  примут вид
примут вид

Взаимно независимое суммирование разрядных срезов по вертикали влечет
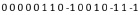 (8)
(8)
Полученный в знакоразрядном коде результат представляет сумму двух чисел. Она получается с единичным порядком временной сложности (за фиксированное конечное число шагов, не зависящее от числа разрядов слагаемых). Чтобы представить эту сумму в прямом двоичном коде, нужно преобразовать каждую комбинацию вида 2m+1 – 1 к виду 2m+1 – 1 = 2m + 2m-1 + 2m-2 +???+ 21 + 20, или, в позиционной системе, комбинацию вида 100...0 – 1 к виду 011...11. Алгоритм иллюстрирует схема, данная для примера 1, затем будут сделаны обобщающие пояснения. Следующая схема переводит код (9) в прямой двоичный код.
Поскольку все комбинации вида 100...0 – 1 взаимно отделены друг от друга (преобразование (2)–(4)) вследствие первого вертикального шага сложения промежуточной парой вертикальных нулей, то все такие комбинации взаимно независимы и могут быть преобразованы в прямой код параллельно. Именно так работают обведенные пунктиром фрагменты схемы преобразования на рис. 2. Алгоритм работы каждого фрагмента такой схемы инвариантен относительно вида и расположения преобразуемой комбинации двоичных цифр, он заключается в следующем. Делается общая для всех разрядов схема сдваивания, которая начинается с младшего разряда справа и отображается сверху вниз. Такая же схема, отображенная вверх, делается для всех разрядов, начиная со следующего после младшего разряда (со сдвигом на единицу влево предыдущей – нижней схемы). В схеме сдваивания допускается перемещение –1 только справа налево. Дерево, в котором она должна идти слева направо, блокируется на первом шаге запрещенного направления. Такая –1 пойдет справа налево, однако по параллельно работающей схеме, изображенной на рис. 2, симметричным отражением вверх со сдвигом на один разряд. В верхней схеме, так же как и в нижней, блокируется создание шагов сдваивания для всех –1, идущих слева направо. В разрешенной схеме (в поддереве) шаги сдваивания выполняются до получения корня поддерева, в котором зафиксируется комбинация +1, –1. Такая комбинация прекращает движение по поддереву и начинает в нем движение в обратном направлении. Обратное движение выполняется снизу вверх в нижнем фрагменте, сверху вниз – в верхнем. При этом –1 из корня поддерева параллельно по всем уровням поддерева, в котором она проходила путь, заменяет все элементы этого поддерева до начальных элементов включительно значением +1, за исключением элементов пути, уже занятых +1. С другой стороны, +1 из корня того же поддерева проделывает обратный путь вдоль своего ранее проделанного движения, заменяя на своем пути все пройденные элементы поддерева до начальных элементов включительно с +1на 0. В результате, путем замены исходной комбинации 100...0 – 1, в разрядной сетке суммы образуется искомая комбинация начальных элементов: 011...11.
Обратное перемещение двоичных коэффициентов от корня поддерева к исходным разрядным значениям можно реализовать многими способами. Для определенности условно подразумевается следующий способ. Все элементы всех поддеревьев (обоих деревьев – верхнего и нижнего) продублированы. Дублирующие элементы инициируется по мере прохождения сигнала по дублируемому элементу в прямом направлении, но открывают свой выход только в обратном направлении. Сигнал в обратном направлении передается только по дублирующим элементам. Изложенные преобразования выполняются одновременно во всех поддеревьях нижней схемы. Такие же преобразования выполняются одновременно во всех поддеревьях верхней схемы. Поскольку переносы не пересекаются, и все такие поддеревья верхней и нижней схемы взаимно отделены, на выходе алгоритма в разрядной сетке образуются полностью положительная сумма в двоичной форме. В каждом поддереве, не имеющем в корне комбинации +1, –1, по определению исключается движение в обратном направлении, и его входная комбинация двоичных цифр в разрядной сетке не меняется. В результате выполненного преобразования знакоразрядного кода (9) получится искомый прямой код суммы:
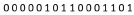
Замечание 1. Изложенный перевод гарантирован для исходного способа сложения, априори взаимно отделяющего все переносы друг от друга парой вертикальных нулей после шага (4). В общем случае, без наличия взаимной отделенности переносов, перевести знакоразрядный код в прямой по предложенной схеме нельзя.
Замечание 2. С использованием описанной схемы параллельного сложения двоичных полиномов входные и выходные данные для арифметических операций окажется возможным представлять в дополнительном коде, без использования знаков в битовых значениях разрядов. Однако для этого необходимо устранить существенное затруднение. Именно после перевода по схеме на рис. 2 комбинаций вида 100...0 – 1 в комбинации вида 011...11 одна комбинация с отрицательной единицей может остаться не преобразованной. Это произойдет в том случае, если старший ненулевой разряд суммы окажется отрицательным, например если комбинация старших разрядов имеет вид 000...0 – 1. В этом случае отрицательную единицу нельзя обработать по предложенной схеме. Кроме того знак «–» нельзя закодировать, поскольку это не только знак суммы, но и знак одного значения разряда конкретно определенного веса (веса старшего ненулевого разряда). Можно различными способами пытаться разрешить это затруднение. Одно из простейших решений заключается в следующем.
Вариант 1. На выходе сложения отрицательная единица, если она появляется, окажется единственной. Ее можно отделить со своим разрядным весом в качестве дополнительного слагаемого (оно отрицательно, состоит из единственного ненулевого разряда). Такое отрицательное слагаемое ничто не мешает представить в обратном коде. В результате можно завершить сложение с использованием того же способа разрядного распараллеливания. Как нетрудно видеть, преобразованная мантисса не будет содержать отрицательных разрядов.
Вариант 2. Еще один способ формально не использует представление данных в дополнительном коде. После вычленения –1 в отдельное слагаемое в разряд этого слагаемого с индексом n + 1 записывается значение +1. Получается комбинация вида 2n+1 – 2m = 2n + 2n-1 + 2n-2 +???+ 2m+1 + 2m, где m – индекс разряда, содержащего неустраненное значение –1. Тогда все разряды в правой части тождества могут заменить все нулевые старшие разряды, а также разряд с –1, на цепочку из n – m + 1 положительных единиц. Чтобы значение окончательного результата оказалось правильным, достаточно вычесть добавленную +1 из разряда с индексом n + 1. Получается, что –1 в разряде с индексом n + 1 и цепочка из +1 в разрядах с индексами n, n – 1,..., m + 1, m эквивалентна исходному значению –1 старшего ненулевого разряда с индексом m. Эту комбинацию можно возвратить в исходный результат сложения. В окончательном коде –1 в разряде с индексом n + 1 может использоваться в качестве идентификатора знака результата, в то же время это именно значение разряда данного веса. Во всех разрядах с меньшими номерами отрицательных значений не останется. Более точно, преобразование сводится к следующему правилу. При наличии –1 в старшем ненулевом разряде с индексом m ≤ n этот разряд и все слева от него разряды, до разряда с индексом n включительно, следует заменить на значения +1, а в разряд с индексом n + 1 записать значение –1. Если старший ненулевой разряд априори имел индекс m = n + 1 и был при этом равен –1, то разряд с индексом n + 1 не преобразуется и полученный код считается окончательным кодом суммы полиномов вида (1). Чтобы фактически не выполнять лишних операций, можно –1 старшего ненулевого разряда вычленить в отдельный ряд вместе с нулевыми старшими разрядами. Весь отрезок ряда слева, начиная с –1, параллельно заменяется значениями разрядов +1. Одновременно в разряд с индексом n + 1 записывается значение –1. Справа от исходного значения –1 остаются нули. Полученный ряд параллельно складывается с исходным рядом, из которого была вычленена отрицательная единица. Реализация каждого такого шага требует аппаратной поддержки и влечет соответственную задержку, которая имеет единичное значение, тогда как предшествующие преобразования измерялись логарифмическим числом шагов.
Вариант 3. Еще один способ заключается в том, что результат преобразования, описанный в варианте 2, можно получить на этапе работы схемы на рис. 2 с помощью незначительной модификации поддерева старших разрядов этой схемы. Именно, если в разряде с индексом n + 1 априори находилось значение +1, поддерево схемы сдваивания, включающее этот разряд, работает без изменения, как изложено при описании схемы на рис. 2. Если же в разряде с индексом n + 1 априори находилось значение 0, то вместо этого значения на вход поддерева схемы подается +1. Работа этого поддерева строится по общему правилу. Единственное исключение состоит в том, что в конце перемещения в обратном от корня направлении априорное значение 0 в разряде с индексом n + 1 заменяется значением –1. В результате исходная комбинация старших разрядов 000...0 – 1 в разрядной сетке суммы заменится на искомую комбинацию –111...11, где –1 является значением разряда с индексом n + 1.
Замечание 3. С модификацией варианта 3 время работы схемы сдваивания не изменится. Этот вариант наряду со способом сложения двоичных полиномов одновременно дает знак сравнения слов строкового, а также числового типа, представленных в двоичном коде.
Описание схемы выходит за рамки примера 1, с учетом замечаний 1–3 и вариантов 1–3 оно инвариантно относительно разрядности, входного кода слагаемых, наличия и вида преобразуемых комбинаций.
Оценка временной и схемной сложности параллельного сумматора
С выбором варианта 3 временная сложность предложенного алгоритма параллельного сложения чисел вида (1) будет иметь логарифмическую от числа разрядов оценку. В самом деле, число последовательных шагов в направлении корня в поддереве схемы сдваивания не превосходит 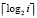 , где i – количество входных разрядов, преобразуемых в поддереве. Число шагов в обратном направлении не превосходит того же значения. Все поддеревья схемы выполняют преобразования параллельно. Таким образом, временная сложность преобразования одновременно всех разрядов оценивается из соотношения
, где i – количество входных разрядов, преобразуемых в поддереве. Число шагов в обратном направлении не превосходит того же значения. Все поддеревья схемы выполняют преобразования параллельно. Таким образом, временная сложность преобразования одновременно всех разрядов оценивается из соотношения 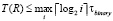 , или,
, или, 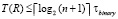 . Количество элементов сумматора R не превзойдет значения пропорционального n + 1. Именно в поддереве нижней схемы количество сдваиваемых элементов Ri, рассматриваемых по уровням от корня, составит
. Количество элементов сумматора R не превзойдет значения пропорционального n + 1. Именно в поддереве нижней схемы количество сдваиваемых элементов Ri, рассматриваемых по уровням от корня, составит 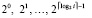 , где i – количество разрядов, преобразуемых в поддереве. Отсюда
, где i – количество разрядов, преобразуемых в поддереве. Отсюда 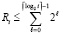 , или,
, или, 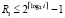 . В результате
. В результате 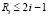 . Поскольку комбинации преобразуемых входных элементов не пересекаются в (n + 1)-разрядной сетке, то суммарное число элементов поддеревьев не превысит суммы тех значений i разрядов, множество которых покроет разрядную сетку. В итоге
. Поскольку комбинации преобразуемых входных элементов не пересекаются в (n + 1)-разрядной сетке, то суммарное число элементов поддеревьев не превысит суммы тех значений i разрядов, множество которых покроет разрядную сетку. В итоге 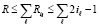 , где
, где 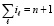 . Тогда
. Тогда 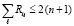 . Это количество элементов нижней схемы удвоится с учетом предположения о дублирующих элементах. Аналогично оценивается число элементов верхней схемы. Отсюда общее число элементов R ≤ 8(n + 1). Если теперь принять во внимание, что предварительные шаги (2)–(5) выполняются на O(n + 1) элементах за время T(n) = O(1), то общая окончательная оценка временной сложности и числа элементов всего параллельного сумматора может быть представлена в виде:
. Это количество элементов нижней схемы удвоится с учетом предположения о дублирующих элементах. Аналогично оценивается число элементов верхней схемы. Отсюда общее число элементов R ≤ 8(n + 1). Если теперь принять во внимание, что предварительные шаги (2)–(5) выполняются на O(n + 1) элементах за время T(n) = O(1), то общая окончательная оценка временной сложности и числа элементов всего параллельного сумматора может быть представлена в виде:
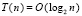 . (9)
. (9)
Оценка (10) может быть получена путем непосредственного подсчета последовательных шагов общей схемы сдваивания, 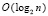 , а также подсчетом числа элементов этой общей схемы, O(n), поскольку оценивавшиеся поддеревья вырезались из конфигурации общей схемы и не меняли количество ее элементов.
, а также подсчетом числа элементов этой общей схемы, O(n), поскольку оценивавшиеся поддеревья вырезались из конфигурации общей схемы и не меняли количество ее элементов.
Общий результат можно представить в следующей формулировке.
Предложение 1. На основе описанных выше схем алгебраическое сложение двоичных полиномов вида (1) может быть выполнено с временной сложностью (10). С такой же оценкой может быть выполнено сравнение слов строкового и числового типа, представленных в (n + 1)-разрядном двоичном коде.
Представленная алгоритмическая схема сложения двоичных полиномов отличается от известных схем [5, 6], а также от [15] по структуре и тем, что относится к полному количеству разрядов слагаемых (1), достигая оценки (10). Преимущество обеспечивает использование предварительного шага параллельного по вертикальным срезам сложения слагаемых вида (1), что отсутствует в схемах, с которыми проводилось сравнение.
Области применения
Предложенные схемы могут найти применение при разработке систем информационного поиска. В основу выполнения операций сравнения могут быть положены сравнения с маской, которая состоит из символов на выделенных позициях слова, сравнения можно распространить на конечное множество масок данного вида. При этом в предложенных схемах рассматриваемые операции могут распараллеливаться по разрядам всего множества слов исследуемых данных, представленных в векторизованной форме. Формально подход можно отнести не только к словам строкового типа, но с оговорками относительно ограничений технологического, технического, програм- много и структурного характера его можно распространить на различные объекты, представленные в двоичном коде. С использованием способов, описанных в [11], предложенные схемы применимы для ускоренного по сравнению с последовательными методами [7–9] построения и обработки древовидных структур данных. Предложенные схемы дают эквивалентное преобразование двоичных арифметических операций, позволяющее достигать ускорения относительно известных схем суммирования [6, 15] за счет максимального разрядного распараллеливания.
Заключение
Изложен способ разрядного распараллеливания операций сравнения строк и сложения двоичных полиномов. Способ отличается исключением вычисления переноса, поэтому не использует требуемые для выполнения переноса логические схемы. На этой основе могут максимально параллельно реализоваться базовые операции поиска, включая сравнение и сортировку. По структуре, временной сложности и аппаратным затратам предложенный способ улучшает известные схемы разрядного распараллеливания арифметических операций, а также схемы базовых операций поиска. Структура предложенных алгоритмов разрядного распараллеливания делает возможным их применение для повышения точности вычислительных операций за счет удлинения разрядной сетки представления операндов и сокращения потерь значащих цифр в операциях с плавающей точкой.
Библиографическая ссылка
Ромм Я.Е., Белоконова С.С. МЕТОД ТОЧНОГО ИНФОРМАЦИОННОГО ПОИСКА НА ОСНОВЕ РАЗРЯДНОГО РАСПАРАЛЛЕЛИВАНИЯ // Современные наукоемкие технологии. 2019. № 7. С. 90-98;URL: https://top-technologies.ru/ru/article/view?id=37595 (дата обращения: 03.07.2026).