



Существует ряд приложений, которым особенно полезно прогнозирование деятельности человека. Это может быть приложение в фитнес-трекерах (например, оценка сжигаемых калорий, рекомендации, предупреждения и т.д.). Кроме того, способность распознавать отдельных пользователей может повысить безопасность и удобство устройства, отправив предупреждение, если несанкционированный пользователь несет телефон или остался незапертым, если авторизованный пользователь несет устройство. Растущее распространение, а также разнообразие датчиков для контроллеров Android открывает новые возможности для сбора и анализа непрерывных данных для них. Информация для интеллектуального анализа данных с камер, микрофонов, акселерометров и других сложных датчиков может обеспечить полезную обратную связь, информирующую о повседневной деятельности пользователя.
В этой статье описываются новые возможности применения алгоритмов машинного обучения, которые нацелены на классификацию физических действий пользователя, таких как ходьба, сидение и стояние на месте и т.д., основанные на данных акселерометра GY-521.
Цель исследования: прогноз по идентификации деятельности человека с помощью акселерометра GY-521 на базе нейросетевого подхода, который особенно эффективен в задачах экспертной оценки, так как он сочетает в себе способность компьютера к вычислению и способность к распознаванию и, соответственно, обобщению. Для кода был использован Python.
Материалы и методы исследования
В данной предметной области подобные исследования проводились достаточно давно. Однако методы 1970–1980-х гг. включают специализированные устройства, которые не являлись мобильными устройствами. Эти устройства (например, FitBit) являются дорогостоящими и представляют собой достаточно крупный объект, в последующем активно стали использовать появившиеся в то время компактные устройства общего назначения, такие как телефоны, планшеты и другие подобные гаджеты. Кроме того, в настоящее время существуют разработки использования HAR на основе изображений, как альтернативная возможность классификации человеческих движений [1]. Например, были разработаны алгоритмы распознавания движения человека в монокулярных видеопоследовательностях на основе дискриминантных условных случайных полей (CRF) и максимальных энтропийных марковских моделей (MEMM) [2]. Тем не менее системы на основе зрения имеют проблемы с установкой камеры, освещением, качеством изображения, конфиденциальностью и т.д. Для повседневной жизни пользователю нужны компактные, износостойкие и недорогие системы, которые благодаря развитию технологий появились совсем недавно. В исследованиях W. Ugulino проводился сбор данных о движении человека на 4 акселерометрах ADXL335, использовали дерево C4.5, дихотомизер 3 (ID3) и AdaBoost для классификации человеческих движений и получили отличные результаты по отзыву и точности [3]. В нашем проекте используется тот же набор данных, но другая система моделей, которая позволяет выбрать наиболее эффективную классификацию.
Данные для нашего проекта общедоступны в репозитории машинного обучения UCI. Доступ к нему можно получить по адресу: http://groupware.les.inf.puc-rio.br/har#dataset. Набор данных содержит следующие характеристики: возраст, вес, индекс массы тела, высота x, y, показания оси z из 4 различных акселерометров.
Сбор данных от датчиков обеспечивался удалённым доступом к сценарию и данным на ноутбуке с MATLAB (MathWorks Cloud). Пакет поддержки MATLAB для датчиков выполнял отображение, регистрацию, запрос и отправку данных. В итоге выводились неподготовленные данные с датчиков акселерации GY-521 при 50 Гц частоте дискретизации от 48 волонтёров. Плата с GY-521 была закреплена в трех позициях: на поясе, левом бедре и правом плече. Показания акселерометра включают сигналы ускорения и положения в осях x, y и z. Набор данных также включал имя пользователя, пол, возраст, рост, вес и индекс массы тела. Однако эти функции менее актуальны для нашей задачи, поэтому они не были включены в качестве актуальных входных данных. Исходные данные последовательно выбирались из акселерометров, поэтому данные были рандомизированы перед обучением и тестированием. В репозитории находилось в общей сложности около 200 тыс. проб, в которых было использовано 120 000 в качестве учебных данных, 60 000 – в качестве тестовых данных. Остальные данные представлялись в качестве дополнительного набора тестов, для того чтобы избежать переопределения параметра C в методе опорных векторов SVM.
После использования Zscore самые незначительные значения ошибок в обучении и тестировании были в пределах 2 %. Поскольку полученные ошибки в обучении и тестировании были невелики, но при этом все же выше, чем требовала текущая производительность, то был увеличен параметр C.
Датчик GY-521 с акселерометром MPU-6050
Данный датчик используется в проектах, где необходимо определение положения в пространстве, стабилизация положения, движения и заданное движение по кривым.
При подключении к контроллеру у датчика GY-521 имеется шина I2C.
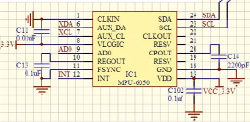

Рис. 1. Схема подключения MPU-6050
Рис. 2. GY-521 с шиной I2C и Arduino Mini
Визуализация данных. Чтобы получить представление о структуре наших данных и лучше понять различия между категориями нашего набора данных, были реализованы два известных алгоритма: анализ главных компонент (PCA) и анализ внедрения стохастических соседей (t-SNE). На рис. 3 показана проекция нашего набора данных на двумерную плоскость с использованием первых двух главных компонент, полученных PCA.
Данные включают сигналы ускорения в различных положениях тела, в трёх направлениях. Таким образом, функции находятся в разных масштабах. Чтобы сделать значения объектов сопоставимыми, использовали два метода масштабирования для обработки данных для разных видов активности человека.
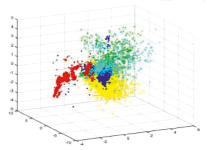
Рис. 3. PCA визуализация данных Zscore
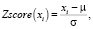
где μ и σ – это среднее и стандартное отклонения данных x.
Рис. 4. Временные ряды
Настройка нейросети. Для получения прогноза HAR была использована 3-слойная полносвязная нейронная архитектура. На вход сети генерируются 24 значения от датчиков, при этом скрытый слой после попыток анализа стал содержать 36 нейронов, а на выходе были получены 6 прогнозных значений HAR.
Модели. Исходные данные по своей природе являются временными рядами, однако из-за сложности такого типа данных было решено начинать с методов, которые предполагают независимость обучающих данных. Таким образом, модели получили необработанные данные датчиков на каждом временном шаге и в дальнейшем прогнозировали семантические метки.
Как показано в визуализации с использованием PCA, исходные данные, очевидно, нелинейно разделимы, соответственно, были выбраны следующие нелинейные алгоритмы машинного контролируемого обучения алгоритмов, для тестирования моделей на нашей выборке:
Метод k ближайших соседей (k-Nearest Neighbors)
Наивный байесовский классификатор (Naive Bayes)
Деревья классификации и регрессии (Classification and Regression Trees, CART)
Метод опорных векторов (Support Vector Machines) [4].
Оптимизация результата алгоритмов с помощью ансамблей. Ансамбли алгоритмов позволяют значительно увеличить производительность наших моделей на базе библиотеки scikitlearn. В исследовании был выбран ансамблевый метод бустинга AdaBoost и стохастический градиентный спуск (англ. stochastic gradient boosting). Методом бустинга создаётся последовательность моделей машинного обучения, каждая из которых учитывает ошибки предыдущей модели. Стохастический градиентный спуск относится к оптимизационным алгоритмам и нередко используется для настройки параметров модели машинного обучения.
Результаты исследования и их обсуждение
Перед этапом выбора метода машинного обучения необходимо было настроить два ключевых параметра алгоритма SVM: значение C (для ослабления поля) и тип ядра. Значение по умолчанию для SVM (класс SVC) заключается в использовании ядра Radial Basis Function (RBF) с значением C, установленным в 1.0. Как и в случае с KNN, был выполнен поиск по сетке с использованием 10-кратной проверки перекрёстных ссылок со стандартизованной копией набора учебных материалов. Кроме того были использованы несколько более простых типов ядер и значений C с меньшим уклоном и большим смещением (меньше и больше 1.0 соответственно).
# Tune scaled SVM
c_values = [0.7, 0.1, 0.1, 0.6, 0.9, 1.1, 1.2, 1.7, 1.9, 2.0]
kernel_values = ['linear', 'poly', 'rbf', 'sigmoid']
param_grid = dict(C=c_values, kernel=kernel_values)
model = SVC()
kfold = KFold(n_splits=num_folds, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(rescaledX, Y_train)
В итоге исследований эффективности был выбран метод, который отображал наилучшую конфигурацию и точность. В целом не было удивительным, что наиболее точной конфигурацией стал SVM с ядром RBF и значением C = 1,5. Точность 97,1470 %, по-видимому, лучшее, чего может достичь SVM.
Наш набор данных содержит примерно равное количество наблюдений для каждого из шести видов деятельности. Кроме того, конкретные приложения идентификации активности могли потребовать, чтобы один или несколько видов деятельности были более точно классифицированы, чем другие, учитывая это, было решено взвешивать каждый вид деятельности на одинаковых метриках.
В результате была использована общая точность классификации тестовых данных в качестве основной метрики производительности. Ниже показаны ошибки обучения и тестирования для каждого из анализов.
Таблица 1
Ошибки классификации алгоритмов машинного обучения (АМО)
|
АМО |
Доля ошибок обучения |
Доля ошибок тестирования |
|
K-NN |
0,91 % |
4,02 % |
|
Naive Bayes |
0,30 % |
3,91 % |
|
CART |
0,00 % |
5,07 % |
|
SVM |
0,42 % |
3,71 % |
Модели, представленные в таблице показывают похожую производительность, за исключением деревьев с повышенным градиентом, которые имели более высокую степень ошибочной классификации в тестах. В целом сходство тестовых ошибок говорит о том, что увеличение сложности модели не обязательно улучшает её производительность и эффективность. При этом модели Naive Bayes и SVM работали немного лучше, чем деревья и K-NN. Из визуализаций проецируемых данных можно ожидать, что подходящие модели с линейными границами будут хорошо работать при разделении кластеров, даже если данные не полностью разделимы. Одной из причин может быть то, что данные не могут быть полностью разделены, даже при проецировании в более высоких измерениях. Во-вторых, модели, реализующие линейные границы, менее склонны к переобучению, чем такие модели, как SVM с радиальным ядром или полиномиальным ядром и деревья с градиентным ускорением, и, следовательно, способны лучше обобщать результаты. В частности, градиентные деревья имели погрешность обучения 0 %, что говорит о том, что модель была перегружена обучающими данными, несмотря на усилия по регуляризации модели, путём настройки скорости обучения, количества итераций и размера дерева.
Модель SVM имеет в больших данных низкую скорость классификации, однако, с другой стороны, является вычислительно эффективной для машинного обучения, в итоге было решено дополнительно продиагностировать ее производительность [5]. С целью выбора признаков была применена модель PCA и выполнен эксперимент с обучением модели на различных кортежах главных компонент. Наилучший результат был получен с использованием первых 30 главных компонентов, это дало ту же производительность, что и простое применение линейного ядра SVM к исходным данным. Затем были проанализированы параметры обучения и тестовые ошибки для четырёх моделей, постоянно изменяя в течении эксперимента размер примеров в обучающих данных [6]. Результаты показаны на рис. 5.
Из графика исключили байесовский классификатор, который был слишком вариативным. У остальных моделей не было проблем со смещением или дисперсией. Затем, чтобы проверить точность в классификации каждого вида деятельности, была вычислена матрица ошибок при обучении и тестировании на полных тренировочных и тестовых данных.
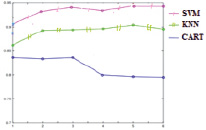
Рис. 5. Точность классификации для K-NN, CART, SVM
В матрице ошибок (табл. 2) для SVM чаще наблюдалась неправильно классифицируемая активность в положении «сидеть» и имела показатель ошибочной классификации 10,7 %, при этом почти все ошибки неправильно идентифицируются для состояния «стоять». Как и ожидалось, динамическое окно часто ошибочно перекрывается статическим. Кроме того, неверные классификации в основном происходили во время перехода от режима стояния к сидению.
Таблица 2
Матрица ошибок
Предикаты
|
Тестовые данные |
Вверх по лестнице – WU |
Вниз по лестнице – WD |
Прогулка – W |
Стоять на месте – St |
Сидеть – Sit |
Ложиться – Lay |
|
|
WU |
409 |
0 |
14 |
0 |
0 |
0 |
|
|
WD |
0 |
364 |
5 |
0 |
2 |
0 |
|
|
W |
0 |
0 |
441 |
0 |
0 |
0 |
|
|
St |
0 |
0 |
0 |
462 |
16 |
0 |
|
|
Sit |
1 |
0 |
1 |
51 |
383 |
0 |
|
|
Lay |
0 |
0 |
0 |
0 |
0 |
494 |
Затем была выполнена перекрёстная проверка, где была обучена модель на 48 пользователях и протестирована на наблюдениях за 30 пользователями. Как и ожидалось, уровень ошибок классификации пользователей между «стоять» и «сидеть» значительно колебался в пределах от 0,0 % до 18,2 %. Особые проблемы доставляла проверка вариативности между испытуемыми в рамках каждого действия.
Из матрицы ошибок можно заключить, что наш алгоритм обучения хорошо классифицирует большинство помеченных действий. Наихудшие два класса производительности – St и Sit имеют все же хороший положительный показатель 81 % и 91 %. Все остальные классы имеют положительные показатели, превышающие 95 %. Ошибки все понятны, потому как эти действия похожи с точки зрения датчиков, при этом сидение и стояние, ходьба и неподвижность, подъем и спуск труднее отфильтровать друг от друга. Это также может быть вызвано тем, что было выполнено подряд несколько действий, а при выборке данных отмечали в итоге только метку одного действия.
Выводы
В этой работе была исследована методика распознавания деятельности людей HAR, используя данные гироскопа и акселерометра GY-521, были применены различные методы машинного обучения для решения задачи многомерной классификации путём поиска временной связанности, завуалированной в наборе данных.
Была проведена работа на извлечение объектов, их выборке и методах классификации в изучаемой проблеме распознавания активности человека. После проведения экспериментов на реальных данных датчиков полученные результаты показали эффективность выбранных нами методов. Результаты вошли в доверенный диапазон и достигли точности 97,41 % в случае трёх датчиков для метода SVM. Значение ошибки, при оценке временных рядов, составило около 2 %, что показывает адекватность нашей разработанной нейромодели прогнозирования. Эффективность методов показывает, что можно уверенно прогнозировать активность человека с помощью 3 акселерометров на базе компактных устройств типа GY-521 для контроллера Ардуино.
Библиографическая ссылка
Горяев В.М., Джахнаева Е.Н., Лиджи-Горяев В.В., Аль-Килани В.Х. КЛАССИФИКАЦИЯ ДАННЫХ АКСЕЛЕРОМЕТРА GY-521 ДЛЯ РАСПОЗНАВАНИЯ АКТИВНОСТИ ЧЕЛОВЕКА // Современные наукоемкие технологии. 2018. № 12-1. С. 56-61;URL: https://top-technologies.ru/ru/article/view?id=37262 (дата обращения: 14.07.2026).